
SQL Server 2022 improved the STRING_SPLIT function so that it can now return lists that are guaranteed to be in order. However, that’s the only thing they improved – there’s still a critical performance problem with it.
Let’s take the Stack Overflow database, Users table, put in an index on Location, and then test a couple of queries that use STRING_SPLIT to parse a parameter that’s an incoming list of locations:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE INDEX Location ON dbo.Users(Location); SET STATISTICS IO ON; GO CREATE OR ALTER PROC dbo.usp_GetUsersByLocation_Subquery @LocationList NVARCHAR(4000) AS SELECT TOP 1000 u.* FROM dbo.Users u WHERE u.Location IN (SELECT value FROM STRING_SPLIT(@LocationList, N',', 1)) ORDER BY u.Reputation DESC; GO CREATE OR ALTER PROC dbo.usp_GetUsersByLocation_Join @LocationList NVARCHAR(4000) AS SELECT TOP 1000 u.* FROM STRING_SPLIT(@LocationList, N',', 1) l INNER JOIN dbo.Users u ON l.value = u.Location ORDER BY u.Reputation DESC; GO EXEC usp_GetUsersByLocation_Subquery N'India,China'; EXEC usp_GetUsersByLocation_Join N'India,China'; |
The two queries produce slightly different actual execution plans, but the way STRING_SPLIT behaves is the same in both, so I’m just going to take the first query to use as an illustration:

That red-highlighted part has two problems:
- SQL Server has no idea how many rows are going to come out of the string, so it hard-codes a guesstimate of 50 items
- SQL Server has no idea what the contents of those rows will be, either – it doesn’t know if the locations are India, China, or Hafnarfjörður
As a result, everything else in the query plan is doomed. The estimates are all garbage. SQL Server will choose the wrong indexes, process the wrong tables first, make the wrong parallelism decisions, be completely wrong about memory grants, you name it.
Like I wrote in this week’s post about DATETRUNC, that doesn’t make STRING_SPLIT a bad tool. It’s a perfectly fine tool if you need to parse a string into a list of values – but don’t use it in a WHERE clause, so to speak. Don’t rely on it to perform well as part of a larger query that involves joins to other tables.
Working around STRING_SPLIT’s problems
One potential fix is to dump the contents of the string into a temp table first:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE OR ALTER PROC dbo.usp_GetUsersByLocation_TempTable @LocationList NVARCHAR(4000) AS BEGIN SELECT value INTO #LocationList FROM STRING_SPLIT(@LocationList, N',', 1); SELECT TOP 1000 u.* FROM dbo.Users u WHERE u.Location IN (SELECT value FROM #LocationList) ORDER BY u.Reputation DESC; END GO EXEC usp_GetUsersByLocation_TempTable N'India,China'; |
And the actual execution plan is way better than the prior examples. You can see the full plan by clicking that link, but I’m just going to focus on the relevant STRING_SPLIT section and the index seek:
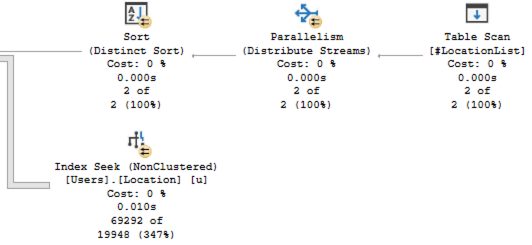
This plan is better because:
- SQL Server knows how many rows are in #LocationList
- Even better, it knows what those rows are, and that influences its estimate on the number of users who live in those locations, which means
- SQL Server makes better parallelism and memory grant decisions through the rest of the plan
Woohoo! Just remember that temp tables are like OPTION (RANDOM RECOMPILE), like I teach you in this Fundamentals of TempDB lecture.

2 Comments. Leave new
Heh… my boss says the same thing about DelimitedSplit8K. I keep asking him why he thinks that joining to a iTVF is a good idea.
It’s not just the STRING_SPLIT() function that has this issue. Joining to an iTVF is a “code smell” in my book. It reminds me of people that do WHERE clauses on aggregated columns on views and then they wonder why the code “runs slow”. 😀
And a “p.s.”. This is a great article in more ways than one. One of the most important things is this is proof, yet again, that “Set Based” does NOT mean “all in one query”. 😀 “Divide’n’Conquer” is a VERY effective performance tool and not just when it comes to functions and the like.