
Signs and Numbers
When tuning queries, or even finding queries to tune, there’s a rather misguided desire to look for queries with a high cost, or judge improvement by lowering query cost. The problem is that no matter what you’re looking at, costs are estimates, and often don’t reflect how long a query runs for or the actual work involved in processing the query.
You typically need to observe the query running and gather more precise metrics on what it’s really doing to judge things.
Good Example
I have these two indexes:
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX ix_users ON dbo.Users ( CreationDate, Reputation, Id ); GO CREATE INDEX ix_posts ON dbo.Posts ( OwnerUserId, Id ) INCLUDE ( PostTypeId ) WHERE PostTypeId = 1; GO |
And when I run this query, I would expect to use both of them to help the join/where clause, and then do a Key Lookup to get the columns not covered by my nonclustered index on users from the clustered index.
|
1 2 3 4 5 6 7 8 9 |
SELECT u.*, --Everything from Users p.Id AS PostId FROM dbo.Users AS u JOIN dbo.Posts AS p ON p.OwnerUserId = u.Id WHERE u.CreationDate > '20180401' AND u.Reputation > 100 AND p.PostTypeId = 1 ORDER BY u.Id; |
After all, there are only about 3000 rows in the Users table that qualify for my predicates, and that only turns into about 7300 rows when joined to Posts. That seems like one of those “no brainer” places to do a key lookup, but it doesn’t happen.

The metrics we get from stats time/io look like this (trimmed for brevity):
|
1 2 3 4 5 6 |
Table 'Posts'. Scan count 5, logical reads 36740 Table 'Users'. Scan count 5, logical reads 150649 Table 'Worktable'. Scan count 0, logical reads 0 SQL Server Execution Times: CPU time = 8172 ms, elapsed time = 4736 ms. |
So about 5 seconds of wall clock time, 8 seconds of CPU time, and 150k logical reads from Users.
If we hint our index, to make the optimizer choose it, we get the plan we’re after.
|
1 2 3 4 5 6 7 8 9 |
SELECT u.*, p.Id AS PostId FROM dbo.Users AS u WITH (INDEX = ix_Users) --TAKE A HINT JOIN dbo.Posts AS p ON p.OwnerUserId = u.Id WHERE u.CreationDate > '20180401' AND u.Reputation > 100 AND p.PostTypeId = 1 ORDER BY u.Id; |
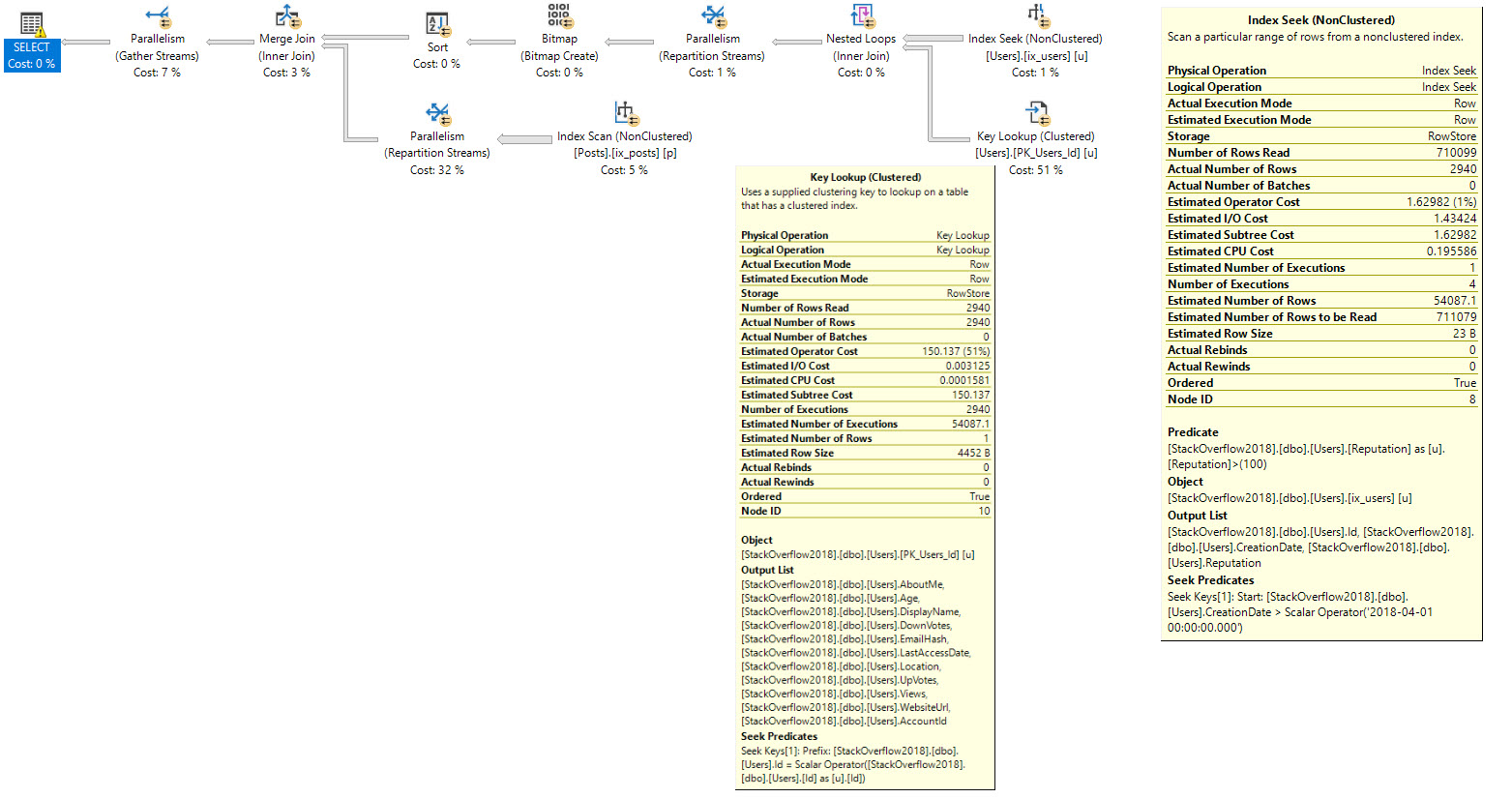
The metrics we get from stats time/io look like this (trimmed for brevity):
|
1 2 3 4 5 6 7 |
Table 'Users'. Scan count 5, logical reads 11076 Table 'Worktable'. Scan count 0, logical reads 0 Table 'Posts'. Scan count 5, logical reads 36964 Table 'Worktable'. Scan count 0, logical reads 0 SQL Server Execution Times: CPU time = 1187 ms, elapsed time = 780 ms. |
Interesting! We’re down to 780 milliseconds of wall clock time, about 1.1 seconds of CPU time, and what appears to be a lot fewer reads from the Users table.
This is clearly the faster plan, so what gives?
Scrooged
The much slower query has a lower cost!
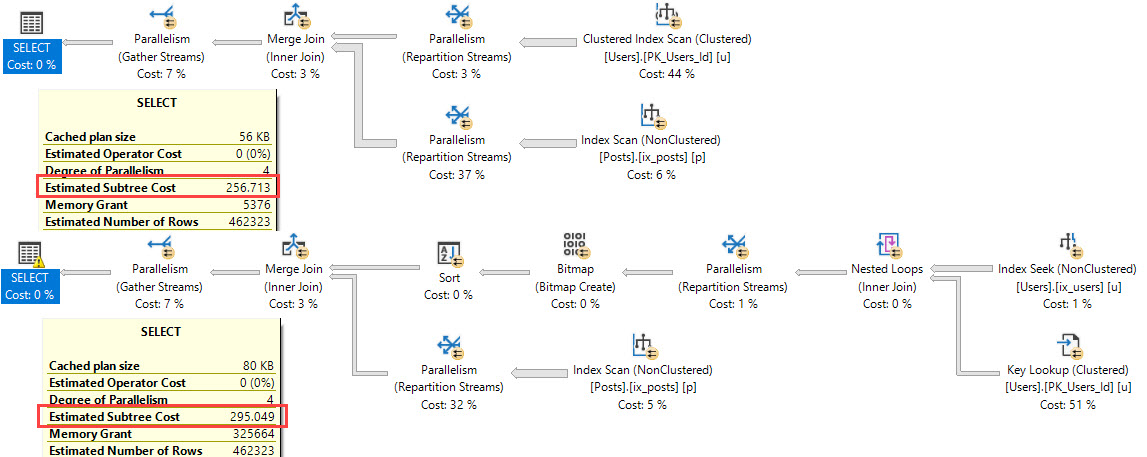
The optimizer associates a fairly high cost to the key lookup. This comes from two things:
- The optimizer assumes data comes from a cold buffer cache, meaning no data is in memory
- The optimizer hates I/O, especially random I/O
I’m gonna go out on a limb and say the costing algorithm still thinks about disks like they’re creaky old spinning rust, and that it’s not hip to SSDs. I don’t know this for a fact, and I’d love to hear otherwise. When you put it all together, you get a query plan that prefers to do one sequential scan of the clustered index because no data is in memory, and because doing a Key Lookup via random I/O, or even sorting data first would be more expensive.
Costs can be helpful to figure out why a certain plan was chosen, but they shouldn’t be used to judge what the best plan is.
Thanks for reading!
Brent says: in SQL Server’s defense, I bet most plan caches are chock full of beautiful query plans where the costs accurately reflect the amount of work involved. Say maybe 99.9% of your queries get perfectly crafted plans. Still, that’s 1 in 1,000 plans that go south, and those are the ones you’re typically focused on tuning. You’re tuning them because the estimates are wrong – and that’s why you don’t wanna put faith in those estimated cost numbers. If they were accurate, you probably wouldn’t be tuning ’em.

7 Comments. Leave new
Very interesting. Thanks Erik!
I LOVE this!!! Thanks!
We ran into something like this some time back with a parameter sniffing issue. Small clients would set the plan for a query that would be run by all sizes of clients. When a large client would then try to run, it would be really slow. We forced an index hint on it, resulting in a larger cost, but a faster overall time and the issue with “bad” query plans entering the cache was no longer an issue. (Back in the days when the only option was to clean the entire proc cache, of course)
Working with something like this now where putting in place a more efficient query, cost-wise, dramatically made the performance worse.
The idea that the query engine would optimise Scans over Key Lookups because of older hardware constraints is a great point. It makes me wonder if that is a thing, and if there are other hardware optimisations for what are now legacy purposes, and what performance gains could be achieved by a revision.
Erik,
I believe your assumption about creaky old disks is close but I don’t think that SQL Server cares about quality.
Kimberly Tripp teaches a great rule of thumb about predicting when NCIs will be used that relates rows and pages. It works because the optimizer assumes that I/O is performed as random I/O. It cares not if the read is from an SSD or an 8-inch 1mb floppy drive (although if the latter is part of your system you have bigger issues).
So… what should we judge a query by?
Great question! To learn the answer, check out my Fundamentals of Query Tuning course.