
The series so far:
As you learned in part one of this Mastering TempDB series, TempDB is a global resource used for many operations within SQL Server. You create and allocate temporary user objects such as temporary tables and table variables, rebuild indexes with SORT_IN_TEMPDB=ON, use it for version stores (RCSI), internal objects (worktables, spools, group by, order by) and even DBCC CHECKDB just to name a few. All these operations require space to be allocated in the TempDB database. At times, these operations can result in TempDB growing rapidly, which, in turn, can fill up the file system and cause failures. In this article, you will learn how to fix an overgrown TempDB file that has resulted in it running out of space.
Uncontrolled TempDB growth
There are many reasons for uncontrolled TempDB growth events. Much like your operating system has a page file to handle memory overflows, SQL Server uses TempDB like a page file. The most common occurrence of this is when a query “spills” to TempDB. When you execute a query, the database engine allocates memory to perform join and sort operations. The amount of memory allocated is based on the statistics associated with the columns and indexes. If the estimate is incorrect and the engine does not allocate enough memory, those joins and sorts will spill to disk—which consumes a lot of TempDB resources. Spilling is only one use of TempDB; some of the other ways SQL Server uses this database include storing large temporary tables. Temp tables can lead to uncontrolled growth if they are being populated by a query that needs to be tuned. You could have an Availability Group replica, which runs in snapshot isolation mode, go down, which causes the version store to fill up. You can have a normal workload cause TempDB to have an auto-growth that causes you to run out of drive space. There are countless explanations as to why TempDB can grow. The key administrative task is not only trying to get the drive space back and the system running, but also identifying the cause of the growth event to prevent recurrence.
As a reminder from the first article, you can easily peek inside your TempDB database to see what has caused the file to fill up. These great queries below provided in TempDB msdocs is a good place to start. Once you locate the culprit, you can tune accordingly to prevent the issue from reoccurring.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- Determining the amount of free space in tempdb SELECT SUM(unallocated_extent_page_count) AS [free pages], (SUM(unallocated_extent_page_count)*1.0/128) AS [free space in MB] FROM sys.dm_db_file_space_usage; -- Determining the amount of space used by the version store SELECT SUM(version_store_reserved_page_count) AS [version store pages used], (SUM(version_store_reserved_page_count)*1.0/128) AS [version store space in MB] FROM sys.dm_db_file_space_usage; -- Determining the amount of space used by internal objects SELECT SUM(internal_object_reserved_page_count) AS [internal object pages used], (SUM(internal_object_reserved_page_count)*1.0/128) AS [internal object space in MB] FROM sys.dm_db_file_space_usage; -- Determining the amount of space used by user objects SELECT SUM(user_object_reserved_page_count) AS [user object pages used], (SUM(user_object_reserved_page_count)*1.0/128) AS [user object space in MB] FROM sys.dm_db_file_space_usage; |
If you use SQL Monitor, you can also view what’s going on in the new tempdb section.
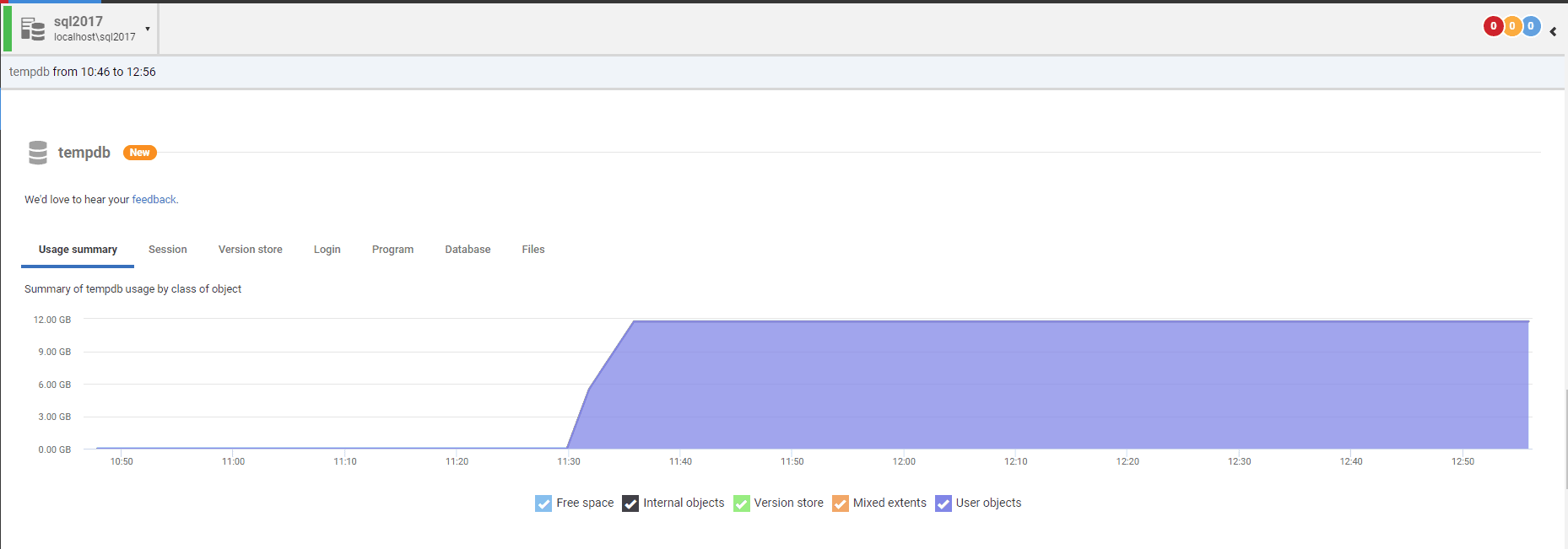
The following script is my go-to that I have used for years to reactively and proactively understand what’s going on inside TempDB. It was adapted from Microsoft by Kendra Little (B|T) back in 2009 and is still an excellent tool for analyzing TempDB workloads. This script’s query results allow you to clearly identify what space is allocated by a transaction and even capture the query text and its execution plan associated with it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
SELECT t1.session_id, t1.request_id, task_alloc_GB = CAST((t1.task_alloc_pages * 8. / 1024. / 1024.) AS NUMERIC(10, 1)), task_dealloc_GB = CAST((t1.task_dealloc_pages * 8. / 1024. / 1024.) AS NUMERIC(10, 1)), host = CASE WHEN t1.session_id <= 50 THEN 'SYS' ELSE s1.host_name END, s1.login_name, s1.status, s1.last_request_start_time, s1.last_request_end_time, s1.row_count, s1.transaction_isolation_level, query_text = COALESCE( ( SELECT SUBSTRING( text, t2.statement_start_offset / 2 + 1, (CASE WHEN statement_end_offset = -1 THEN LEN(CONVERT(NVARCHAR(MAX), text)) * 2 ELSE statement_end_offset END - t2.statement_start_offset ) / 2 ) FROM sys.dm_exec_sql_text(t2.sql_handle) ), 'Not currently executing' ), query_plan = ( SELECT query_plan FROM sys.dm_exec_query_plan(t2.plan_handle) ) FROM ( SELECT session_id, request_id, task_alloc_pages = SUM(internal_objects_alloc_page_count + user_objects_alloc_page_count), task_dealloc_pages = SUM(internal_objects_dealloc_page_count + user_objects_dealloc_page_count) FROM sys.dm_db_task_space_usage GROUP BY session_id, request_id ) AS t1 LEFT JOIN sys.dm_exec_requests AS t2 ON t1.session_id = t2.session_id AND t1.request_id = t2.request_id LEFT JOIN sys.dm_exec_sessions AS s1 ON t1.session_id = s1.session_id -- ignore system unless you suspect there's a problem there WHERE t1.session_id > 50 -- ignore this request itself AND t1.session_id <> @@SPID ORDER BY t1.task_alloc_pages DESC; GO |
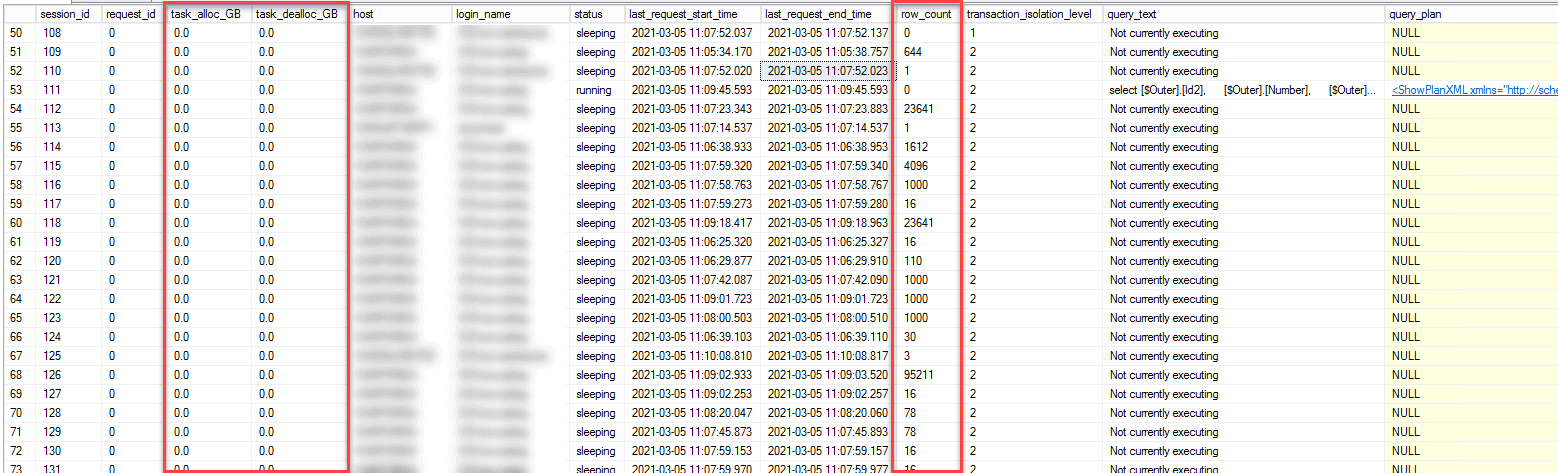
Here are a couple screenshots of the output.
This one shows active row counts, but there is not a ton of space allocated.
This one shows only one row as a row_count, but look at the task_alloc_GB column. Even though it is only one row, this transaction is taking 1.6GB of space.
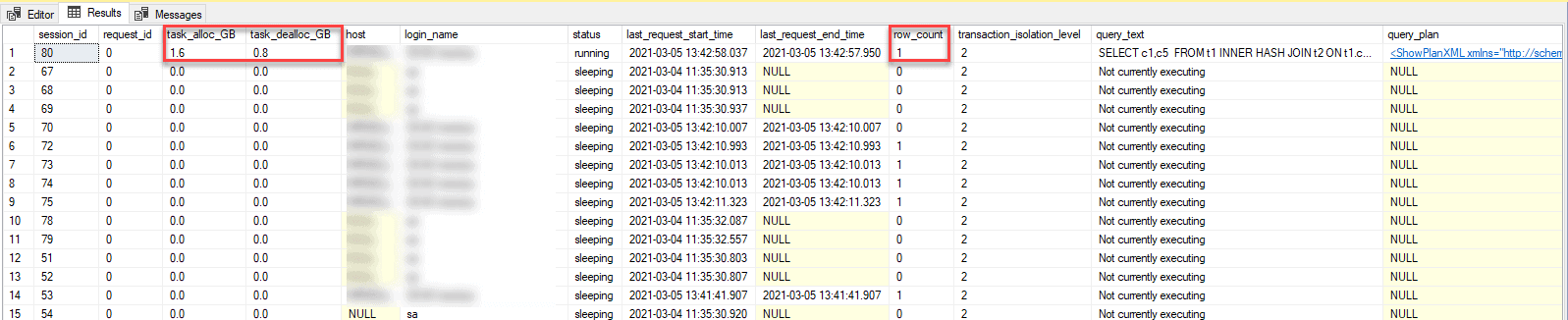
Once you identify the culprit, you can move on to resizing. I highly advise you to pause and look at the causal factors before trying to resize, since it is possible to lose all purview to that information. Many of these commands are destructive and will cause you to lose metadata associated with your TempDB growth–this means it is important to capture.
Resizing TempDB
Occasionally, we must resize or realign our TempDB log file (.ldf) or data files (.mdf or .ndf) due to a growth event that forces the file size out of whack. To resize TempDB we have three options, restart the SQL Server service, add additional files, or shrink the current file. We most likely have all been faced with runaway log files, and, in an emergency situation, restarting the SQL Services may not be an option, but we still need to get our log file size smaller before we run out of disk space, for example.
Restart SQL Server Services– since TempDB is non-durable, it is recreated upon service restart at the file size and count that are defined in the sys.master_files catalog view.
Add File– You can quickly get out of trouble by adding another TempDB.mdf file to another drive that has space. This will buy you some time but should be removed once the issue is resolved and your services can be restarted. I only use this one in a true emergency. If you add a file you should plan a restart of your SQL Services because it will now be the most free space file, and your workload will funnel here. So be sure to balance them by restarting to ensure the most efficient round robin use.
Shrink Files– This removes unused space and resizes the file. I’ll explain this process below.
The process of shrinking a datafile can get tricky, so I created this flow chart to help you out if you ever get into this situation. It’s very important to note that many of these commands will clear your cache and will greatly impact your server performance as it warms cache back up. In addition, you should not shrink your database data or log file unless absolutely necessary, but doing so can result in a corrupt tempdb.
Let’s walk through it, and I’ll explain some things as we go along.
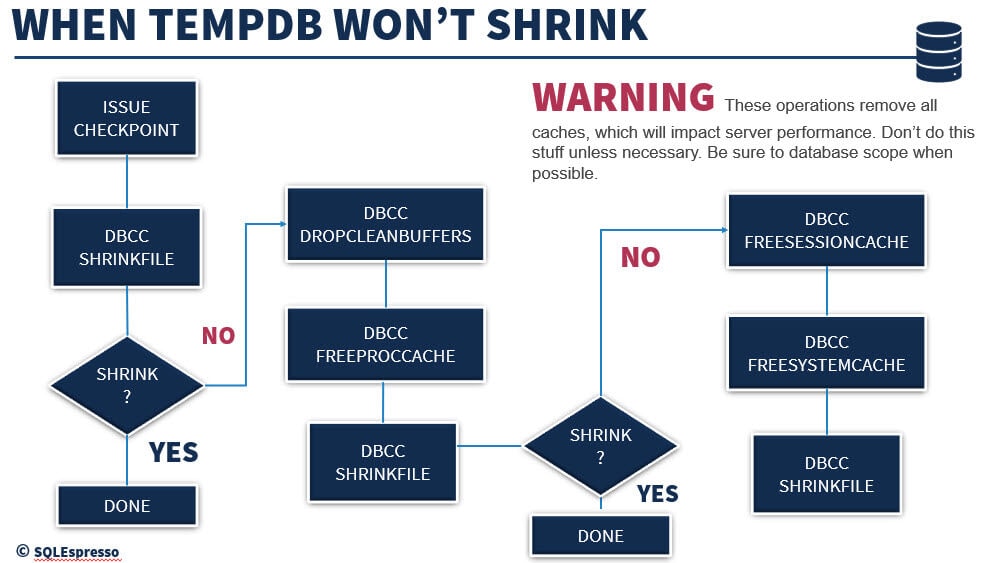
First thing you must do is issue a Checkpoint. A checkpoint marks the log as a “good up to here” point of reference. It lets the SQL Server Database Engine know it can start applying changes contained in the log during recovery after this point if an unexpected shutdown or crash occurs. Anything prior to the checkpoint is what I like to call “Hardened”. This means all the dirty pages in memory have been written to disk, specifically to the .mdf and .ndf files. So, it is important to make that mark in the log before you proceed. While TempDB is recreated and not recovered during a restart, however, this is still a requirement of this process.
|
1 2 3 |
USE TEMPDB; GO CHECKPOINT; |
Next, we try to shrink the log and data files by issuing DBCC SHRINKFILE commands. This is the step that frees the unallocated space from the database file if there is any unallocated space available. You will note the Shrink? decision block in the diagram after this step. It is possible that there is no unallocated space, and you will need to move further along the path to free some up and try again.
|
1 2 3 4 |
USE TEMPDB; GO DBCC SHRINKFILE (templog, 1024); --Shrinks it to 1GB DBCC SHRINKFILE (tempdev, 1024); |
If the database shrinks, great, congratulations! However, some of us might still have work to do. Next up is to try to free up some of that allocated space by running DBCC DROPCLEANBUFFERS and DBCC FREEPROCCACHE.
DBCC DROPCLEANBUFFERS – Clears the clean buffers from the buffer pool and columnstore object pool. This command will flush cached indexes and data pages.
|
1 |
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; |
DBCC FREEPROCCACHE – Clears the procedure cache. You are probably familiar with as a performance tuning tool in development. It will clean out all your execution plans from cache, which may free up some space in TempDB. This will create a performance issue as your execution plans now have to make it back into cache on their next execution and not benefit from plan reuse. It’s not really clear why this works, so I asked TempDB expert Pam Lahoud (B|T) for clarification as to why this has anything to do with TempDB. Both of us are diving into this to understand exactly why this works. I believe it to be related to TempDB using cached objects and memory objects associated with stored procedures which can have latches and locks on them that need to be released by running this. Check back for further clarification, as I’ll be updating this as I find out more.
|
1 |
DBCC FREEPROCCACHE WITH NO_INFOMSGS; |
Once these two commands have been run and you have attempted to free up some space, you can now try the DBCC SHRINKFILE command again. For most, this should make the shrink possible, and you will be good to go. Unfortunately, a few more of us may have to take a couple more steps through to get to that point.
When I have no other choice to get my log file smaller I run the last two commands in the process. These should do the trick and get the log to shrink.
DBCC FREESESSIONCACHE– This command will flush any distributed query connection cache, meaning queries that are between two or more servers.
|
1 |
DBCC FREESESSIONCACHE WITH NO_INFOMSGS; |
DBCC FREESYSTEMCACHE – This command will release all unused remaining cache entries from all cache stores, including temp table cache. This covers any temp table or table variables remaining in cache that need to be released.
|
1 |
DBCC FREESYSTEMCACHE ('ALL'); |
Manage TempDB growth
In my early days as a database administrator, I would have loved to have this diagram. Having some quick steps during stressful situations such as TempDB’s log file filling up on me would have been a huge help. Hopefully, someone will find this handy and be able to use it to take away a little of their stress.
Remember, it is important for you to become familiar with how your TempDB is used, tune those queries that are large consumers and know how to properly resize TempDB if it becomes full.