
- Failure #1: Not understanding data type precedence
- Failure #2: Not taking performance into consideration
- Failure #3: Assuming all numbers are created equal
- Failure #4: Relying on the ISNUMERIC built-in function
- Failure #5: Underestimating the world of silent truncation
- Failure #6: Not understanding date/time data
- Failure #7: Importing Excel data without thought to data types
- Failure #8: Treating XML just like any other string
- Failure #9: Failing to take portability into account
Failure #1: Not understanding data type precedence
When a T-SQL expression attempts to combine data values of different types, the database engine applies the rules of data type precedence to determine how values should be implicitly converted. If the values cannot be converted, the database engine returns an error.
Data type precedence can play a significant role in a variety of operations. If you don’t understand how precedence works, you can end up with errors in places you least expect them-usually at times you can least afford them.
But understanding the rules means more than just knowing that DATETIME takes precedence over DECIMAL, and DECIMAL takes precedence over INT, and INT takes precedence over CHAR. Consider the following CASE expression:
|
1 2 3 4 5 6 7 |
DECLARE @a CHAR(3) = 'def' SELECT CASE WHEN @a = 'def' THEN 0 WHEN @a = 'ghi' THEN 1 ELSE 'does not apply' END; |
In this example, the variable value equals def, so the first condition in the CASE expression evaluates to true and the SELECT statement returns the value 0. But what happens when we assign the value abc to the variable?
|
1 2 3 4 5 6 7 |
DECLARE @a CHAR(3) = 'abc' SELECT CASE WHEN @a = 'def' THEN 0 WHEN @a = 'ghi' THEN 1 ELSE 'does not apply' END; |
The SELECT statement now returns the following error:
|
1 2 |
Msg 245, Level 16, State 1, Line 16 Conversion failed when converting the varchar value 'does not apply' to data type int. |
The database engine is trying to convert the value does not apply to the INT data type, and that, of course, doesn’t work. A CASE expression returns the type with the highest precedence from the result expressions (the expressions after THEN and ELSE). In this instance, those values include two integers and one string (0, 1, and does not apply). That means the returned result expression must be an integer or be convertible to an integer. It doesn’t matter that the two conditions in the CASE expression evaluate to false. All the database engine cares about is that an integer takes precedence over a character data type.
One way to address this issue is to treat all the result expressions as strings:
|
1 2 3 4 5 6 7 |
DECLARE @a CHAR(3) = 'abc' SELECT CASE WHEN @a = 'def' THEN '0' WHEN @a = 'ghi' THEN '1' ELSE 'does not apply' END; |
Now the CASE expression returns the value does not apply. By specifying the result expressions as strings, we’ve put them on equal footing in the eyes of the precedence gods.
For our example here, enclosing the values in single quotes did the trick, but in many situations, you’ll likely have to use CAST or CONVERT to explicitly convert the values, such as when you pass in variables or columns. The point is, you have to understand how data is converted and what that means to your expressions. Otherwise, you can wind up with a nightly batch process that fails every third run for no apparent reason.
Such issues are hardly limited to CASE expressions. Let’s take a look at the COALESCE function in action:
|
1 2 3 4 5 6 7 |
DECLARE @a CHAR(3) = 'abc', @b CHAR(5) = 'defgh', @c VARCHAR(10) = NULL, @d INT = 1234; SELECT COALESCE(@c, @d, @a); |
We declare a set of variables and then use COALESCE to return the first value that does not evaluate to NULL. As expected, the SELECT statement returns 1234. Now let’s switch the variable order:
|
1 |
SELECTCOALESCE(@c, @a, @d); |
This time, the statement generates an error, even though the @a variable contains a non-NULL value:
|
1 2 |
Msg 245, Level 16, State 1, Line 88 Conversion failed when converting the varchar value 'abc' to data type int. |
Once again, the database engine is trying to convert data and the conversion is failing. Similar to a CASE expression, COALESCE returns the data type of the expression with the highest precedence. The @d variable is defined as an INT, which has precedence of the other variable types. As a result, any value returned by the function, other than NULL, must be an integer or convertible to one.
The way around this is, of course, to use CONVERT or CASE to explicitly convert the integer to a character data type:
|
1 |
SELECTCOALESCE(@c, @a,CONVERT(VARCHAR(10), @d)); |
Now the SELECT statement will return a value of abc. That said, it’s not enough to simply convert numeric data to a string. Take a look at what happens when we mix things up again:
|
1 2 3 |
SELECT COALESCE(@c, @a, @b) AS FirstValue, SQL_VARIANT_PROPERTY(COALESCE(@c, @a, @b), 'basetype') AS ValueType, SQL_VARIANT_PROPERTY(COALESCE(@c, @a, @b), 'maxlength') AS TypeLength; |
The SQL_VARIANT_PROPERTY function lets us view details about the value being returned. As the following results show, the @a value is returned as VARCHAR(10):
|
FirstValue |
ValueType |
TypeLength |
|
abc |
varchar |
10 |
Although the VARCHAR data type adds only a couple bytes per value, those bytes can add up to a significant amount if we’re talking billions of rows, especially if those rows are sitting in memory.
The ISNULL function is another one that can cause unexpected issues. The function replaces the first value with the second value if the first value is NULL, as shown in the following example:
|
1 2 3 4 5 6 7 |
DECLARE @a CHAR(3) = 'abc', @b CHAR(2) = NULL, @c INT = 1234, @d INT = NULL; SELECT ISNULL(@d, @c); |
Because the @d variable is NULL, the SELECT statement returns a value of 1234. Now suppose we specify @a as the second value:
|
1 |
SELECTISNULL(@d, @a); |
Once again, the database engine generates a conversion error:
|
1 2 |
Msg 245, Level 16, State 1, Line 159 Conversion failed when converting the varchar value 'abc' to data type int. |
Unless you pass in a literal NULL as the first expression, ISNULL uses that expression’s type for the returned value. In this case, the type is INT, which means the database engine is trying to convert abc to a numeric type. Not only can this lead to an error, as we received here, but it can also lead to an odd sort of truncation:
|
1 2 3 |
SELECT ISNULL(@b, @c) FirstValue, SQL_VARIANT_PROPERTY(ISNULL(@b, @c), 'basetype') AS ValueType, SQL_VARIANT_PROPERTY(ISNULL(@b, @c), 'maxlength') AS TypeLength; |
The first value this time around is of the type CHAR(2). When we try to convert the @c value to CHAR, we don’t get an error, but rather an asterisk:
|
FirstValue |
ValueType |
TypeLength |
|
* |
char |
2 |
The problem is not one of a failed implicit conversion, but rather one of trying to turn an INT value into a CHAR(2) value. If it were CHAR(4), the conversion would be fine. Instead, we end up in conversion limbo, a likely carryover from the early days of handling database overflow errors, before error handling got a more reputable foothold. Imagine trying to insert asterisks into those data warehouse columns configured with the INT data type.
You should learn how data type precedence works and how it is applied before these types of problems arise. A good place to start is with the MSDN topic “Data Type Precedence.” But don’t stop there. You should also know how your expressions, functions, and other elements treat data when it is implicitly converted. Your best strategy is to explicitly convert the data when you know a conversion is imminent and to provide the logic necessary to handle different possible scenarios. Otherwise, you leave yourself open to chance, which seldom works as a long-term strategy.
Failure #2: Not taking performance into consideration
Not only can implicit conversions wreak havoc by generating unexpected errors (or those pseudo-error asterisks), but they also take their toll on performance. Let’s look at an example of a basic SELECT statement that retrieves data from the AdventureWorks2014 sample database:
|
1 2 3 4 5 |
SET STATISTICS IO ON; SELECT BusinessEntityID, LoginID FROM HumanResources.Employee WHERE NationalIDNumber = 948320468; SET STATISTICS IO OFF; |
The statement includes a WHERE clause that specifies a NationalIDNumber value, which is stored in the Employee table as NVARCHAR(15) data. Because we’re capturing the I/O statistics, we receive the following information as part of our results:
|
1 |
Table 'Employee'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
There are two important statistics worth noting here. The first is that an index scan is being performed, rather than a seek, and the second is that it takes six logical reads to retrieve the data. If we generate an execution plan when we run the query, we can view information about the scan by hovering over the scan icon in the execution plan. The following figures shows the details about the scan:
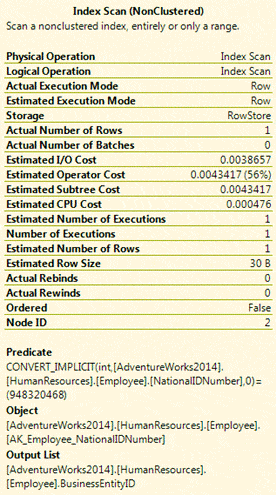
First, take a look at the Predicate section. The database engine is using the CONVERT_IMPLICIT function to convert the NationalIDNumber value in order to compare it to the 948320468 value. That’s because we’re passing the value in as an integer, so the database engine must implicitly convert the column value to an INT to do the comparison.
Now let’s rerun the statement, only pass the NationalIDNumber value in as a string:
|
1 2 3 4 5 |
SET STATISTICS IO ON; SELECT BusinessEntityID, LoginID FROM HumanResources.Employee WHERE NationalIDNumber = '948320468'; SET STATISTICS IO OFF; |
This time, our statistics show that the database engine performs no scans and only four logical reads:
|
1 |
Table 'Employee'. Scan count 0, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
If we generate the execution plan, we can view details about the seek, which shows a conversion, but only in terms of data length, with no scan performed. We even get better statistics in operator, I/O, and CPU costs.
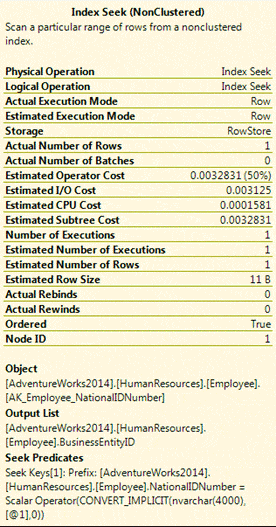
This, of course, is only one query retrieving one row based on one value. But start multiplying those values and rows and queries and you can end up with monstrous performance hits because you’re not paying attention to how your data is being converted.
Failure #3: Assuming all numbers are created equal
Numerical data likes to play tricks on us, especially when implicit conversions are involved. If we’re not careful, we can end up with results we don’t expect or want, often without any hint that there’s a problem.
Take, for example, the following T-SQL, which converts decimal data to integer data:
|
1 2 3 4 5 |
DECLARE @a INT = NULL, @b DECIMAL(5,2) = 345.67; SET @a = @b; SELECT @a; |
You might expect SQL Server to handle this gracefully and round the 345.56 to 346. It does not. Instead, the SELECT statement returns a value of 345. The database engine simply truncates the value, without any attempt at rounding.
What appears as only a slight loss here can translate to big losses to the bottom line. Suppose the original decimal value refers to shipping weights. If customers should be charged based on the next highest whole number, but your database is always truncating the value, someone is going to have to eat the costs for all the weight that’s not been accounted for.
There are ways to address such situations. For example, you might use the CEILING function to round the value up:
|
1 2 3 4 5 |
DECLARE @a INT = NULL, @b DECIMAL(5,2) = 345.67; SET @a = CEILING(@b); SELECT @a; |
Now the SELECT statement returns a value of 346, an amount sure to keep the accounting department happy. However, other issues await. Let’s look at what happens when we try to add a decimal and integer together:
|
1 2 3 4 5 6 7 |
DECLARE @a INT = 12345, @b DECIMAL(5,2) = 345.67; SELECT @a + @b AS Total, SQL_VARIANT_PROPERTY(@a + @b, 'basetype') AS ValueType, SQL_VARIANT_PROPERTY(@a + @b, 'precision') AS TypePrecision, SQL_VARIANT_PROPERTY(@a + @b, 'scale') AS TypeScale; |
Because of data type precedence, SQL Server converts the integer to a decimal and then adds the two together. Although the database engine handles the conversion without a hiccup, it does increase the precision:
|
Total |
ValueType |
TypePrecision |
TypeScale |
|
12690.67 |
decimal |
13 |
2 |
The increased precision might not seem a big deal, but it can add up. According to SQL Server documentation, a decimal with a precision from 1 through 9 requires five bytes of storage. A decimal with a precision of 10 through 19 requires nine bytes of storage.
You need to understand how precision works whenever you’re converting numeric data. Not only do you risk extra overhead, but you could also end up with a less-than-happy database engine. Let’s recast the last example in order to insert the sum into a table variable:
|
1 2 3 4 5 6 7 8 |
DECLARE @a INT = 12345, @b DECIMAL(5,2) = 345.67; DECLARE @c TABLE(ColA DECIMAL(5,2)); INSERT INTO @c(ColA) SELECT @a + @b; |
When we try to insert the data, we receive the following error:
|
1 2 3 |
Msg 8115, Level 16, State 8, Line 258 Arithmetic overflow error converting numeric to data type numeric. The statement has been terminated. |
If variable @a had been a smaller number, such as 123, we would have received no error. The same is true if we change the precision of ColA to match to match the sum, in which case the insert will run with no problem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE @a INT = 12345, @b DECIMAL(5,2) = 345.67; DECLARE @c TABLE(ColA DECIMAL(7,2)); INSERT INTO @c(ColA) SELECT @a + @b; SELECT ColA, SQL_VARIANT_PROPERTY(ColA, 'basetype') AS ColType, SQL_VARIANT_PROPERTY(ColA, 'precision') AS TypePrecision, SQL_VARIANT_PROPERTY(ColA, 'scale') AS TypeScale FROM @c; |
As the following results show, the ColA value is now configured as DECIMAL(7,2):
|
ColA |
ColType |
TypePrecision |
TypeScale |
|
12690.67 |
decimal |
7 |
2 |
The point of all this is that you must be prepared to handle whatever type of numeric data comes your way, which means you need to understand how the numeric data types work in SQL Server, especially when you start converting data.
Let’s look at another example of what might go wrong. In the following T-SQL, we compare REAL and INT values:
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @a INT = 100000000, @b INT = 100000001, @c REAL = NULL; SET @c = @b; SELECT CASE WHEN @a = @c THEN 'values equal' ELSE 'values not equal' END AS CheckEquality, STR(@c, 30, 20) AS VarCValue; |
In this case, we’re implicitly converting the @b integer to a REAL value and then comparing that value to the @a integer, using a CASE expression to test for equality. Based on the original values of the two integers, we might expect the CASE expression to return values not equal. Instead, we get the following results:
|
CheckEquality |
VarCValue |
|
values equal |
100000000.0000000000000000 |
The STR function let’s us easily view the actual value being stored in the @c variable, rather than scientific notation. As you can see, there is no hint of the 1 that was there before we converted the data. The problem is that the REAL data type, like the FLOAT data type, is considered an approximate-number data type, which means not all values in the permitted range can be represented exactly. If you plan to compare or convert REAL or FLOAT data, you better understand the limitations of those types. Otherwise that rocket you’re sending to the next passing asteroid might end up boldly going where no one has gone before
Also be aware of how SQL Server handles numeric data when used in conjunction with non-numeric data, particularly when trying to add or concatenate values. For example, if you try to add two values in which one is an integer and one is a string, the database engine implicitly converts the string type to the numeric type and adds the values together:
|
1 2 3 4 5 6 |
DECLARE @a INT = 123, @b CHAR(3) = '456'; SELECT @a + @b AS EndValue, SQL_VARIANT_PROPERTY(@a + @b, 'basetype') AS BaseType, SQL_VARIANT_PROPERTY(@a + @b, 'maxlength') AS TypeLength; |
As the following results show, the two values are added together and an integer is returned:
|
EndValue |
BaseType |
TypeLength |
|
579 |
int |
4 |
The database engine converts the character data to an integer because the INT data type takes precedence over the CHAR data type. If what you’re actually after is to concatenate the two values, then you must explicitly convert the integer to a string:
|
1 2 3 4 5 6 7 8 |
DECLARE @a INT = 123, @b CHAR(3) = '456'; SELECT CONVERT(CHAR(3), @a) + @b AS EndValue, SQL_VARIANT_PROPERTY(CONVERT(CHAR(3), @a) + @b, 'basetype') AS BaseType, SQL_VARIANT_PROPERTY(CONVERT(CHAR(3), @a) + @b, 'maxlength') AS TypeLength; |
Now the results show the concatenated value and the CHAR data type:
|
EndValue |
BaseType |
TypeLength |
|
123456 |
char |
6 |
Differentiating between adding values and concatenating values, like any aspect of numerical data, requires that you understand how numeric data types work, how data type precedence works, and how T-SQL elements work with numeric data. Otherwise, you can never be sure you’re getting the results you had actually expected.
Failure #4: Relying on the ISNUMERIC built-in function
One T-SQL element in particular that can catch developers off-guard is the ISNUMERIC function. The function tests an expression to determine whether it produces a numeric type. If it does, the function returns the value 1; otherwise, it returns a 0. The challenge with this function is that it can sometimes interpret a value as numeric even if it contains no numbers.
Let’s look at an example. The following T-SQL creates a table variable, adds an assortment of string values to the variable, and then uses a CASE expression to test whether those values are considered numeric:
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @a TABLE(ColA VARCHAR(10)); INSERT INTO @a VALUES ('abc'), ('123'), ('$456'), ('7e9'), (','), ('$.,'); SELECT colA, CASE WHEN ISNUMERIC(colA) = 1 THEN CAST(colA AS INT) END AS TestResults FROM @a; |
If a value is numeric, the SELECT statement tries to convert the value to the INT data type; otherwise, the statement returns a NULL. Unfortunately, when the CASE expression bumps up against the value $456, the database engine generates the following error:
|
1 2 |
Msg 245, Level 16, State 1, Line 308 Conversion failed when converting the varchar value '$456' to data type int. |
The ISNUMERIC function is actually quite liberal when deciding what constitutes a numeric value. In this case, it sees a dollar sign and interprets the value as numeric, yet when the CASE expression tries to convert the value to an integer, the database engine baulks.
To get a better sense of what the function considers to be numeric, let’s recast our SELECT statement:
|
1 2 |
SELECT ColA, ISNUMERIC(ColA) AS TestResults FROM @a; |
As the following results show, the ISNUMERIC function interprets all values except abc as numeric:
|
ColA |
TestResults |
|
abc |
0 |
|
123 |
1 |
|
$456 |
1 |
|
7e9 |
1 |
|
, |
1 |
|
$., |
1 |
For the value $456 it’s easy to see how the function can interpret this as money and consequently a numeric type. The next value, 7e9, also makes sense because the function sees it as scientific notation. What is not so clear is why the last two values are considered numeric. If such values are possible in your data set, relying on the ISNUMERIC function to control your statement’s logic when converting data can lead to an assortment of problems.
If you’re running SQL Server 2012 or later, you can instead use the TRY_CONVERT function to test your values before converting them:
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @a TABLE(ColA VARCHAR(10)); INSERT INTO @a VALUES ('abc'), ('123'), ('$456'), ('7e9'), (','), ('$.,'); SELECT ColA, CASE WHEN TRY_CONVERT(int, ColA) IS NULL THEN 0 ELSE 1 END AS TestResults FROM @a; |
If the value cannot be converted to an integer, the CASE expression returns the value 0; otherwise, it returns a 1, as shown in the following results:
|
ColA |
TestResults |
|
abc |
0 |
|
123 |
1 |
|
$456 |
0 |
|
7e9 |
0 |
|
, |
0 |
|
$., |
0 |
This time we have a more reliable assessment of the data. Unfortunately, if you’re running a version of SQL Server prior to 2012, you’ll have to come up with another way to check for numeric values before trying to convert them. Just be careful not to rely on the ISNUMERIC function alone unless you’re certain about the predictability of the data you’ll be converting.
Failure #5: Underestimating the world of silent truncation
If a value will be truncated when inserting it into a column, the database engine returns an error, warning you of the possible truncation. Unfortunately, the database engine is not so diligent in all cases, particularly when it comes to variables and parameters. One wrong move and you can end up with a database full of truncated data and a recovery scenario that leaves you without sleep for the next three months.
Let’s look at a simple example of what can happen:
|
1 2 3 4 5 6 7 |
DECLARE @a CHAR(6) = 'abcdef', @b CHAR(3) = NULL; SET @b = @a SELECT @b AS VarValue, SQL_VARIANT_PROPERTY(@b, 'basetype') AS ValueType, SQL_VARIANT_PROPERTY(@b, 'maxlength') AS TypeLength; |
When we attempt to set the value of @b to @a, the database engine happily obliges, as evidenced by the SELECT statement’s results:
|
VarValue |
ValueType |
TypeLength |
|
abc |
char |
3 |
The original value, abcdef, has been seamlessly truncated to conform to the CHAR(3) type. The same thing can happen if we run an ISNULL function against the values:
|
1 2 3 |
SELECT ISNULL(@b, @a) AS VarValue, SQL_VARIANT_PROPERTY(ISNULL(@b, @a), 'basetype') AS ValueType, SQL_VARIANT_PROPERTY(ISNULL(@b, @a), 'maxlength') AS TypeLength; |
The statement returns the same results as the preceding SELECT, with the original value truncated. Unless we pass in a literal NULL as the first expression, ISNULL uses the type of the first expression, which in this case is CHAR(3).
Parameters too can fall victim to the sinister world of silent truncation:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE #a (ColA CHAR(5)); IF OBJECT_ID('ProcA', 'P') IS NOT NULL DROP PROCEDURE ProcA; GO CREATE PROCEDURE ProcA @a VARCHAR(5) AS INSERT INTO #a(ColA) VALUES(@a); GO |
The target column in the #a temporary table is configured as CHAR(5) and the stored procedure’s parameter @a as VARCHAR(5), which would suggest no room from truncation. However, unless you explicitly check the parameter’s input value, you could run into problems. For example, suppose we pass in a value larger that what the parameter supports when calling the procedure:
|
1 2 3 |
EXEC ProcA 'ab cd ef gh'; SELECT * FROM #a; |
The database engine will silently truncate the value and insert a shortened version, giving us a returned value of ab cd, all without any sort of error.
Another issue to watch for is if ANSI warnings are turned off during your insert operations. By default, the warnings are turned on, which is why the database engine generates an error if a value will be truncated when inserting it into a column:
|
1 2 3 4 |
DECLARE @a CHAR(5) = 'abcde'; CREATE TABLE #a (ColA CHAR(3)); INSERT INTO #a VALUES(@a); |
By default, the statement generates the following error:
|
1 2 3 |
Msg 8152, Level 16, State 14, Line 437 String or binary data would be truncated. The statement has been terminated. |
However, it’s not uncommon to set ANSI warnings to off in certain cases, such as bulk load operations:
|
1 2 3 4 5 6 7 8 9 10 |
SET ANSI_WARNINGS OFF; DECLARE @b CHAR(5) = 'abcde'; CREATE TABLE #b (ColB CHAR(3)); INSERT INTO #b VALUES(@b); SELECT ColB FROM #b; SET ANSI_WARNINGS ON; |
This time, the database engine does not return an error. It simply truncates the data and sticks what’s left into the table, giving us the value abc.
You must be vigilant against silent truncations when data is being converted from one type to another, even if it’s only a smaller size of the same type. Truncations can and do occur without anyone realizing what has happened-until it’s too late.
Failure #6: Not understanding date/time data
Date/time values in SQL Server can be full of surprises when converting data, often because of the format used to pass in the date. For instance, the following T-SQL tries to convert a date that follows the day-month-year format:
|
1 2 3 4 5 |
DECLARE @a DATETIME = NULL, @b VARCHAR(10) = '21/3/2015'; SET @a = @b; SELECT @a; |
When the database engine tries to convert the string, it returns an out-of-range error:
|
1 2 |
Msg 242, Level 16, State 3, Line 582 The conversion of a varchar data type to a datetime data type resulted in an out-of-range value. |
In this case, the SQL Server instance is configured to use US English, but the date conforms to British and French standards. Suppose we recast the date as follows:
|
1 2 3 4 5 |
DECLARE @a DATETIME = NULL, @b VARCHAR(10) = '3/21/2015'; SET @a = @b; SELECT @a; |
The SELECT statement now returns the following results:
|
1 |
2015-03-21 00:00:00.000 |
SQL Server follows specific date/time conventions based on the configured language. Look at what happens when we change the language:
|
1 2 3 4 5 6 |
SET LANGUAGE british; DECLARE @a DATETIME = NULL, @b VARCHAR(10) = '21/3/2015'; SET @a = @b; SELECT @a; |
The database engine converts the date with no problem, and our SELECT statement returns the value we expect. Now let’s run the T-SQL again, only change the language to US English:
|
1 2 3 4 5 6 |
SET LANGUAGE us_english; DECLARE @a DATETIME = NULL, @b VARCHAR(10) = '21/3/2015'; SET @a = @b; SELECT @a; |
This time around, we receive an out-or-range conversion error because the date follows the day-month-year convention. If you’re not prepared for these differences, you can end up with out-of-range conversion errors all over the place.
One way to address this issue is to use the CONVERT function to specifically convert the string value to the necessary format:
|
1 2 3 4 5 |
DECLARE @a DATETIME = NULL, @b VARCHAR(10) = '21/3/2015'; SET @a = CONVERT(DATETIME, @b, 103); SELECT @a; |
The third argument in the CONVERT function, 103, specifies that the value to be converted should be in the British/French style. As a result, the SELECT statement will now return our date/time value as expected.
Another approach is to set the DATEFORMAT property. Normally, the selected language determines the property’s value, but we can override it:
|
1 2 3 4 5 6 7 |
SET DATEFORMAT dmy; DECLARE @a DATETIME = NULL, @b VARCHAR(10) = '21/3/2015'; SET @a = @b; SELECT @a; |
We’ve set the DATEFORMAT property to dmy for day-month-year. The British/French version of the date can now be converted with no problem, and if we want to return to the US English format, we can change the property setting once again:
|
1 2 3 4 5 6 7 |
SET DATEFORMAT mdy; DECLARE @a DATETIME = NULL, @b VARCHAR(10) = '3/21/2015'; SET @a = @b; SELECT @a; |
Using the CONVERT function or setting the DATEFORMAT property are fine approaches if we know the source language. If we have no way to determine the source of the data within the database, it makes this process more difficult, and we have to rely on the application to tell us the language or to enforce a particular format.
If you can determine the language based on the connection to the data source, you can change your settings to target that language before importing the data, and then change the language back when the import is complete. Robyn Page offers great insight into this and other issues related to date/time values and languages in her article “Robyn Page’s SQL Server DATE/TIME Workbench.”
Also be aware that you can run into issues when converting data from one date/time type to another. Suppose you’re trying to convert DATETIME data to SMALLDATETIME:
|
1 2 3 4 5 |
DECLARE @a DATETIME = '3/21/2099', @b SMALLDATETIME = NULL; SET @b = @a; SELECT @b; |
Notice the year: 2099. This works fine for the DATETIME data type, but not SMALLDATETIME. When we try to convert the data, the database engine generates the following out-or-range conversion error:
|
1 2 |
Msg 242, Level 16, State 3, Line 740 The conversion of a datetime data type to a smalldatetime data type resulted in an out-of-range value. |
The DATETIME data type supports the years 1753 through 9999, but SMALLDATETIME goes only from 1900 through 2079. Perhaps for many of your needs, the smaller range is enough. But all it takes is one out-of-range year to bring your bulk load operation to a halt.
Even when you can convert a date from DATETIME to SMALLDATETIME, you should also take into account the loss of precision in seconds:
|
1 2 3 4 5 |
DECLARE @a DATETIME = GETDATE(), @b SMALLDATETIME = NULL; SET @b = @a; SELECT @a AS VarA, @b AS VarB; |
The following table shows the results returned by the SELECT statement:
|
VarA |
VarB |
|
2015-03-18 11:33:10.560 |
2015-03-18 11:33:00 |
Notice that we lose over 10 seconds when converting from DATETIME to SMALLDATETIME. The database engine essentially truncates the value at the minute mark and returns only zeroes for the seconds. A few seconds here or there might not seem much, but they can add up and impact analytical processes that require precise calculations down to the hundredth of a second.
Whenever you’re working with date/time values, you have to take their nature into account. Consider the following example:
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @a DATETIME2 = '2015-03-12 11:28:19.7412345', @b DATETIME, @c SMALLDATETIME, @d VARCHAR(30); SET @b = @a; SET @c = @a; SET @d = @a; SELECT @a, @b, @c, @d; |
The SELECT statement returns the following results (formatted as a list for easy viewing):
|
1 2 3 4 |
2015-03-12 11:28:19.7412345 2015-03-12 11:28:19.740 2015-03-12 11:28:00 2015-03-12 11:28:19.7412345 |
When converting data to or from a date/time data type, you should have a good sense of how the data types work and conversions work and what can happen to your values-before you start tracking data for the next Olympic trials.
Failure #7: Importing Excel data without thought to data types
Importing Excel data can be tricky unless you know exactly what types of data the spreadsheet contains and you’re certain the data types will always be the same. But if you’re importing data from an Excel spreadsheet on a regular basis, and that spreadsheet is continuously updated, you run the risk of data types changing, which can making converting the data unpredictable, unless you’re prepared for the possible changes.
Here’s the problem. When you import Excel data into SQL Server, the OLE DB provider guesses at a column’s data type by sampling a set of rows and going with the majority. By default, that sample is made up of the spreadsheet’s first eight rows. For example, if a column contains five numeric values in the first eight rows, the provider assigns the FLOAT data type to that column (even if all numbers are integers). When this occurs, any non-numeric values are returned as NULL.
Although, there are ways to work around this limitation, such as adding the IMEX property to the provider string and setting its value to 1, the issue points to another challenge. Under certain circumstances, the provider can return different data types for the same column, depending on how the data has been updated between import operations. If you’re T-SQL statements convert the data as it’s coming into the database, you need to include the logic necessary to handle the possibility of changing types.
For instance, suppose you use a SELECT...INTO statement and the OPENROWSET function to retrieve data from an Excel spreadsheet and load it into a temporary table. You also define the provider string to take into account the possibility of a column containing mixed types. As to be expected, the provider will determine the table’s column types based on the sampled values in the spreadsheet.
One of the columns is supposed to contain only integers, but occasionally alphanumeric values find there way into the column. As a result, the provider will create the corresponding column in the temporary table as either FLOAT or VARCHAR(255), depending on the balance in the sample. Let’s look at temporary table initially set up with a single VARCHAR column:
|
1 2 3 |
CREATE TABLE #a (ColA VARCHAR(255)); INSERT INTO #a VALUES ('101'), ('102ex'), ('103'), ('1o4'); |
Suppose that ColA is usually configured with the INT data type, but in this case, it was assigned the VARCHAR data type to accommodate those wayward string values. If any T-SQL code contains logic relying on the column being INT, our statements could fail, which might be particularly confusing if we don’t understand how the OLE DB provider determines data types.
To safeguard against this issue, we need to incorporate the logic necessary to handle the possibility of changing types:
|
1 2 3 4 5 6 |
SELECT ColA, CASE WHEN TRY_CONVERT(INT, ColA) IS NOT NULL THEN CAST(ColA AS INT) ELSE 0 END AS ColA FROM #a; |
In this case, we’re saying that, if the data isn’t right, set the value to 0 until we can fix it; otherwise, convert the value to an integer, giving us the following results:
|
ColA |
CheckA |
|
101 |
101 |
|
102ex |
0 |
|
103 |
103 |
|
1o4 |
0 |
You might take a different approach, of course, or many different approaches. What’s important here is that, unless you can rely on your Excel spreadsheets to always provide the same types of data, you have to be prepared for the possibility of unexpected changes.
Failure #8: Treating XML just like any other string
Converting string data to XML is relatively painless as long as the string is well formed XML, in which case you can do something similar to the following to carry out your conversion:
|
1 2 3 4 5 6 7 8 |
DECLARE @a VARCHAR(100) = '<things> <thing>abc 123 def</thing> <thing>ghi 456 jkl</thing> </things>'; DECLARE @b XML; SET @b = CONVERT(XML, @a); SELECT @b; |
All we’re doing here is explicitly converting variable @a and assigning it to variable @b, which has been configured with the XML data type. The SELECT statement gives us the following results:
|
1 |
<things><thing>abc 123 def</thing><thing>ghi 456 jkl</thing></things> |
One consequence of converting the data in this way is that we lose the tabs and linefeeds that help make the XML more readable. In many cases, the way in which the XML is displayed will not be an issue. However, if you want to preserve those tabs and linefeeds, you need to add the style argument to the CONVERT function:
|
1 2 3 4 5 6 7 8 |
DECLARE @a VARCHAR(100) = '<things> <thing>abc 123 def</thing> <thing>ghi 456 jkl</thing> </things>'; DECLARE @b XML; SET @b = CONVERT(XML, @a, 1); SELECT @b; |
The style argument (1) tells the database engine to preserve any insignificant white space, such as tabs and linefeeds. Now the SELECT statement returns results that look like the following:
|
1 2 3 4 |
<things> <thing>abc 123 def</thing> <thing>ghi 456 jkl</thing> </things> |
Given how effectively the CONVERT function handles this conversion, we might expect it to work the same way when we’re converting XML data to VARCHAR data:
|
1 2 3 4 5 6 7 8 |
DECLARE @a XML = '<things> <thing>abc 123 def</thing> <thing>ghi 456 jkl</thing> </things>'; DECLARE @b VARCHAR(100); SET @b = CONVERT(VARCHAR(100), @a, 1); SELECT @b; |
Unfortunately, adding the style argument doesn’t help and we get the following results:
|
1 |
<things><thing>abc 123 def</thing><thing>ghi 456 jkl</thing></things> |
The problem has to do with variable @a. The database engine is implicitly converting the string value to the XML type, which means that the tabs and linefeeds are not being preserved during that assignment. The way to get around this is to use the CONVERT function to explicitly cast the string to the XML type when assigning the value to the data type:
|
1 2 3 4 5 6 7 8 |
DECLARE @a XML = CONVERT(XML, '<things> <thing>abc 123 def</thing> <thing>ghi 456 jkl</thing> </things>', 1); DECLARE @b VARCHAR(100); SET @b = CONVERT(VARCHAR(100), @a, 1); SELECT @b; |
Now our results are more in line with what we want:
|
1 2 3 4 |
<things> <thing>abc 123 def</thing> <thing>ghi 456 jkl</thing> </things> |
None of this is in itself a big deal, but let’s look at what happens if we convert the XML to the VARCHAR type without specifying the style argument when setting the value of @b:
|
1 2 3 4 5 6 7 8 |
DECLARE @a XML = CONVERT(XML, '<things> <thing>abc 123 def</thing> <thing>ghi 456 jkl</thing> </things>', 1); DECLARE @b VARCHAR(100); SET @b = CONVERT(VARCHAR(100), @a); SELECT @b; |
Suddenly our results look quite different:
|
1 2 3 4 |
<things> <thing>abc 123 def</thing> <thing>ghi 456 jkl</thing> </things> |
SQL Server’s XML parser attempts to store special characters such as tabs and linefeeds in a way that preserves them throughout various processing operations, including retrieving and converting data. This process, known as entitization, saves tabs as and linefeeds as , but tabs and linefeeds are only two types of special characters that the parser can entitize.
In most cases, when you retrieve XML directly, these special characters are automatically displayed in a readable format. That said, the XML parser is not always consistent in how it treats entitized characters. Notice in the preceding results that only one linefeed is returned as . In addition, if the database engine comes across a special character it doesn’t like, it returns an error, rather than trying to entitize it. For instance, the following example includes an ampersand (&) in each XML element:
|
1 2 3 4 5 6 7 8 |
DECLARE @a XML = CONVERT(XML, '<things> <thing>abc & def</thing> <thing>ghi & jkl</thing> </things>', 1); DECLARE @b VARCHAR(100); SET @b = CONVERT(VARCHAR(100), @a, 1); SELECT @b; |
The code now generates the following error message:
|
1 2 |
Msg 9421, Level 16, State 1, Line 953 XML parsing: line 2, character 14, illegal name character |
When possible, you can manually entitize the special characters:
|
1 2 3 4 5 6 7 8 |
DECLARE @a XML = CONVERT(XML, '<things> <thing>abc & def</thing> <thing>ghi & jkl</thing> </things>', 1); DECLARE @b VARCHAR(100); SET @b = CONVERT(VARCHAR(100), @a, 1); SELECT @b; |
But even in this case, the CONVERT function’s style argument doesn’t return the actual ampersand, only the entitized code, giving us the following results:
|
1 2 3 4 |
<things> <thing>abc & def</thing> <thing>ghi & jkl</thing> </things> |
If we want to see an actual ampersand, we need to replace the entitized character:
|
1 2 3 4 5 6 7 8 |
DECLARE @a XML = CONVERT(XML, '<things> <thing>abc & def</thing> <thing>ghi & jkl</thing> </things>', 1); DECLARE @b VARCHAR(100); SET @b = REPLACE(CONVERT(VARCHAR(100), @a, 1), '&', '&'); SELECT @b; |
Now our results are closer to what we expect:
|
1 2 3 4 |
<things> <thing>abc & def</thing> <thing>ghi & jkl</thing> </things> |
If you’re converting XML data, you have to take into account how the XML parser works in SQL Server. Otherwise, you can run into problems in unexpected ways. Even an entitized character can be a showstopper.
Failure #9: Failing to take portability into account
Some organizations have been working with SQL Server since its humble beginnings and plan to continue to do so, having no intention now or in the future to port their databases to another system. As long as SQL Server is out there, that’s where they plan to stay.
For other organizations, the future is not quite so clear-cut. Under the right circumstances, they’d be more than willing to port their databases to another system, providing the penalty for doing so isn’t too high.
If there is any chance you’ll be among those who will one day jump ship, you need to take into consideration portability when you write your T-SQL code, and an important part of that consideration is how data is being converted.
A good place to start is to quit relying on implicit conversions, such as the one shown in the following T-SQL:
|
1 2 3 4 5 6 |
DECLARE @a DATETIME = GETDATE(); DECLARE @b VARCHAR(25) = NULL; SET @b = @a; SELECT @b AS VarValue, SQL_VARIANT_PROPERTY(@b, 'basetype') AS ValueType, SQL_VARIANT_PROPERTY(@b, 'maxlength') AS TypeLength; |
The example converts a DATETIME value to VARCHAR, as shown in the following results:
|
VarValue |
ValueType |
TypeLength |
|
Mar 13 2015 11:16AM |
varchar |
25 |
Although SQL Server has no problem converting the data and returning the results we expect, we cannot be sure another database system will handle the conversion so easily or in the same way. The solution, of course, is to make all our conversions explicit:
|
1 2 3 4 5 6 |
DECLARE @a DATETIME = GETDATE(); DECLARE @b VARCHAR(25) = NULL; SET @b = CONVERT(VARCHAR(25), @a, 13); SELECT @b AS VarValue, SQL_VARIANT_PROPERTY(@b, 'basetype') AS ValueType, SQL_VARIANT_PROPERTY(@b, 'maxlength') AS TypeLength; |
The SELECT statement again returns the results we expect, but helps to avoid performance issues and surprises. However, this leads to another concern. The CONVERT function is specific to SQL Server. If we want to make our code portable, we need to go with the CAST function:
|
1 2 3 4 5 6 |
DECLARE @a DATETIME = GETDATE(); DECLARE @b VARCHAR(25) = NULL; SET @b = CAST(@a AS VARCHAR(25)); SELECT @b AS VarValue, SQL_VARIANT_PROPERTY(@b, 'basetype') AS ValueType, SQL_VARIANT_PROPERTY(@b, 'maxlength') AS TypeLength; |
The CAST function works just like the CONVERT function in this case, except that CAST conforms to ISO specifications. Any database system that adheres to these standards will be able to handle the conversion without the code needing to be modified. With CAST, we lose the style features available to CONVERT, but we’re making the code more portable and avoiding implicit conversions.


