
When someone says, “Find all the rows that have been deleted,” it’s a lot easier when the table has an Id/Identity column. Let’s take the Stack Overflow Users table:
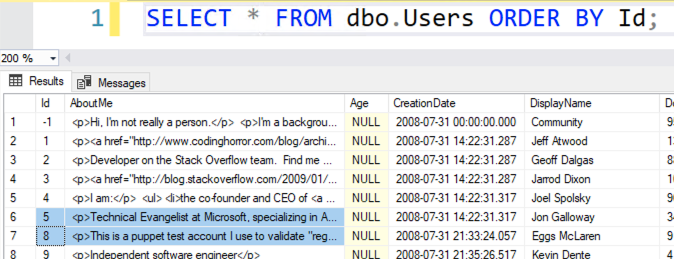
It has Ids -1, 1, 2, 3, 4, 5 … but no 6 or 7. (Or 0.) If someone asks you to find all the Ids that got deleted or skipped, how do we do it?
Using GENERATE_SERIES with SQL Server 2022 & Newer
The new GENERATE_SERIES does what it says on the tin: generates a series of numbers. We can join from that series, to the Users table, and find all the series values that don’t have a matching row in Users:
|
1 2 3 4 5 6 7 8 9 |
DECLARE @FirstId INT, @LastId INT; SELECT @FirstId = MIN(Id), @LastId = MAX(Id) FROM dbo.Users; SELECT gs.value FROM GENERATE_SERIES(@FirstId, @LastId, 1) gs LEFT OUTER JOIN dbo.Users u ON gs.value = u.Id WHERE u.Id IS NULL; |
The LEFT OUTER JOIN seems a little counter-intuitive the first time you use it, but works like a champ:

What’s that, you ask? Why does GENERATE_SERIES have fuzzy underlines? Well, SQL Server Management Studio hasn’t been updated with the T-SQL syntax that came out in the last release.
Thankfully, Microsoft separated the setup apps for SSMS and the SQL Server engine itself for this exact reason – the slow release times of SSMS were holding back the engine team from shipping more quickly, so they put the less-frequently-updated SSMS out in its own installer.
(Did I get that right? Forgive me, I’m not a smart man.)
Using Numbers Tables with Older Versions
If you’re not on SQL Server 2022 yet, you can create your own numbers table with any of these examples. Just make sure your numbers table has at least as many rows as the number of Ids you’re looking for. Here’s an example with a 100,000,000 row table:
|
1 2 3 4 5 6 7 8 |
DROP TABLE IF EXISTS dbo.Numbers; CREATE TABLE dbo.Numbers (Number INT PRIMARY KEY CLUSTERED); INSERT INTO dbo.Numbers(Number) SELECT TOP 10000000 row_number() over(order by t1.number) as N FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 GO |
Then, we’ll use that in a way similar to GENERATE_SERIES:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @FirstId INT, @LastId INT; SELECT @FirstId = MIN(Id), @LastId = MAX(Id) FROM dbo.Users; SELECT n.Number FROM dbo.Numbers n LEFT OUTER JOIN dbo.Users u ON n.Number = u.Id WHERE u.Id IS NULL AND n.Number > @FirstId AND n.Number < @LastId ORDER BY n.Number; |
That produces similar results, but not identical:
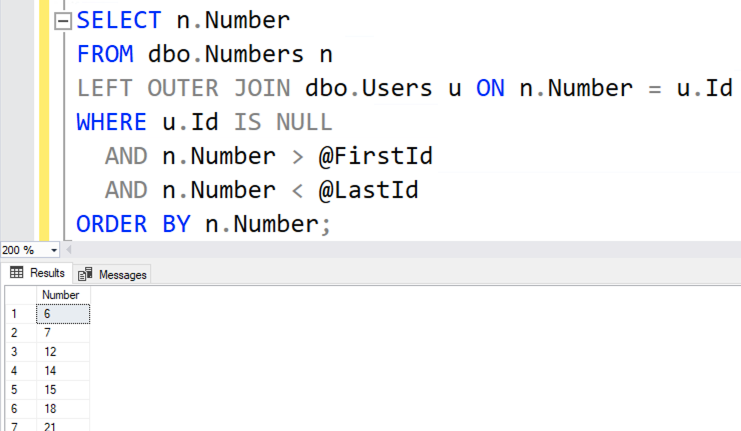
What’s different? Well, this method didn’t include 0! When I populated my numbers table, I only built a list of positive integers. The single most common mistake I see when using numbers tables is not having thorough coverage of all the numbers you need. Make sure it goes as low and as high as the values you need – a problem we don’t have with GENERATE_SERIES, since we just specify the start & end values and SQL Server takes care of the rest.
If you’d like to dive deeper into other ways to solve this problem, Itzik Ben-Gan’s chapter on Gaps & Islands will be right up your alley. Me, though, I’ll call it quits here because I’m in love with GENERATE_SERIES to solve this problem quickly and easily. Also, I’m lazy.

21 Comments. Leave new
Im not lucky enough to work in 2022 yet. How does the plan look? Im guessing its pretty decent since you love it 😀
When you’re looking for missing rows in a table, the plan is less important since you’re going to be hitting all of the data anyway. (You have to look at every single row to see if one’s missing.)
If you are checking the missing rows by looking at an id field (tipically identity) which is normally the primary key (clustered index) why do we have to look at all the data anyway? looking at the index pages of the clustered index won’t be enough?
Not clear why that the plan is less important
Because the index pages don’t have every value – just the start and end value for each page.
True.. only relevant if non clustered where the leaf level would have ALL the clustered keys
now i just feel stupid lol
Don’t feel bad – I feel stupid constantly, hahaha!
The premise of “Find all the rows that have been deleted” is different than what was shown which is “Find ID values that are missing”. The nuance is subtle but the former reinforces one of the biggest myths with ID-type sequences which is that it must be contiguous. As typically stated, there’s some compliance reason. But a given value could be missing because it was never generated (for which there are a couple of reasons).
That’s why the title is worded “How to Find Missing Rows in a Table.”
I tried to keep the title as short as possible while still conveying the goal of the post. How should I have worded the title differently in order to make that clear, Ben?
Or … did you not read the title? 😉
I read the title. And I also read the opening line in the first paragraph.
»When someone says, “Find all the rows that have been deleted,”« … which then implies that the rest of the article shows us, the dear readers, how to do that.
Like Ben Thul, I also read the opening “deleted” lines and was quite curious as to how you could find rows of a table that had actually been deleted. Not quite what the article is about. The “deleted” word is rather misleading in this case
Great post, as always!
In those solutions, Is identity cashing an issue? Doesn’t that cause a problem?
It jumps after restart or failover. If I disable the cache, I’ll be causing a performance penalty.
Thanks.
Is it an issue? Not for me, I think it’s a good idea. If you want to disable it, check out trace flag 272.
Loving these little nuggets of code.
You make the assumption that gaps in identity values are only cause by deletes. But they can also caused by rollbacked transactions too. But this is a good showcase of what generate_series does.
For those before SQL2022… It is always interesting to have a native function to do what generate_series doas, but there was a receipe using an high performance inline table function that I heard first from Itzik Ben Gan. This one works for pre SQL2022 versions and I find this more interesting than a table of numbers. Here is my own version of the equivalent code below.
Drop Function If Exists S#.GenNumsBetween
GO
Create or Alter function S#.GenNumsBetween(@low as BigInt, @High as BigInt)
returns TABLE
as
Return
(
With
TwoPower2Rows as (select * From (Values(1),(1),(1),(1)) as T(c) ) –4
, TwoPower4Rows as (select 1 as C From TwoPower2Rows as A Cross JOIN TwoPower2Rows ) — 4×4=16
, TwoPower8Rows as (select 1 as C From TwoPower4Rows as A Cross JOIN TwoPower4Rows ) — 16×16=256
, TwoPower16Rows as (select 1 as C From TwoPower8Rows as A Cross JOIN TwoPower8Rows ) — 256×256=65536
, TwoPower32Rows as (select 1 as C From TwoPower16Rows as A Cross JOIN TwoPower16Rows) — 65536×65536=4294967296
Select TOP(IIF(@high – @low + 1 < 0, 0, @high – @low + 1)) LoopIndex — in case upper bound parameter not higher than lower
From
(Select rownum = ROW_NUMBER() OVER (Order by c) from TwoPower32Rows ) as Nums
— Just offset values starting from 1 to @low value
CROSS APPLY (Select LoopIndex=@low + rownum – 1) as LoopIndex
Order By rownum
)
No, Maurice, I don’t make that assumption. Have a nice day.
In locating gaps, I’ve usually only needed the start of a gap. For that, using:
Select ID
From Table As T1
Left Join Table As T2
On T1.ID + 1 = T2.ID
where T2.ID is null
order by T1.ID
works with no need for either a generate function or a tally table. When I need to find the entire gap, a complementary join on ID – 1 gives me the other end of the gap, and a simple subtraction then shows the size of the gap.
I’ve never needed to actually list all the missing numbers, although of course there may be cases where that is necessary.
Edit – Select T1.ID…
Its a great idea using function generate_series but table Users hold many rows. IMHO its good solution using
this function to generate only missing numbers.
My query:
;with cte as
(select top 1000 –TO DO remove it because in my database count user is 299398 and max id is 10251164
— these final lines add nothing
Id , — actual number
lead(Id) over(order by Id) la, — next number
case when lead(Id) over(order by Id)=Id+1 then 1 else 0 end p –its interesting row =0 or uninteresting=1
–nextrow=row+1
FROM dbo.Users
),
cte1 as(
SELECT gs.value noid FROM cte
cross apply GENERATE_SERIES(cte.Id+1, cte.la-1, 1) gs –try generate only number for row with hole
where p=0
)
select noid from cte1 ;
(9951768 rows affected)
SQL Server Execution Times:
CPU time = 2641 ms, elapsed time = 1943 ms.
The previous query
(9951768 rows affected) –similiar result 🙂
SQL Server Execution Times:
CPU time = 12219 ms, elapsed time = 12481 ms.
It’s worth to mention that such assumption for FirstId and LastId will miss all deletes on ‘beginning’ (all records with id then current max(id)) of the table. It could be improved with checking identity definition for seed and current value.
Comment editor cut my comment:
It’s worth to mention that such assumption for FirstId and LastId will miss all deletes on ‘beginning’ (all records id < min(id)) and on the ‘end’ (all records with id > current max(id)) of the table. It could be improved with checking identity definition for seed and current value.