By: Pablo Echeverria | Comments (14) | Related: More > Import and Export
Problem
You need to copy a table from one SQL Server database to another, so what options are there, and which options are more efficient in different circumstances?
Solution
To conduct the testing for this tip, I searched for the biggest database I could find on a server using EXEC [sp_databases] and I found one that is 146 GB. Then, I searched in [sys].[dm_db_partition_stats] to find the largest table in the database. I found one with 13 million rows that is 14.8 GB in size, so each row is 0.001 MB in size.
The next step for testing is to create the destination database. To create the database using SQL Server Management Studio (SSMS), right-click on "Databases" and select "New Database…". I left the default options, but you can create it with 15 GB of initial size and 1 GB of growth. I also left the recovery model as "simple" to avoid a log file growth.
We will test four different methods in this tip to copy a table from one SQL Server database to another:
- Using a linked server
- Using PowerShell and dbatools-io
- Using SSIS
- Using backup and restore
Using a Linked Server to Copy a SQL Server Table to Another Server
This approach assumes there is communication between server-A and server-B. Using SQL Server Management Studio for server-A, go to "Server Objects", then "Linked Servers", right-click, and select "New Linked Server…". In the name, enter the real name of server-B, in "Server Type" select "SQL Server" (note this can be changed to "Other data source" for other DBMS), in "Security" select "Be made using the login's current security context" and in "Server Options" make sure "RPC" and "RPC Out" are set to "True".
Then you need to create the destination database in server-B as described earlier. Next, to create the destination table in server-B using SQL Server Management Studio, I searched in server-A for the table, right-clicked on it, select "Script Table as" then "CREATE To" and finally "Clipboard". Then I ran this script on server-B in the new database I just created.
To copy the data, you can run a query like this in server-A:
INSERT INTO [SERVERB].[tmp].[dbo].[a_w] (<columnA>,<columnB>,…) SELECT <columnA>,<columnB>,… FROM [source].[dbo].[a_w]
Note that SERVERB is the name of the linked server. Also, I had to specify the column names, because there was a column of type TIMESTAMP that doesn't allow values to be specified. Because this table has 241 columns, I used the "Find-Replace" functionality of SSMS to make this easier.
Before the command has finished, you can count the number of rows in server-B using a query like this:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT COUNT(1) FROM [tmp].[dbo].[a_w]
You can track the resource usage with "Task Manager" in both server-A and server-B. I notice the memory remains the same that SQL Server had assigned, and the CPU and network show normal usage. You can also track the query stats using sp_WhoIsActive:
On the source server, here are the statistics:
- There was one connection and no transaction started
- Consumed 9.5 hours of CPU time
- Performed 71 million reads
- 2 million writes
- 3 million physical reads
- Consumed 14 GB in tempdb
The execution plan is as follows:
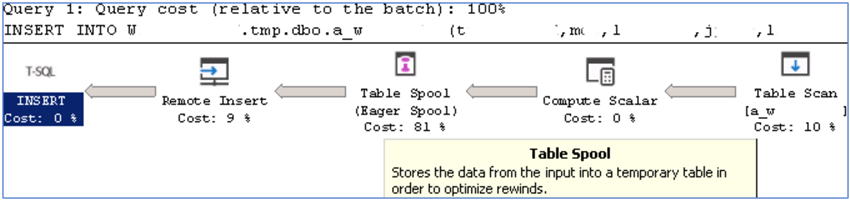
On the target server, here are the statistics:
- There was one connection and one transaction started
- Consumed 4.6 hours of CPU time
- Performed 35 million reads
- 1.5 million writes
- 1400 physical reads
- Consumed 0 GB in tempdb
When the command finished executing, the time elapsed was 10.5 hours, so this means it took 0.003 seconds to transfer each row (counting store of the row in tempdb, network transfer, and insert into the destination table). Viewing this from a different perspective, every second 343 rows (0.4 MB) were transferred.
Based on these results, even when this is the easiest method to set up, we can see clearly this is not the best option to transfer large amounts of data, because the data started being transferred row by row to the destination server in a single thread, and because the network speed between the two servers is on average 15 MB/sec and we only used 2.6% of it.
Using PowerShell and dbatools-io to Copy a SQL Server Table to Another Server
This method assumes there is communication between an app-server to server-A and the same app-server to server-B, and also requires you to have installed dbatools.io on the app-server, here is a link that will help you with the installation. You also need to create the destination database and the destination table on server-B as described earlier.
Once this has been set up, you can issue a PowerShell command like this to copy the rows:
Copy-DbaDbTableData -SqlInstance SERVERA -Database tmp -Table dbo.a_w -Destination SERVERB -DestinationDatabase tmp
You can track the resource usage with "Task Manager" in the app-server, server-A and server-B. I didn't notice any spike in the memory, and the CPU and network show normal usage.
On the source server, here are the statistics:
- There was one connection and no transaction started
- Consumed 116 seconds of CPU time
- Performed 2 million reads
- 0 writes
- 2 million physical reads
- Consumed 0 GB in tempdb
The execution plan is as follows:
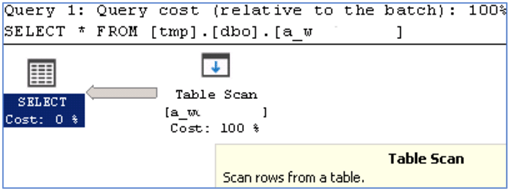
On the target server, here are the statistics:
- There was one connection and 2 open transactions
- Consumed 142 seconds of CPU time
- Performed 1 million reads
- 0.5 million writes
- 0 physical reads
- Consumed 0 GB in tempdb
The execution plan is as follows:
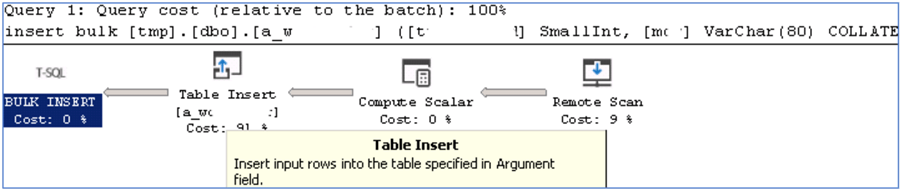
After it has finished running, I verified it copied 13 million rows and the elapsed time was 15 minutes 18 seconds, so this means it took 0.00007 seconds to transfer each row (counting network transfer and insert in destination table). Viewing this from a different perspective, every second 14160 rows (16.5 MB) were transferred, which is the average network bandwidth.
Based on these results, this method was the easiest to set up (only if dbatools-io is already installed) and is a very good candidate to transfer large amounts of data, because it is using bulk copy in a streaming way, so it is the fastest and least resource-intensive. Here is the documentation for this PowerShell function, and it has also options to specify a query and change the batch size to improve the performance further, among many other options. The only thing it can't do is transformations, so you would need to add other PowerShell commands to achieve this, which can get cumbersome.
Using SSIS to Copy a SQL Server Table to Another Server
This method assumes there is communication between an app-server (that has Visual Studio with SSDT tools installed) to server-A and the same app-server to server-B. You also need to create the destination database and the destination table in server-B as described earlier.
Once this has been done, you can create a SSIS solution as follows:
- Open "Visual Studio with SSDT tools", go to File > New > Project…, go to Templates > Business Intelligence > Integration Services and choose "Integration Services Project".
- In "Package.dtsx", in the "Control Flow" tab, add a "Data Flow Task". Inside this "Data Flow Task", using the "Source Assistant" create a connection to the source server, and using the "Destination Assistant" create a connection to the target server. This will add the required components in "Connection Managers" and will also add the components in the data flow.
- Open the "OLE DB Source" and change the following:
- Select the name of the table from where you want to copy the data.
- In the "Columns" tab, uncheck the column of TIMESTAMP datatype, if you have one.
- Connect the output of the "OLE DB Source" to the input of the "OLE DB Destination".
- Open the "OLE DB Destination" and change the following:
- Select the name of the table where the records are going to get inserted.
- Make sure the "Table lock" is checked, to avoid row locking at any time.
- Make sure the "Check constraints" is unchecked (unless you want them to be checked, but this will slow down the process).
- Specify the "Rows per batch" as 5000 to match the test done with dbatools-io. This can be tuned depending on the performance you obtain.
- Make sure the "Maximum insert commit size" is the maximum, unless you want commits more often, but this will slow down the process.
- Go to the "Mappings" tab and make sure the mappings are correct between source and target.
Then you can click on "Start" to start the process, it will keep displaying the current number of rows that have been processed, like in the image below:
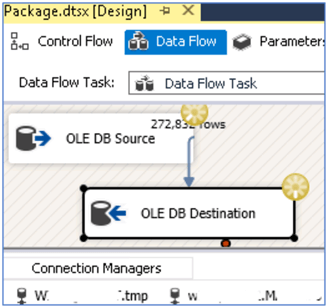
You can track the resource usage with "Task Manager" in the app-server, server-A and server-B. I didn't notice any spike in the memory, and the CPU and network show normal usage.
On the source server, here are the statistics:
- There was one connection and no transaction started
- Consumed 137 seconds of CPU time
- Performed 2 million reads
- 0 writes
- 2 million physical reads
- Consumed 0 GB in tempdb
The execution plan is as follows:
On the target server, here are the statistics:
- There was one connection and 2 open transactions
- Consumed 672 seconds of CPU time
- Performed 25 million reads
- 2 million writes
- 2600 physical reads
- Consumed 0 GB in tempdb
The execution plan is as follows:
After the package has finished running, I verified it copied 13 million rows and the elapsed time was 18 minutes 5 seconds, so this means it took 0.00008 seconds to transfer each row (counting network transfer and insert in destination table). Viewing this from a different perspective, every second 12000 rows (14 MB) were transferred, very close to the average network bandwidth.
The differences between this method and dbatools-io are:
- I have dbatools-io installed in server-A, so there was no transfer between this server and the app-server, and this was one of the reasons it was faster.
- This test was done inside Visual Studio with debugging enabled; once the package gets deployed, it will run several times faster.
- In the target server it consumed 5 times more CPU, performed 25 times more reads, 4 times more writes, and 2600 physical reads vs 0 in dbatools-io. I don't have a reason why SSIS does this, but this is one of the reasons it was slower.
Based on these results, this method is a very good candidate to transfer large amounts of data, because it is using bulk copy in a streaming way, so it is very fast and less resource-intensive. This method allows you to create transformations to build a true ETL solution. This also allows you to create Control Flows in parallel, so this process can be improved further. And for non-SQL Server databases, this will also be the preferred option.
Using Backup and Restore to Copy a SQL Server Table to Another Server
You can copy the data to a temporary table in a new database in server-A, then backup this database and restore it in the destination server, and finally move the data from the restored database into the real destination table.
Create Temporary Database and Copy Table to Temporary Database
You need to create the destination database in server-A as described earlier, but there's no need to create the destination table because you will issue a command like this:
SELECT * INTO [tmp].[dbo].[a_w] FROM [source].[dbo].[a_w]
Notice you don't need to specify the columns excluding the one with TIMESTAMP datatype. After running the command, I verified it finished in 1 minute 58 seconds.
Looking at the statistics:
- There was one connection and two open transactions
- Consumed 232 seconds of CPU time
- Performed 2795 reads
- 3 writes
- 0 physical reads
- Consumed 0 GB in tempdb
The execution plan is as follows:
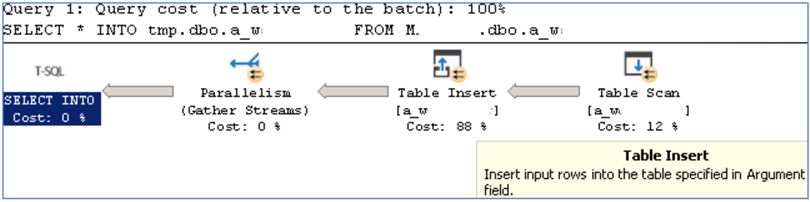
This explains why it took only a couple of minutes to copy all the data, thanks to the parallelism.
Backup the Temporary Database, Transfer and Restore to Other Server
Then you can run commands like the one's below to backup the database, copy the file and restore the database in the destination server:
BACKUP DATABASE [tmp] TO DISK = N'C:\tmp.bak' WITH COPY_ONLY, NOFORMAT, NOINIT, NAME = N'tmp-Full Database Backup', SKIP, NOREWIND, NOUNLOAD EXEC xp_cmdshell 'copy "C:\tmp.bak" "\\SERVERB\C$\tmp.bak"' EXEC xp_cmdshell 'sqlcmd -S SERVERB -Q "RESTORE DATABASE [tmp] FROM DISK=''C:\tmp.bak'' WITH FILE=1, MOVE N''tmp'' TO N''C:\DATA\tmp.mdf'', MOVE N''tmp_log'' TO N''C:\Log\tmp_log.ldf'', NOUNLOAD"'
After running it, I verified it finished in 2 minutes 14 seconds, because the backup is compressed and this table has a lot of repeating values, so it had a size of only 0.75 GB.
Copy Table to Existing Database on Another Server
Finally, you can transfer the rows back to the real destination database; I expect this to take another 1 minute 58 seconds, so this makes a total of 6 minutes 10 seconds.
SELECT * INTO [dbo].[a_w] FROM [tmp].[dbo].[a_w]
Copy Comparisons
This last option is 100 times faster than using a linked server and 2.5 times faster than using dbatools-io and SSIS, but requires you to know the drives in server-A and server-B and the data and log paths for SQL Server in server-B. You can speed up the backup process by specifying multiple destination files, multiple drives, an attached fast access drive, or increasing the buffer size to use 100% of the CPU in this backup, so for very large databases this would be the preferred option. Also, this option allows you to transfer data to a server that doesn't have a network connection (or it is too slow to transfer through it), or restore the data in multiple servers at once, but can't be done across DBMS's.
Other Methods to Copy SQL Server Data
Even when there are other options, those are not suitable because of the following:
- BCP: here is the documentation of this program, you can see you need to create an output file (or several output files), an output description file, know the types of the columns, etc. so it requires a lot of development effort and if you specify several output files to parallelize the work, you will need a lot of time setting it up and testing it.
- OPENQUERY: here is the documentation of this command, you can see it requires a linked server, so the performance will be similar to the option already described earlier.
- SSIS wizard: this is the program named "SQL Server Import and Export Data" that comes when you install SQL Server; this creates a lightweight SSIS package that can be run immediately or can be stored as an Integration Services package for further execution, but doesn't allow you to specify advanced options, so it is better to use the SSIS solution described above.
- Script out in SSMS: this is the option that appears when you right-click a database in SSMS, then select "Tasks" > "Generate Scripts…", then select the tables you want to export, the output file, and in "Advanced" specify in "Types of data to script" as "Data only". But this will generate an INSERT statement for each row as text, so this file will be huge, and you can't include BLOB columns. A full database backup occupies less space than this script, so this option is only suitable for very small number of rows.
- Custom script to build INSERT statements: this has the same problem as the above.
- PowerShell, Python, .Net: the time you will spend building your own solution, testing, validating, doing integration tests, debugging parallel threads, etc. will be several times greater than using any of the other solutions described above, unless you're planning to sell your program and you can prove, before writing a single line of code, it will have a greater performance than any other solution.
Next Steps
- Please let us know in the comments what is your preferred option, and the performance you're obtaining from it.
- Check this link for other options to improve the performance of the table copy.
- Check this link for other options to improve the performance using parallelism.
- Check this link on how to use sp_WhoIsActive.
- Check this link on how to set up dbatools-io.
- Check this link on how to create SSIS solutions.
- Check the following links on how to backup and restore databases.






About the author
 Pablo Echeverria is a talented database administrator and C#.Net software developer since 2006. Pablo wrote the book "Hands-on data virtualization with Polybase". He is also talented at tuning long-running queries in Oracle and SQL Server, reducing the execution time to milliseconds and the resource usage up to 10%. He loves learning and connecting new technologies providing expert-level insight as well as being proficient with scripting languages like PowerShell and bash. You can find several Oracle-related tips in his LinkedIn profile.
Pablo Echeverria is a talented database administrator and C#.Net software developer since 2006. Pablo wrote the book "Hands-on data virtualization with Polybase". He is also talented at tuning long-running queries in Oracle and SQL Server, reducing the execution time to milliseconds and the resource usage up to 10%. He loves learning and connecting new technologies providing expert-level insight as well as being proficient with scripting languages like PowerShell and bash. You can find several Oracle-related tips in his LinkedIn profile.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
