
When Microsoft released SQL Server 2012, they introduced the SQL Server Analysis Services (SSAS) tabular model, an in-memory database that uses the xVelocity analytics engine and state-of-the-art compression algorithms. You can think of the tabular model as a cross between a SQL Server relational database and an SSAS multidimensional cube. Like a database, the tabular model supports tables and their relationships. Like a cube, the model also supports measures and key performance indicators (KPIs). Together these elements create a database that is fast and efficient and can deliver self-service business intelligence (BI) to a variety of applications, including Excel, PowerPivot, Power View and SQL Server Reporting Services (SSRS).
Since the release of SQL Server 2012, much has been written about how to use SQL Server Data Tools (SSDT) to create a tabular model and deploy it to an instance of SSAS in tabular mode. What has not garnered nearly as much attention is what to do with a tabular database once it’s been deployed. And that’s where this article comes in. We’ll introduce you to the tabular model through the eyes of SQL Server Management Studio (SSMS). You’ll learn about the components that make up a tabular database and the methods available to connect to the database to retrieve its data. Our plan is for this to be the first of a series of articles about accessing a tabular database deployed to an SSAS instance. But first we must start with the basics.
Working with a Tabular Database
After a tabular database has been deployed to an SSAS tabular instance, you can use SSMS to connect to that instance and its databases. However, before we start looking at SSMS, we need to provide a bit of setup information. To demonstrate the various concepts in this article, we deployed the AdventureWorks Tabular Model SQL 2012 sample database to a local instance of SSAS in tabular mode. If you want to do so as well, you’ll need several components in place:
- An instance of the SQL Server 2012 database engine with the
AdventureWorksDW2012database installed. You can download the database from the AdventureWorks CodePlex site. - An instance of SSAS 2012 installed in tabular mode. For information about setting up SSAS in tabular mode, see the MSDN topic “Install Analysis Services in Tabular Mode.”
- The SSDT project
AdventureWorksTabularModelSQLServer2012, which you use to deploy theAdventureWorksTabularModelSQL2012tabular database to the SSAS instance. You download the project from the same AdventureWorks CodePlex site where you download the data warehouse. For details about how to set up the project in SSDT, configure the necessary settings, and deploy the database, see the TechNet article “SQL Server Samples Readme.”
Once you get all the pieces in place and the AdventureWorks Tabular Model SQL 2012 database deployed to the SSAS instance, open SSMS and connect to that instance. Then, in Object Explorer, expand the Databases node to display the database. If you find it listed there, you’re good to go.
The Tabular Database in SSMS
In SSMS, you can manage your tabular databases as well as query the data in them. However, as you’ll quickly discover, the options you have in SSMS for managing a database are quite limited compared to what’s available for relational databases-or even SSAS multidimensional databases. When it comes to the tabular model, Microsoft sees SSDT as the primary tool for most data-definition type operations, the idea being that you redeploy, rather than making changes on the fly. That said, for many of the basic administrative operations, SSMS is more than adequate, and it provides an easy way to view the data, which is just as important, if not more.
So now that you’ve been forewarned, let’s take a closer look at our database in Object Explorer. Figure 1 shows Object Explorer with all nodes of the AdventureWorks Tabular Model SQL 2012 database expanded. As you can see, there are three primary nodes beneath the database listing: Connections, Tables, and Roles.
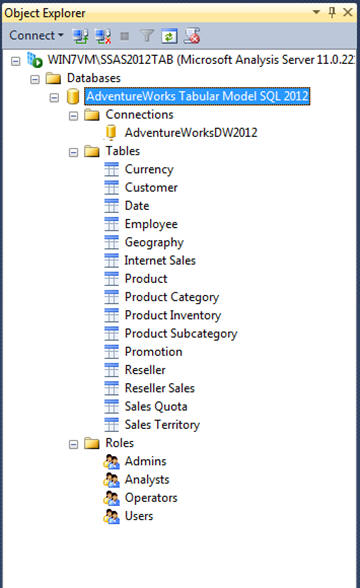
Figure 1: Viewing a tabular database in Object Explorer
Let’s start with the database node. By right-clicking this node, you can perform a number of tasks, such as processing, restoring, browsing, and detaching the database. You can also access the database properties, which let you configure a number of database settings. Figure 2 shows the Properties dialog box, opened to the Database page. The database shown here is, of course, AdventureWorks Tabular Model SQL 2012.
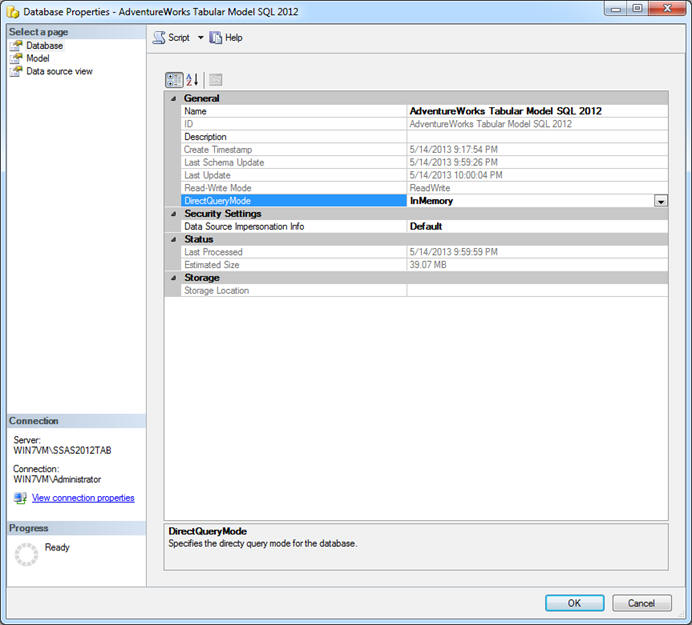
Figure 2: Accessing the database’s properties
There are only a few settings you can actually change: Name, DirectQueryMode, and Data Source Impersonation Info. On the Model page, you can change a couple options related to the processing mode, and on the Data source view page, you can change none of the settings. However, each page also provides details about the database and its current state, which might be useful information to have at times.
Of the few options you can set in the Properties dialog box, the one you should probably be most aware of is DirectQueryMode. When a database is set in DirectQuery mode, it retrieves data directly from a relational data source. This can be advantageous when the dataset is too large to fit into memory or you want to guarantee you have the most up-to-date data. However, DirectQuery mode has a number of limitations. For instance, you can retrieve data from a single relational data source only. By default, DirectQuery mode is turned off, unless you explicitly enable it either here or when you’re creating or deploying your model.
Moving down the database tree in Object Explorer we find the Connections node. Beneath this node are the connections to the model’s data sources. A tabular database, when not in DirectQuery mode, can retrieve data from one or more different types of data sources, such as SQL Server or Oracle relational databases, Excel or text files, other SSAS databases, PowerPivot workbooks, and a variety of data feeds. In this case, the AdventureWorks Tabular Model SQL 2012 database has been set up with only one connection-the AdventureWorksDW2012 database on a local instance of the SQL Server database engine. (Note that we changed the connection name from the original in the SSDT project just to simplify it a bit.)
In SSMS, you can access the properties for each connection, where you can modify the connection string, select the isolation level, change the impersonation settings, and configure a couple other properties. You can view a few additional property settings as well, such as the source database name and the date and time the connection was created.
However, you cannot add or delete connections in SSMS. To do so, you need to open the project in SSDT, make your changes, and redeploy the database. In fact, you’ll find that for most changes of this nature, you’ll need to return to the SSDT project to implement them and redeploy the database. After you’ve deployed the project the first time, subsequent deployments aren’t too bad, depending on the amount of data that needs to be reprocessed (reloaded into the tables).
Continuing down our database tree, we come to the Tables node, where you’ll find a list of the tables in the database. By right-clicking a table, you can process the data in that table or access the table’s properties, but you cannot change any of those properties. You can only view them. However, you can configure the table’s partitions. In a tabular database, partitions divide a table into logical parts that can be processed independently of each other. For example, Figure 3 shows the partitions that have been created on the Internet Sales table. In this case, the data is separated based on the sales date. Notice that you can use the Partitions dialog box to add, remove, edit, and process partitions, probably one of the more robust tabular features in SSMS.
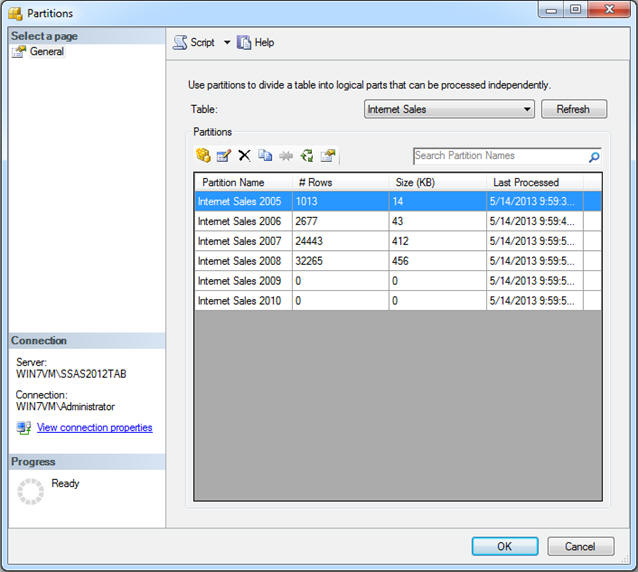
Figure 3: Configuring a table’s partitions
There’s not much else you can do with the tables listed in Object Explorer. In fact, you won’t even find many details about them, not even their column names. For that, we’ll need to open another window, which we’ll be discussing shortly. In the meantime, let’s move down our database tree to the Roles node.
Roles define how permissions are assigned to users accessing the database. Users assigned to a particular role are granted the permissions that have been granted to that role. In SSMS, you can add and delete roles, as well as configure the existing ones. You can also add users to or remove them from a role.
What makes roles particularly interesting is that you can set up row filters on a role. A row filter specifies which rows in a table can be queried by a role’s members. You can assign filters to any of tables in the database, one filter per table. The filters are Data Analysis Expressions (DAX) formulas that evaluate to true or false, thus determining what data users can access.
Viewing the Tabular Objects
Up to this point, we’ve focused on the information you can view in Object Explorer. There’s not a lot there, unfortunately. However, a quick and easy way to view more database details is to open a Multidimensional Expressions (MDX) query window (by clicking the Analysis Services MDX Query button on the tool bar). When the window appears, you’ll find a pane on the left side, complete with a list of all the objects in the selected database, as shown in Figure 4. We’ve expanded several of the nodes to help demonstrate some of the concepts.
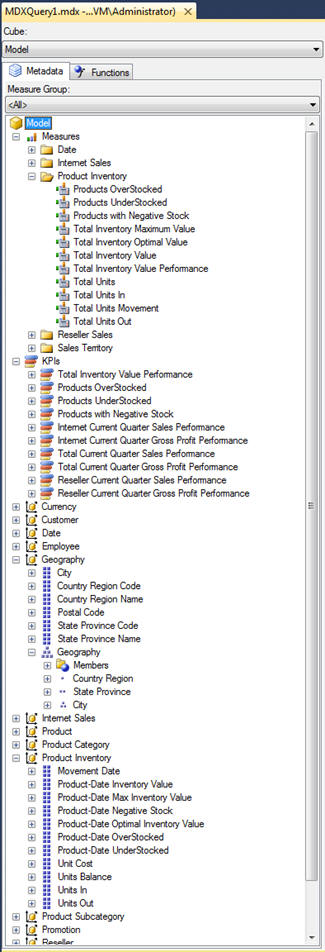
Figure 4: Viewing database objects in an MDX query window
Notice that the tables we saw in Object Explorer are listed here, along with their columns, as well as a number of other object types. The following bullets provide an overview of each of these types, as they relate to what’s shown in Figure 4:
- Cubes: At the top of Figure 4, you’ll see the
Cubelabel. SSAS uses this term to refer to the model as a whole (as represented by theModeloption) or to refer to perspectives, which are subsets of a model that target a particular functional area, such as the inventory. You can select either the entire model or one of the perspectives from theCubedrop-down list. The object tree will display the objects associated with the model or perspective you select. - Measures: A measure is a calculation that can be applied to different levels of grouped data in order to aggregate that data. For example, you might have a measure that aggregates sales totals, calculated at the city, state, and country levels, all within a single report. Figure 4 shows the measures associated with the
ProductInventorytable. - KPIs: In a tabular database, a KPI is a performance measurement that provides a quick summary of the state of a specific aspect of the data. For example, a KPI might indicate whether the current sales are hitting their projected goals.
- Tables: A table in a tabular database is made up of columns, and those columns are made up of members-the data values stored in that column. In Figure 4, for example, you can see the columns associated with the
Geographytable. If you were to expand any of those columns, you would find the column’s members. Some columns can be calculated columns, in which the column’s values are derived from a DAX expression. However, there’s no obvious way to tell within SSMS which columns are calculated and which come straight from the data source. For that, you need to return to your SSDT project or generate a database script and start searching. - Hierarchies: In Figure 4, you’ll notice that the
Geographytable contains an element at the column level namedGeography. This is a hierarchy. A hierarchy defines a relationship between two or more columns in order to show how the data is connected. For example, theGeographyhierarchy is based on theCountryRegion,StateProvince, andCitycolumns, withCountryRegionat the top of the hierarchy andCityat the bottom. In other words, a country can contain states, and a state can contain cities. - Relationships: A tabular database, like a relational database, supports foreign key relationships between tables. For example, a foreign key relationship exists between the
ProductInventoryandProductCategorytables. However, the object tree doesn’t reflect those relationships, and the only easy way to discover them is to return once again to the SSDT project.
One other item worth noting. If you were to query the Product Inventory table, you would discover two columns in your result set that do now show up in the object tree: the ProductKey and DateKey columns. The object tree does not list key columns with their tables. Although these are most often surrogate keys, you should know they’re there in case you ever need to reference them in a DAX or MDX expression.
Accessing Tabular Data
Now we get to the real heart of this series: accessing a tabular database and retrieving its data. In the articles to follow, we’ll get into the nitty-gritty of database access. Until then, it can help to have an overview of the options available to you. This will also provide you with a roadmap of sorts of where we hope to be heading. So let’s start by reviewing the ways we can connect to a tabular database on an SSAS tabular instance
Several of Microsoft’s client programs now support native connections to an SSAS tabular instance. The first of these you’re likely to use is SSMS. As you’ve seen in this article, you can use SSMS to view the various database components and their properties, as well as configure a limited number of settings. If you’re new to SSAS in tabular mode and to tabular databases in general, SSMS is a good place to start. Even if your building a tabular database from scratch, SSMS ensures that you have access to an SSAS tabular instance and everything appears to be up and running.
Once you deploy a tabular database, you can browse its data in SSMS by right-clicking the database in Object Explorer and then clicking Browse. This opens a window that lets you view the database objects and retrieve data based on those objects. To view data, simply drag the columns and measures you want to view into the main work surface. You can also define filters in the top pane. For example, Figure 5 shows the data from several columns in the Geography table as well as the Internet Total Sales measure. In addition, a filter has also been defined to limit the results to European countries.
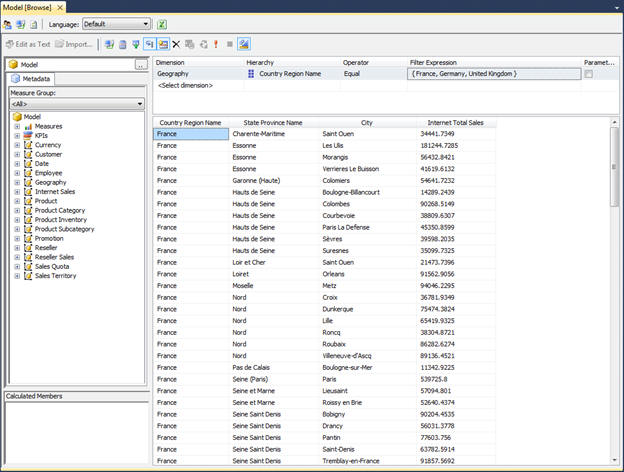
Figure 5: Browsing data in a tabular databases
Note that the cube browsing capabilities are not as robust as they are in previous SSAS versions, specifically with regard to being able to create a pivot table. Microsoft instead wants you to use Excel for this functionality. In fact, you might have noticed the Analyze in Excel button near the top of the browser window. This opens your model as a pivot table in Excel. Of course, those without Excel installed on their machines are out of luck.
Another option you have for viewing tabular data within SSMS is to use the MDX query window to write a query that retrieves the data you need. Note, however, you can use this window to write DAX queries as well. (Currently, there is no DAX-specific query window available in SSMS.) For example, Figure 6 shows a simple DAX query that retrieves all data in the Product Inventory table. When you run the query, the results are displayed in the lower pane, much like data in an Excel worksheet.
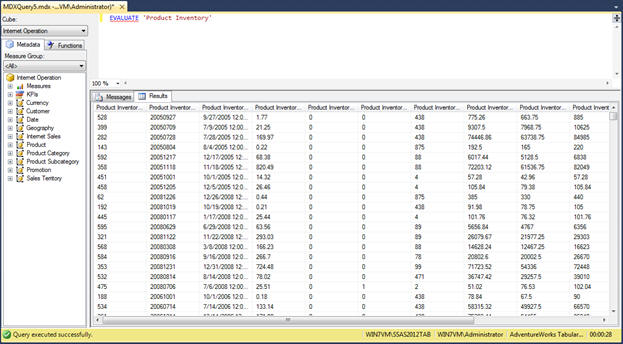
Figure 6: Running a DAX query to retrieve data from a table
You can use either MDX or DAX to query tabular data, unless you’ve configured the database to run in DirectQuery mode, in which case you can use DAX only. Later in the series, we’ll go into more detail about how to write queries to retrieve the data you want to return. If you create your own tabular databases in SSDT, you’ll likely use DAX to create measures, calculated columns, and PKIs, so you might already be familiar with how to write DAX expressions. What’s also worth noting about SSDT is that you can connect to an SSAS tabular instance from within your tabular project. Not only can you deploy an SSDT tabular model to the SSAS instance, but you can also use a tabular database as one of your database’s sources.
In addition, you access tabular data from your SSRS reports, whether you create them in an SSDT project or within the Report Builder client application. Plus, you can connect to an SSAS tabular instance from Excel, PowerPivot, and Power View. SQL Server Integration Services (SSIS) also lets you connect to a SSAS tabular data source, and you can manage tabular instances from within PowerShell.
Clearly, there are plenty of Microsoft applications that let you connect to an SSAS tabular instance and access the data. And if that’s not enough, Microsoft provides a number of programming interfaces for those building their own applications:
- Analysis Management Objects (AMO) to manage a running instance of SSAS.
- ADOMD.NET to access tabular data and metadata from a managed application.
- SSAS OLE DB Provider to access tabular data from an unmanaged application.
- The XML for Analysis (XMLA) open standard that facilitates communication between SSAS data sources and client applications.
The Tabular Shift
You should now have some idea of what the tabular model looks like in SSMS and some of the options for connecting to that model. As we continue with this series, we’ll dig more thoroughly into the various ways you can access tabular data, with a focus particularly on DAX and the Microsoft client applications. In addition, as part of learning how to access tabular data, we’ll also delve deeper into the various components that make up a tabular database. But if you start with this article, you should have a reasonable foundation on which to build, and you’ll also know how we’ve set up our test environment to facilitate our data access. In future articles, we plan to use this same setup, so don’t blow it away if you don’t need to. In the meantime, get comfortable with accessing the tabular database from within SSMS. The better you understand how all the pieces fit together, the more you can get out of your data when you’re ready to start retrieving tabular data.


