
The series so far:
- Introduction to DAX for paginated reports
- How to filter DAX for paginated reports
- DAX table functions for paginated reports: Part 1
- DAX table functions for paginated reports: Part 2
- Tips and tricks with DAX table functions in paginated reports
In the previous articles, you learned – or revised – the basics of using DAX as the query language to populate paginated reports with data from Power BI datasets. However, as befitted an introduction, the focus was essentially on getting up and running. Specifically, the only DAX table function you looked at was SUMMARIZECOLUMNS().
Despite its undeniable usefulness, this function is far from the only DAX function that you can use to query Power BI Datasets when creating Paginated Reports. Moreover, it has limitations when you wish to deliver complete lists of results as it is an aggregation function. This means, for instance, that you will never find duplicate records in the tabular output from SUMMARIZECOLUMNS() as, by default, it is grouping data. Alternatively, if you wish to use SUMMARIZECOLUMNS() to output data at its most granular level, you will need to include a unique field (or a combination of fields that guarantee uniqueness) – even if these are not used in the report output.
It follows that, to extract data in ways that allow effective report creation, it is essential to learn to use a whole range of DAX table functions. This article covers:
- SELECTCOLUMNS
- SUMMARIZE
- GROUPBY
- ADDCOLUMNS
As well as these core table functions, it also helps to understand the DEFINE, EVALUATE and MEASURE functions as well as the use of variables in DAX queries when returning data to paginated reports.
The purpose of this article (and the following one) is to introduce you, as a Paginated Report developer, to the collection of DAX functions that range from the marginally useful to the absolutely essential when returning data to paginated reports from Power BI. Once again, I am presuming that you are not a battle-hardened DAX developer. While you may have some experience developing DAX measures in Power BI Desktop, you now need to extend your DAX knowledge to extract data in a tabular format from a Power BI dataset so that you can use the output in paginated reports.
At this point, it is entirely reasonable to wonder why you should ever need anything more than SUMMARIZECOLUMNS() to return data from a Power BI dataset. After all, it is the standard function used by the Power BI Report Builder and works perfectly well in many cases.
While being suitable for many output datasets, SUMMARIZECOLUMNS() is essentially an aggregation function. In many cases, you may want to return a filtered list (pretty much like a simple SQL SELECT query) rather than a GROUP BY SQL query which is what SUMMARIZECOLUMNS() delivers.
There are also some data output challenges that require other DAX functions – or indeed, combinations of DAX functions – to return the required data. A grasp of the wider suite of DAX table functions will leave you better armed to answer a range of potential challenges when creating paginated reports.
Many DAX table functions have quirks and limitations that can trip up the unwary user in certain circumstances. However, the aim of these two articles is not to provide an exhaustive discussion of every available function and the hidden depths and rarer aspects of each one. Rather, the intention is to provide developers with an initial overview of the core tools that you will inevitably need to extract data for paginated reports from a Power BI dataset.
EVALUATE
If your requirements are as simple as returning the complete contents of a table from the source Power BI dataset to a paginated report, then you can simply use the EVALUATE keyword, like this:
|
1 2 |
EVALUATE FactSales |
The output from the sample dataset is as shown below:
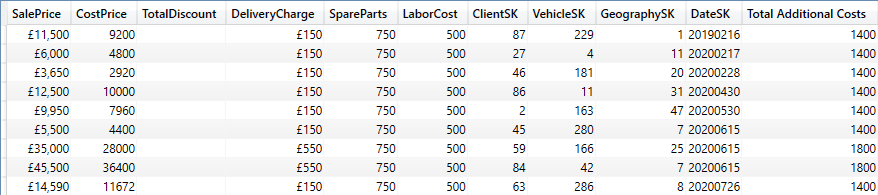
Indeed, this principle can be extended to reduce the output from a single table by enclosing the table to evaluate in a FILTER() function, like this:
|
1 2 3 4 5 |
EVALUATE FILTER( FactSales ,FactSales[CostPrice] > 50000 ) |
The output (shortened) is as shown in the following image:
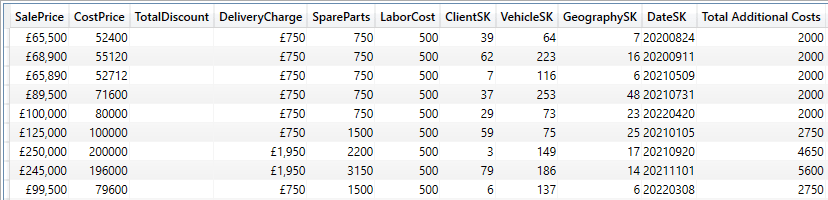
Indeed, you can even filter using values from other tables if you include the RELATED() function inside the FILTER() – much as you would use it when creating calculated columns in a table that need to refer to other tables’ data. You can see this in the following piece of DAX:
|
1 2 3 4 5 |
EVALUATE FILTER( FactSales ,RELATED(DimGeography[CountryName]) = "FRANCE" ) |
Sample output is as shown in the following image (where the Geography_SKs only relate to France):

This method means that you can use the full breadth of the data model to filter data even when resorting to the simplest possible DAX.
Note: You need to be aware at this point that you cannot display the filtered field using a simple EVALUATE function. However, you can see the field that you are filtering on if you use SELECTCOLUMNS() –as is explained in a following section.
When using a FILTER() function inside EVALUATE the filtering rules are similar to those described in the previous articles in this series. However, you need to be aware that:
- Unlike when filtering inside
SUMMARIZECOLUMNS(), the table that you are evaluating is, by definition, the filtered object (so there is no need to use VALUES(<tablename>) approach that you used when filtering inside aSUMMARIZECOLUMNS()function). - You can only filter on a single column per
FILTER()keyword. Consequently multiple filter elements require nested filters – like in this example, where I have added an OR condition for good measure):
|
1 2 3 4 5 6 7 |
EVALUATE FILTER( FILTER( FactSales ,RELATED(DimGeography[CountryName]) = "FRANCE") ,RELATED(DimVehicle[Make]) = "Rolls Royce" || RELATED(DimVehicle[Make]) = "Jaguar") |
The output (shortened again) is as shown in the following image:

SELECTCOLUMNS() – Used to Return Data from a Single Table
The next DAX table function that delivers non-aggregated output is SELECTCOLUMNS(). This function can be very useful when producing fairly simple lists of fields. After all, this is what paginated reports good at delivering, and may be one of the fundamental reasons that you are using paginated reports rather than Power BI to produce a specific report.
You can use SELECTCOLUMNS() to:
- Build a custom subset of required columns from a table without any aggregation applied.
- Change column names.
- Apply columns of calculations.
As an example, take a look at the following short piece of DAX, which shows the key attributes of the SELECTCOLUMNS() function:
|
1 2 3 4 5 6 7 8 |
EVALUATE SELECTCOLUMNS ( DimVehicle ,"Make", [Make] ,"Model", [Model] ,"Variant", [ModelVariant] ) |
A subset of the output is as shown in the following image (note that there are many records without a model variant, so you will need to scroll to the bottom of the dataset to see the variant detail):
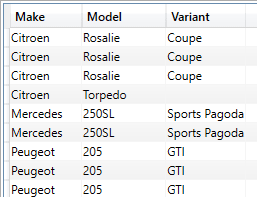
The key points to note are that:
- The first element of
SELECTCOLUMNS()is the table that you want to return data from. - All the remaining elements are output name/source column pairs.
- The column name to use in the output must be supplied, must be in double-quotes, and can contain spaces.
- You do not have to use fully-qualified field names (table & field) for each output field. The field names themselves must be enclosed in square brackets or double-quotes.
SELECTCOLUMNS()performs no aggregation on the source table.
If, for whatever reason, you want to return distinct values using SELECTCOLUMNS(), then you can wrap SELECTCOLUMNS() inside a DISTINCT() function, like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
EVALUATE DISTINCT ( SELECTCOLUMNS ( DimVehicle ,"Make", [Make] ,"Model", [Model] ,"Variant", [ModelVariant] ) ) |
The output (shortened) is as shown in the following image:
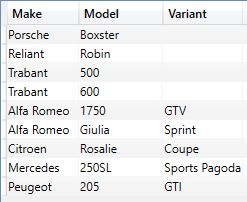
SELECTCOLUMNS() – Used to Return Data from Multiple Tables
Another possible step when outputting lists is to use SELECTCOLUMNS() to return data from multiple tables in the data model. In this respect, SELECTCOLUMNS() is a bit like adding a calculated column in DAX in Power BI in that you have to tell DAX to traverse the dataset if you want to mix and match columns from multiple tables. You can see this in the following DAX snippet:
|
1 2 3 4 5 6 7 8 9 |
EVALUATE SELECTCOLUMNS ( FactSales ,"Make and Model", RELATED(DimVehicle[Make]) & " - " & RELATED(DimVehicle[Model]) ,"Town", RELATED(DimGeography[Town]) ,"Gross Margin", FactSales[SalePrice] - FactSales[CostPrice] ) |
The output (shortened) is as shown in the following image:
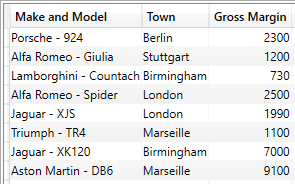
The points of note at this juncture are:
- Use
RELATED() totraverse the dataset - As
RELATED()is used, this can mean that only relatively simple data models can be used. Remember,RELATED()follows an existing many-to-one relationship to fetch the value from the specified column in the related table. In other words, if you have a classic star or snowflake schema, then things could work quite easily. The trick may well be to define the fact table as the “core” table as theSELECTCOLUMNS()first parameter, and any dimensional attributes will useRELATED(). - It is possible to use field names (without qualifying the field name with the table name) only for the fields from the “core” table that is specified as the first element in the
SELECTCOLUMNS()function. - All fields wrapped in the
RELATED()function must be fully qualified (table and field) field names. SELECTCOLUMNS()can also create “calculated columns” in the output as evidenced by the new “Gross Margin” calculation in the DAX above.
I find it useful to think of SELECTCOLUMNS() as something similar to what you can achieve in Power BI Desktop to extend a tabular data subset with merged and calculated columns. It is all about composing and delivering an output dataset from one or more tables in the data model. Also, if you have been using SUMMARIZECOLUMNS() to return data until now, then it is also worth noting that you can add the fields (fields from the core table, fields from related tables and calculations) in any order.
Filtering Output with SELECTCOLUMNS()
You can easily filter the output from a SELECTCOLUMNS() function. The classic approach is to filter the table that is referred to as the first parameter of SELECTCOLUMNS() – like this
|
1 2 3 4 5 6 7 8 9 10 |
EVALUATE SELECTCOLUMNS ( FILTER(FactSales, FactSales[CostPrice] > 50000) ,"Make", RELATED(DimVehicle[Make]) ,"Model", RELATED(DimVehicle[Model]) ,"Town", RELATED(DimGeography[Town]) ,"Selling Price", FactSales[SalePrice] ,FactSales[CostPrice] ) |
The output will look something like the shortened snapshot that you can see below:
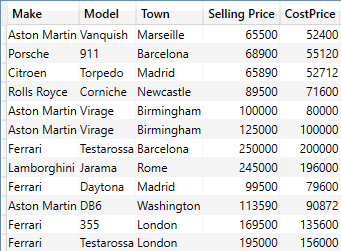
You can, of course, nest logical AND filters by nesting FILTER() functions – like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
EVALUATE SELECTCOLUMNS ( FILTER ( FILTER ( FactSales, FactSales[CostPrice] > 50000 ) ,RELATED(DimVehicle[Make]) = "Bentley" ) ,"Make", RELATED(DimVehicle[Make]) ,"Model", RELATED(DimVehicle[Model]) ,"Town", RELATED(DimGeography[Town]) ,"Selling Price", FactSales[SalePrice] , FactSales[CostPrice] ) |
A subset of the output is as shown in the following image:
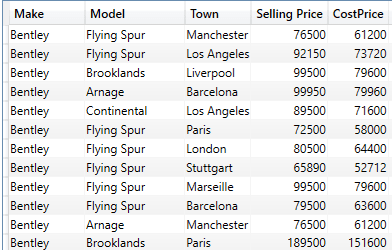
Note that any filters that concern columns not present in the core table must be referred to using RELATED(). Also, you do not, of course, have to display the fields that you are filtering on. I have done this to make the point that the filters are working as expected.
An alternative approach to filtering the data can be to filter the whole output – that is, to wrap the entire SELECTCOLUMNS() function inside a FILTER() function. If you do this, however, the filter can only be applied to a column specified as part of the SELECTCOLUMNS() function. Consequently, this approach can return columns that are not required for the report in the output. An example of this technique is given below:
|
1 2 3 4 5 6 7 8 9 10 11 |
EVALUATE FILTER( SELECTCOLUMNS ( DimVehicle ,"Make", DimVehicle[Make] ,"Model", DimVehicle[Model] ,"Variant", [ModelVariant] ) , ISBLANK([Variant]) ) |
The output (shortened) is as shown in the following image:
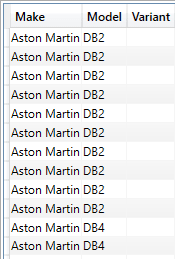
There are a few complexities that it is worth being aware of:
- You need a clear understanding the data model in order to use the
RELATED()function. - Measures can be used with
SELECTCOLUMNS(). - There are many subtleties and variations on the theme of filtering data. Fortunately, filtering datasets returned to paginated reports using
SELECTCOLUMNS()generally only requires the techniques that you saw in the previous article.
SELECTCOLUMNS() is extremely useful when you want to return simplified list output with a reasonable level of data filtering. The ability to rename columns is also an advantage in certain cases.
ADDCOLUMNS()
Another very useful DAX function that you can use to query a Power BI dataset is ADDCOLUMNS(). This is:
- Similar to
SELECTCOLUMNS()– but it extends a data table rather than starting from scratch with a blank output to which you add further selected columns. - Another “Calculated column” approach to extending an existing non-aggregated data table for output to paginated reports.
The following DAX sample illustrates how ADDCOLUMNS() can be used:
|
1 2 3 4 5 6 |
EVALUATE ADDCOLUMNS ( FactSales ,"Gross Profit", FactSales[SalePrice] - FactSales[CostPrice] ) |
The output (shortened) is as shown in the following image:
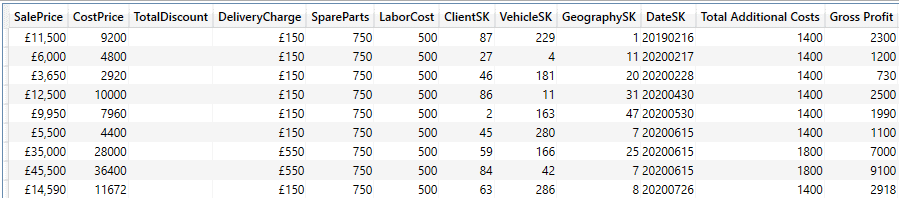
As you can see from the output, this approach returns all the source table elements, plus any others that have been added. If you need the entire table, then this is faster to code. Of course, sending many columns that will never be used in a table across the ether will consume not only bandwidth but also the processing capacity of the Power BI Service, needlessly – and possibly expensively. However, if your data model has tables that lend themselves to being used in their entirety, then ADDCOLUMNS() can be a very useful addition to your paginated report toolkit.
You can, as was the case with SELECTCOLUMNS(), extend the output with fields from other tables using the RELATED() function.
|
1 2 3 4 5 6 7 |
EVALUATE ADDCOLUMNS ( FactSales ,"Town", RELATED(DimGeography[Town]) ,"Gross Profit", FactSales[SalePrice] - FactSales[CostPrice] ) |
The output (shortened) is as shown in the following image:
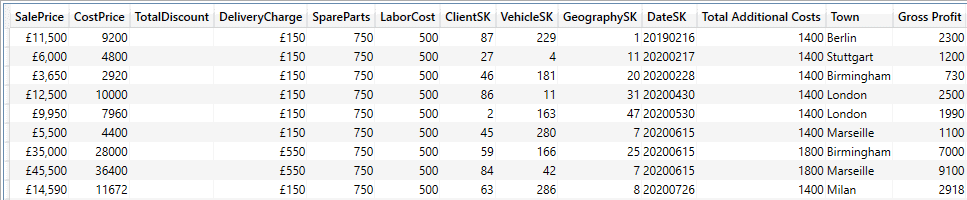
As was the case with SELECTCOLUMNS(), you can add the fields (fields from the core table, fields from related tables and calculations) in any order. Once again, this presumes a coherent and well thought out data model.
Now that you have seen the non-aggregation DAX table functions, it is time to take a look at two other aggregation functions – SUMMARIZE() and GROUPBY().
SUMMARIZE
SUMMARIZE() is considered by many DAX aficionados as having lost its relevance since SUMMARIZECOLUMNS() was introduced. It is, in many respects, an older, quirky and more verbose version of what is now the standard approach to returning aggregated datasets.
This does not preclude the use of this function. However, as you can see from the code sample below, you have to specify a source table when using SUMMARIZE():
|
1 2 3 4 5 6 7 8 9 |
EVALUATE SUMMARIZE( FactSales ,DimCLient[ClientName] ,DimVehicle[Make] ,"Cost", SUM(FactSales[CostPrice]) ,"Sales", SUM(FactSales[SalePrice]) ) ORDER BY DimCLient[ClientName], DimVehicle[Make] |
The output, shown below, is a perfectly valid aggregated table:
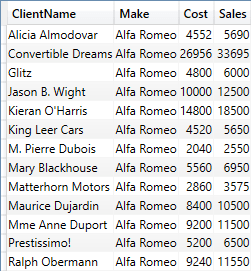
Filtering data using SUMMARIZE() is not difficult, but it does require applying the filter to the table that is used as the source for the SUMMARIZE() function (with all the associated rigmarole of having to use RELATED()) as you can see in the following piece of DAX:
|
1 2 3 4 5 6 7 8 9 10 |
EVALUATE SUMMARIZE( FILTER(FactSales, RELATED(DimGeography[CountryName]) = "France") ,DimCLient[ClientName] ,DimVehicle[Make] ,DimGeography[CountryName] ,"Cost", SUM(FactSales[CostPrice]) ,"Sales", SUM(FactSales[SalePrice]) ) ORDER BY DimCLient[ClientName], DimVehicle[Make] |
You can see the output from this piece of DAX in the following table:
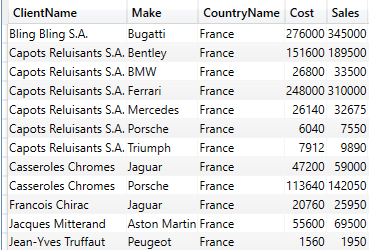
Alternatively, you can wrap the entire SUMMARIZE() function in a CALCULATETABLE() function, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
EVALUATE CALCULATETABLE ( SUMMARIZE ( FactSales ,DimCLient[ClientName] ,DimVehicle[Make] ,"Cost", SUM(FactSales[CostPrice]) ,"Sales", SUM(FactSales[SalePrice]) ) ,DimCLient[ClientName] = "Glitz" ) |
The output to this query is shown below:
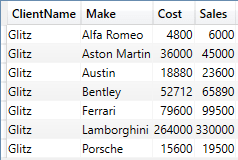
CALCULATETABLE(), of course, will modify the filter context – whereas FILTER() is an iterator function. For paginated reports, modifying the filter context could be largely irrelevant as long as the paginated report dataset is feeding into a single table or chart in the .rdl file. So, in many cases, CALCULATETABLE() could be a simpler way to filter data. And it opens the path to using modifiers (such as ALL(), ALLEXCEPT() etc) to create more complex filters.
Yet another alternative is to wrap the output from a SUMMARIZE() function in one or more FILTER() functions, as you have seen previously. However, this, once again, necessitates adding the column that you will be filtering on to the output from the SUMMARIZE() function.
So, while it is worth knowing that SUMMARIZE() exists, most people prefer to use SUMMARIZECOLUMNS() unless there is a valid reason for not using the more modern function.
GROUPBY
The final major DAX table function used to return data directly is GROUPBY(). Specifically, if you need nested groupings, then GROUPBY() is particularly useful, as this technique is not possible with SUMMARIZE() or SUMMARIZECOLUMNS().
An example of this requirement is finding the lowest average cost price for a car model per make. The following DAX snippet delivers this back to SSRS:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
EVALUATE GROUPBY ( GROUPBY ( FactSales ,DimVehicle[Make] ,DimVehicle[Model] ,"Avg Cost", AVERAGEX(CURRENTGROUP(), FactSales[CostPrice]) ) ,DimVehicle[Make] ,"Minimum Average Cost Per Model", MINX(CURRENTGROUP(), [Avg Cost]) ) |
The complete output is as shown in the following image:
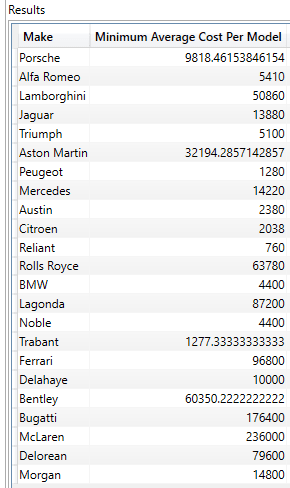
In this DAX snippet, the inner GROUPBY() finds the average cost for each model per make, and then the outer GROUPBY() returns the maximum model cost per make. Although this approach is generally slower than using SUMMARIZE() or SUMMARIZECOLUMNS() there are challenges – such as this one – that are not possible using other functions.
The main thing to note here is that GROUPBY uses CURRENTGROUP() to provide the row context for the iteration over the virtual table created by the custom grouping. Be warned, however, that GROUPBY() can be slow when applied to large datasets.
Conclusion
As you have learned, there is a small suite of DAX table functions that you can use to return data to paginated reports from a Power BI dataset. A good understanding of the available functions and how they can be used, individually or together, will help you deliver the output you wish to display in your paginated reports. The next article will cover several more DAX table functions.