
This article takes a conceptual approach to explaining core source control concepts, using diagrams and anecdotes as necessary to describe how all the pieces fit together.
- Why source control – the basic purpose of source control and the benefits it offers, including:
- maintaining an “audit trail” of what changed, who made the change, and when.
- allowing team collaboration during development projects.
- Basic source control components and concepts, including:
- the repository, which stores the files and maintains their histories.
- the working folder, which provides an isolated environment (sandbox) for creating, editing, and deleting files without affecting those in the repository.
- workflow concepts, such as versioning, branching and merging files.
Why Source Control?
A source control solution provides users with the tools they need to manage, share, and preserve their electronic files. It does so in a manner that helps minimize the potential for conflicting changes and data loss, in other words one user inadvertently overwriting another user’s changes when multiple users work on the same files. If one user changes the name of a column while another one updates its data type, the source control system will alert us to the conflict and allow the team to decide the correct outcome, via a merge operation.
Critically, a source control solution maintains a version history of the changes made to every file, over time, and provides a means for users to explore those changes and compare different file versions. This is why we often refer to a source control system as a version control system, or VCS for short.
These days, few software developers would consider building an application without the benefits that a VCS offers, but its adoption for databases has been slower. This is mainly because of the nature of a database, which must preserve its “state” (i.e. business data) between database versions. It means that having, in source control, the files that define the schema objects and other code is not the whole story. When upgrading a “live” database to a newer version, as it exists in the VCS, we can’t just tear down objects that store data and re-create them each time.
Nevertheless, despite this added complication, there is no reason why we should exclude databases from our source control practices. In fact, a VCS can be one of a database developer’s most valuable tools and the foundation stone for an effective and comprehensive change management strategy.
At its heart, the purpose of a VCS is to maintain a change history of our files. As soon as we enter a new file into source control, the system assigns it a version. Each time we commit a change to that file, the version increments, and we have access to the current version and all previous versions of the file. This versioning mechanism serves two core purposes:
- Change auditing
- Compare versions, find out exactly what changed between one version and another.
- Find out who made the change and when; for example, find out when someone introduced a bug, and fix it quickly.
- Team collaboration
- Inspect the source control repository to find out what other team members have recently changed.
- Share recent changes.
- Coordinate work to minimize the potential for conflicting changes being made to the same file.
- Resolve such conflicts when they occur (a process called merging).
By maintaining every version of a file, we can access the file as it existed at any revision in the repository, or we can roll back to a previous version. Source control systems also allow us to copy a particular file version (or set of files) and use and amend them for a different purpose, without affecting the original files. This is referred to as creating a branch, or fork.
I hope this gives you a sense of the benefits a source control system offers. We’ll look at more as we progress. The following sections paint a broad picture of the source control components and workflow that enable this functionality. We review the most important concepts in terms of the content creation, the storage, and the tracking strategies they enable, but we won’t go into too much detail.
The Source Control Repository
At the heart of a VCS is the repository, which stores and manages the files, and preserves file change histories.
Centralized source control systems support a single, central repository that sits on a server, and all approved users access it over a network. In distributed source control systems, each user has a private, local repository, as well as (optionally) a “master” repository, accessed by all users. We assume a centralized model for the conceptual examples in this article.
Regardless of the model used, when we add files to the repository, those files become part of a system that tracks who has worked on the file, what changes they made, and any other metadata necessary to identify and manage the file.
Repository storage mechanisms
The exact storage mechanism varies by source control system. Some products store both the repository’s content and its metadata in a database; some store all content and metadata in files (with the metadata often stored in hidden files); other products take a hybrid approach and store the metadata in a database, and the content within files.
The repository organizes files and the metadata associated with each file, in a way that mirrors the operating system’s folder hierarchies. In essence, the structure of files and folders in a source control system is the same as in a typical file management system such as Windows Explorer or Mac OS Finder. In fact, some source control systems leverage the local file management system in order to present the data in the repository. Figure 1 shows the server repository structure for a BookstoreProject repository, with the Databases folder expanded to reveal a Bookstore database. Don’t worry about the details of this structure yet, as we’ll get to them later.
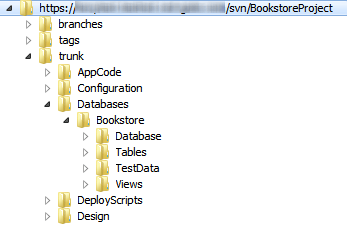
Figure 1: Typical hierarchical folder structure in the repository.
What sets a source control repository apart from other file storage systems is its ability to maintain file histories. Everything we save to a repository is there forever, at least in theory. From the point that we first add files to the repository, the system maintains every version of every file, recording every change to those files, as well as to the folders that form the repository structure.
Source control of non-text files
Ideally, a VCS manages and tracks the changes made by all contributors to every type of file in the system, whether that file is a Word document, Excel spreadsheet, C# source code, or database script file. In reality, however, traditional source control solutions usually track changes only on text files, such as those used in application and database development, and tend to treat binary files, such as Word or Photoshop files, as second-class citizens. Even so, most solutions maintain the integrity of all files and help manage processes such as access control and file backup.
The Working Folder
Most users care less about how their source control system stores the file content and metadata, and more about being able to access and work on those files. Each repository includes a mechanism for maintaining the integrity of the files within their assigned folder structure and for making those files accessible to authorized users.
However, to be able to edit those files, each user needs a “private workspace,” a place on his or her local system, separate from the repository, to add, modify, or delete files, without affecting the integrity of the files preserved in the repository.
Most VCSs implement this private workspace through the working folder. The working folder is simply a folder, and set of subfolders, on the client computer’s file system, registered to the source control repository and structured identically to the folders in the repository. Figure 2 shows the working folder structure for a user of the BookstoreProject repository. This user has copied the entire repository to a working folder called BookstoreProject.
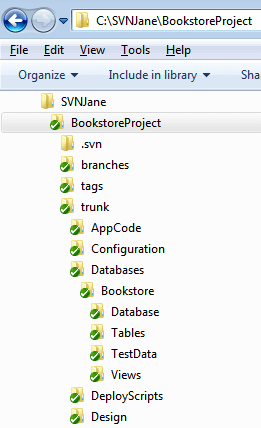
Figure 2: Typical working folder structure.
Each user stores in their working folder copies of some or all of the files in the repository, along with the metadata necessary for the files to participate in the source control system. As noted above, that metadata is often stored in hidden files.
We can update our working folder with the latest version of the files stored in the repository, as illustrated in Figure 3.
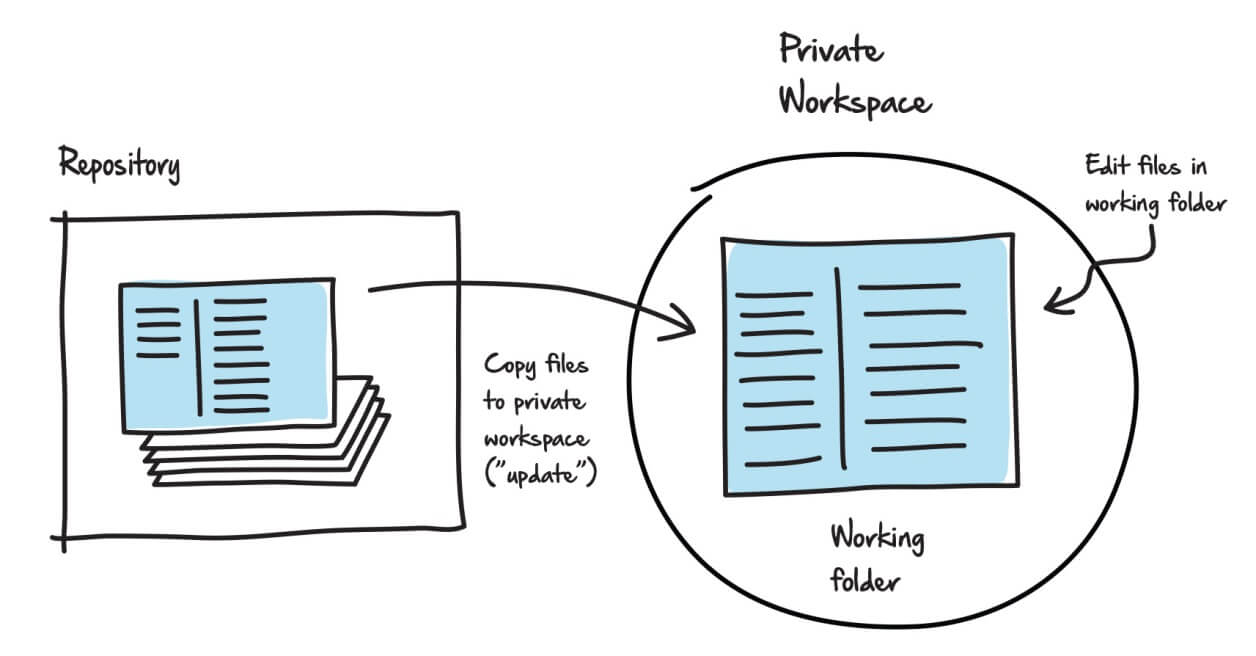
Figure 3: Copying files from the repository to the working folder.
We can edit the files in the working folder as necessary and then, eventually, commit the edited versions back to the repository. This process of “synchronizing” the working folder with the repository, i.e. updating the local working folder with any changes in the repository and committing any local changes to the repository, works differently from product to product and depends on whether the repository is centralized or distributed.
Regardless of repository type or product, the source control system always keeps the files in the repository separate from changes made to files in the working folder, until the user chooses to commit those changes to the repository.
Versioning and Collaborative Editing
The exact architecture and mechanisms that underpin versioning and collaborative editing vary by VCS, but the basic principles are constant. A user can obtain a local “working copy” of any file in the repository, make additions and amendments to that file, and then commit those changes back to the main repository. At that point, other users can request from the repository the amended version of the file or any of the previous versions. The VCS maintains a full change history for each file, so we can work out exactly what changed from one version to another.
In this section we’ll discuss, at a high level, how the repository maintains these file versions, as users make progressive changes to those files. Notionally, this versioning process is easy in a single-user system. A user updates his or her working folder with the latest versions of a set of files, and then edits those files as appropriate in a suitable client, such as Notepad for a plain text file, Visual Studio for an application file, or SQL Server Management Studio for a database file. The user then commits the changes to the repository, creating new versions of the files.
However, another key function of source control is to enable a group of people to work collaboratively on the set of files that comprise a development project. In other words, the VCS must allow multiple users to modify a file concurrently, while minimizing the potential for conflicts and data loss. Let’s see how source control systems allow for and manage these concurrent changes.
How versioning works
Let’s assume we’ve created a project directory in source control for an Animal-Vegetable-Mineral (AVM) application and that we’ve established a working folder for this project.
Figure 4 depicts the progressive changes to the application over three revisions. Notice that the repository preserves all the changes to the files, with each version assigned a revision number. Note that Figure 4 is not in any way a depiction of how a VCS maintains different file versions internally. It is merely to help visualize the process of how it can allow us to access different file versions, and provide a history of changes to our files over time.
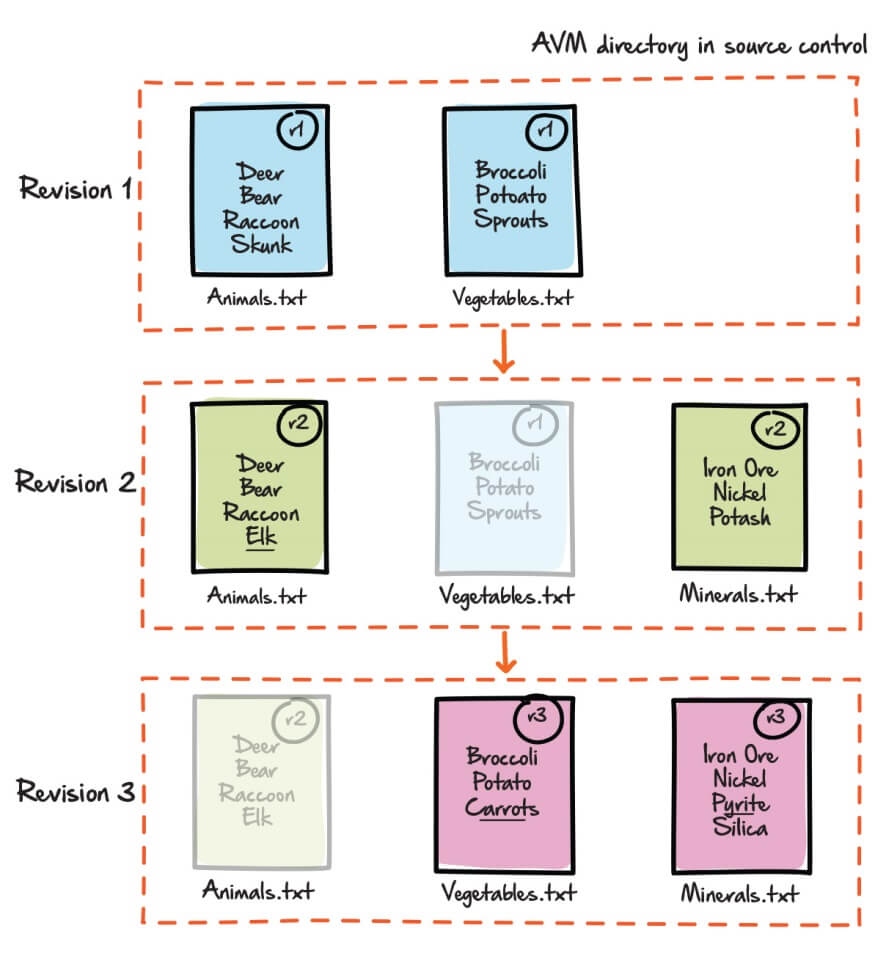
Figure 4: Working with files from the AVM project in source control.
In Revision 1, we committed to the repository (from our working folder) two new files, Animals.txt and Vegetables.txt. Revision 1 represents the first and latest file versions in the AVM repository.
We edited Animals.txt to replace skunk with elk, and created a third file called Minerals.txt, and committed the changes to the repository. Collectively, these changes form Revision 2. Vegetables.txt remains unchanged from Revision 1.
Next, we edited Vegetables.txt, changing sprouts to carrots, and edited Minerals.txt, changing potash to pyrite and adding silica. These changes form Revision 3, with Animals.txt unaltered from Revision 2.
Mostly, users are interested in working with the latest folder and file versions in the repository, but we can also request to see the repository as it existed at any earlier revision, with each file exactly as it existed at that point in time. For example, if we were to pull Revision 2, we would get the Revision 2 copies of the Animals.txt and Minerals.txt files, as well as the Revision 1 version of the Vegetables.txt file. In this way, we can build and deploy a specific “version” of the application or database.
Conceptual versus actual source control implementation
In this article, the descriptions of the versioning process are conceptual in nature. An actual source control implementation will vary according to product. It might not store this many different file versions, or it might build a given version by storing a record of the differences (the delta) between a current version and the previous version.
Since developers usually want to ensure they are working with all the most recent versions of their project files, they update their working folders regularly to get the latest versions. When they view their working folders, they are viewing the latest version of the repository and all its folders and files, at the point in time they did their last update.
However, we can also request to view the revision history for the repository (for example, by accessing the repository’s log). Exactly what we see when viewing the revision history depends on the VCS, but it’s likely to include information such as the revision number, the action, who made the changes, and when, and the author’s comment, i.e. a description of the change. Figure 5 shows what the log might look like for the AVM project folder, after the sequence of changes (and assuming two users, Fred and Barb).
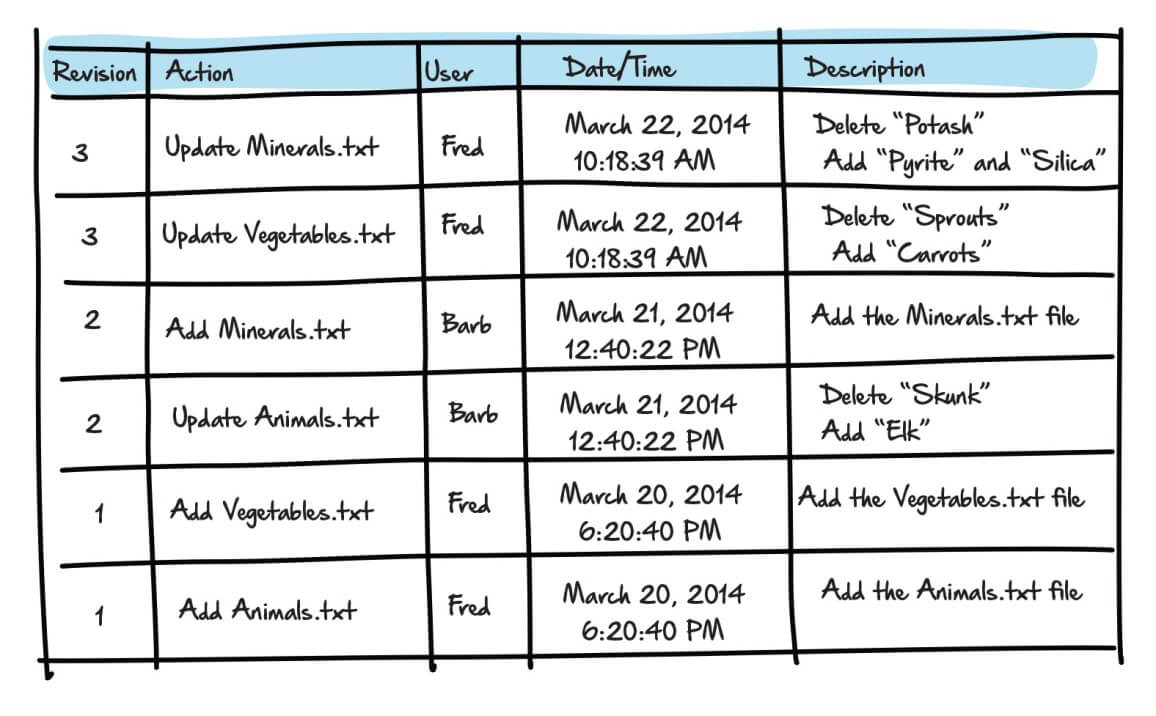
Figure 5: Storing files in the repository of a source control system.
A VCS, as noted earlier, often stores the differences between each file version, rather than the full file for every version. We refer to each set of differences as the delta. If we request to view a file as it existed at a particular revision, the VCS might, for example, retrieve the last stored complete file and then apply the deltas in the correct order going forward.
Likewise, a VCS will usually provide an easy visual way for users to see a list of what changed between any two revisions in the repository. We call this performing a diff, short for “difference between revisions”.
Collaborative editing
Any source control solution must provide the structure necessary to permit collaboration on different file versions in the repository, while preserving every version of each file.
The potential difficulty arises when more than one user works on the same version of a file at the same time. Let’s say both Fred and Barb have in their respective working folders Revision 2 of our AVM app. Fred edits Vegetables.txt, changing sprouts to carrots and commits the change. At roughly the same time, Barb edits the same file, changing sprouts to peas, and commits the change. What should be the result in the source control repository? If the “last commit wins,” we’d simply lose Fred’s changes from the current version of the file.
Older source control systems (often referred to as “first generation”) get around such difficulties by imposing an isolated editing (or locking) model, whereby only one user at a time can work on a particular version of a file.
Most modern source control systems enable a group of users to work collaboratively on the same version of a file. Referred to as a concurrent editing model, this process allows them to reconcile, or merge, the changes made by more than one user to the same file and, in the process, resolve any conflicting changes.
Isolated editing
A traditional “first-generation” source control solution, such as Source Code Control System (SCCS), developed at Bell Labs in 1972, uses a central repository and a locking model that permits only one person at a time to work on a file.
To use a database metaphor, we can liken the isolated editing model to SQL Server’s pessimistic concurrency model. It assumes, pessimistically, that a conflict is likely if multiple users are “competing” to modify the same file, so it takes locks to prevent it happening.
A typical workflow in source control might look as follows:
- Fred performs a check-out of the latest version of the Animals.txt file, in this case, Revision 1.
- If the file does not exist in Fred’s working folder, the source control system will copy it over.
- The source control system “locks” the file in the repository. (The exact “locking” mechanism varies by system.)
- Fred edits the file in his editor of choice. He deletes skunk and adds elk.
- Fred saves the changes to his local working folder.
- Barb attempts to check out Animals.txt, but cannot because Fred has it locked. Although Fred saved his changes locally, he has yet to perform a check-in to the repository and so the file remains locked and no one else can check it out.
- However, Barb can download Animals.txt to her working folder as a read-only copy, so she can at least see the latest version as it exists in the repository.
Figure 6 provides a pictorial overview of this process, to this point.
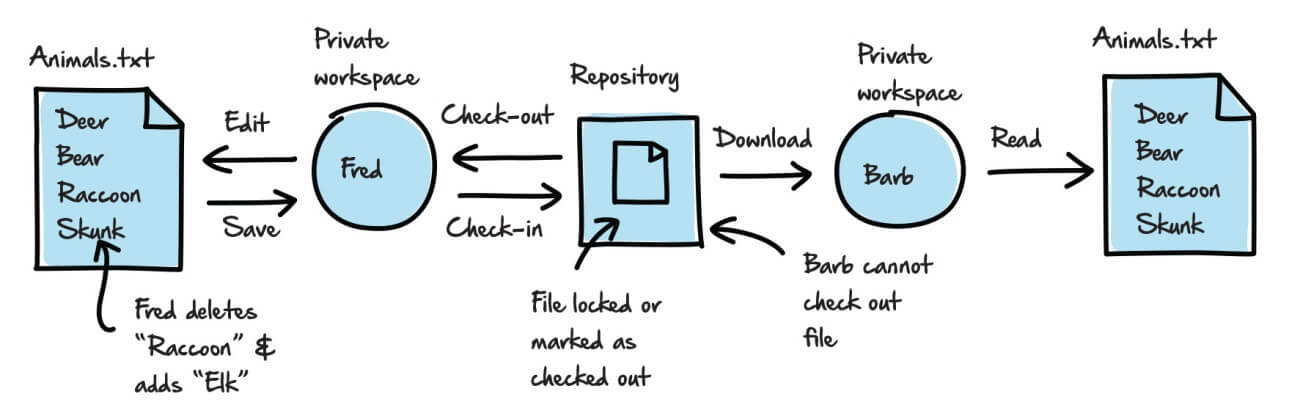
Figure 6: Allowing only one user at a time to modify a file.
From this point, the workflow might proceed as follows:
- Fred performs a check-in, which copies the updated file from his working folder into the repository.
- The repository stores Revision 2 of Animals.txt, while retaining Revision 1.
- The source control system releases any locks, so both versions of the file are available for checkout.
- Barb can now work freely on Animals.txt. She can:
- View Revision 2, with an elk instead of a raccoon, by re-syncing her working folder.
- Compare the two versions to determine what changed.
- Check out the file for editing. The source control system will automatically copy the latest version, Revision 2, to her working folder and lock the file in the repository.
Remember that source control terminology can vary a lot depending on the system. For example, some systems refer to the check-out operation as a “get,” and the check-in operation as an “add,” a “delta,” or a “commit.”
An important point in all this is that the repository only increments the revision number in response to the check-in operation. A user can check out a file, edit it and save it to his working folder but then decide to “revert” to the original version of the file. The source control system will release the file, and the revision number will remain unchanged. The user’s local changes are lost, unless he or she saved them elsewhere.
Concurrent editing
If working on the files in isolation is the safest route to controlling changes and avoiding conflicts, it’s also the slowest. For a more efficient workflow, modern source control systems allow for the possibility that two or more users will edit the same file at the same time. The notion of a check-out operation, with its attendant locking, disappears and instead each user performs an “update” to refresh his or her working folder with the most recent copies of the repository files. Users can then work on these files concurrently, then commit their changes to the repository.
If isolated editing is akin to SQL Server’s pessimistic concurrency model, then the concurrent editing model is more like SQL Server’s optimistic concurrency model. It hopes, optimistically, that no other user will “interfere” with a file on which another user is working, but it has to deal with the consequences if it happens.
Let’s see how this might alter our typical workflow. Our description of the various processes uses the most common terms associated with centralized version control systems, with the usual proviso that you will see differences even among centralized systems, and certainly for distributed systems where these processes work slightly differently.
- Fred performs an update to retrieve the latest files. In this case, he now has in his working folder Revision 2 of
Animals.txt. - Barb does likewise.
- Fred edits his working copy of the file by adding wolf.
- Barb edits her working copy of the file by adding fox.
- Fred saves the changed file to his working folder.
- Fred commits the changed file to the repository. The updated file becomes Revision 3 in the repository.
- Barb saves her edited copy to her working folder.
- Barb tries to commit to the repository, but the repository detects that the version of the file has changed since Barb’s last update. The commit fails.
- Barb performs an update, retrieving Revision 3 into her working folder, and must now “merge” the changes in her working copy of the file with those in the Revision 3 copy of the file. This merge process might be automated, manual, or a combination of both.
- Barb commits the merged file to the repository. The updated file is designated as Revision 4.
Figure 7 provides an overview of this process.
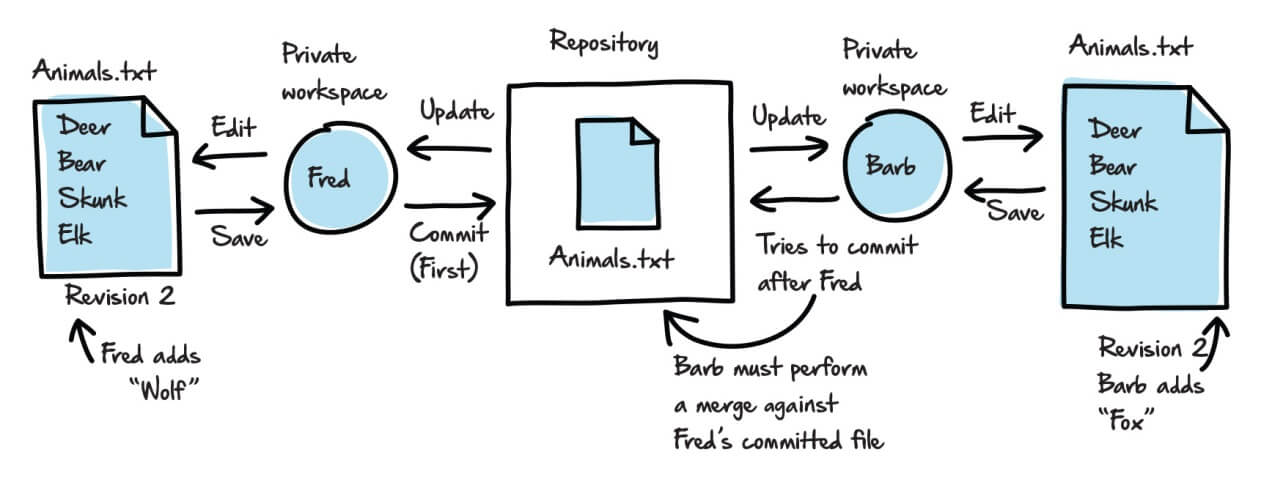
Figure 7: Concurrent editing of the Animals.txt file.
In this simple example, Fred and Barb each make changes that do not really conflict; the wolf and the fox can easily co-exist, at least within the confines of a text file. In such cases, the source control system will probably perform this sort of merge automatically, but in this case even merging the documents manually is a relatively painless process whereby Revision 4 simply contains both the users’ changes, as shown in Figure 8.
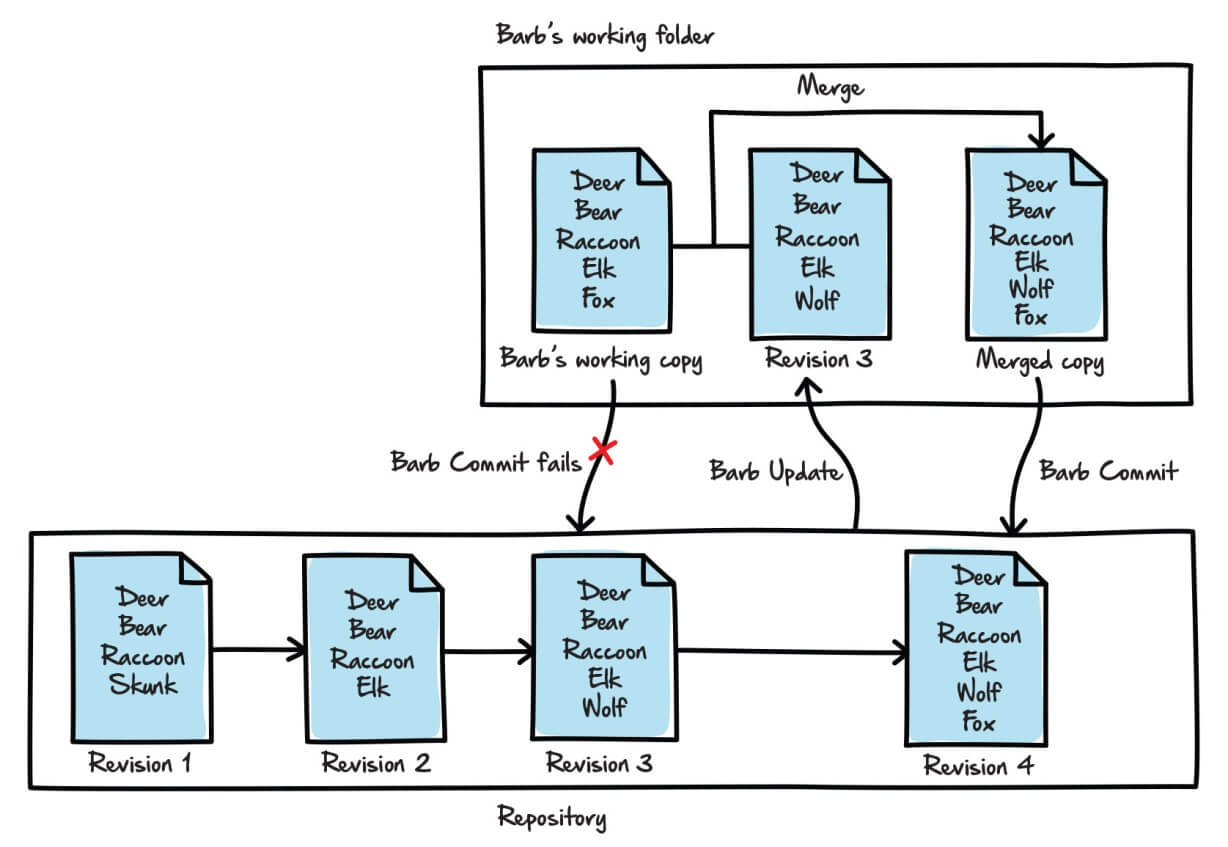
Figure 8: Merging two versions of a file to create a third version.
Again, this may not be exactly how a VCS implements a merge, but it gives a good idea of how it works conceptually. Some users don’t even consider this a merge operation, since it can occur automatically as part of the update operation. Some merges, however, are not quite so straightforward.
Dealing with conflicts during concurrent edits
A VCS can sometimes auto-merge changes made by different users to the same file. Sometimes, however, concurrent changes to the same version of a file will cause a real conflict, and to resolve it one of the users will need to perform a manual merge operation, within his or her working folder.
Let’s rewind to the stage of our Animals.txt example, where each user was working with Revision 2. Suppose that, in addition to adding wolf to his file, Fred changed bear to black bear, and committed the changes (creating Revision 3). At the same time, in addition to adding fox to her file, let’s assume Barb changed bear to brown bear. Now when Barb tries to commit her file, an actual conflict emerges, one that Barb must resolve, as shown in Figure 9.
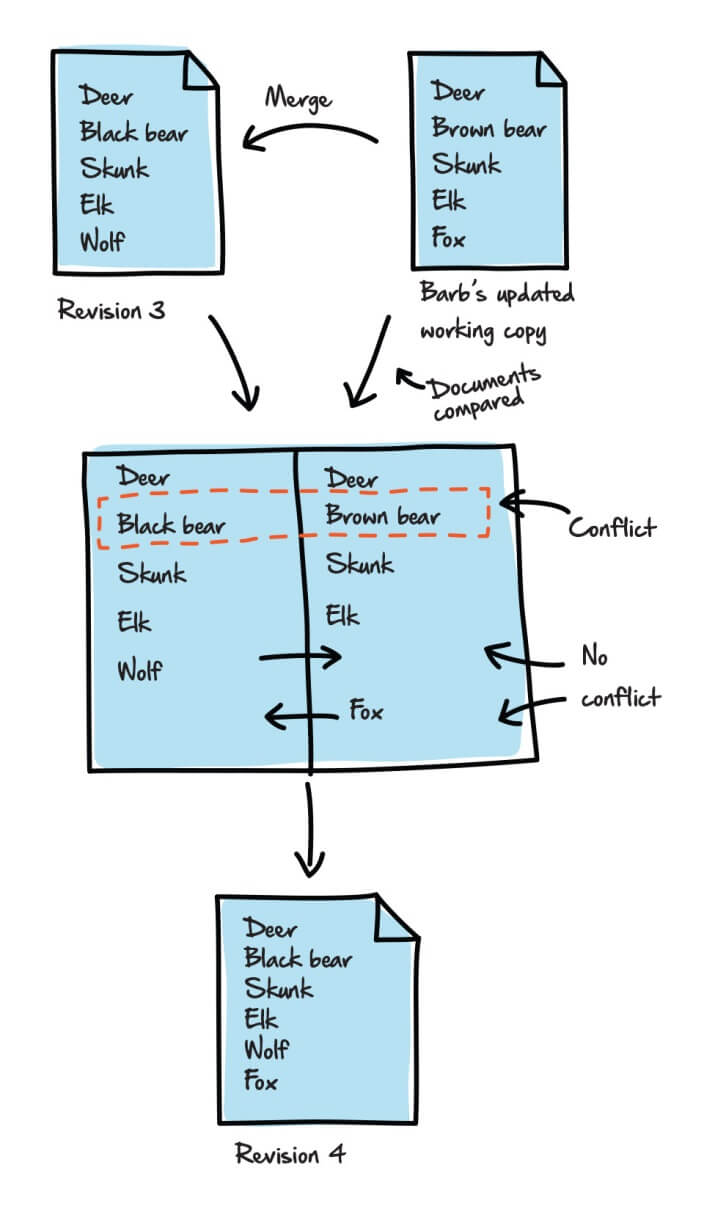
Figure 9: Addressing conflicts when trying to merge files.
The source control system can’t merge the two file versions until Barb resolves the conflict between black bear and brown bear (the additions of wolf and fox still cause no problem).
When conflicts of this nature arise, someone must examine the comparison and determine which version of bear should win out. In this case, Barb decides to go with black bear.
It’s worth considering the risk associated with this merge process. Barb’s commit fails, so she can’t save her changes to the repository until she can successfully perform a merge. If something goes wrong with the merge operation, she risks losing her changes entirely. This might be a minor problem for small textual changes like these, but a big problem if she’s trying to merge in substantial and complex changes to application logic. This is why the source control mantra is: commit small changes often.
Merging in distributed source control systems
In distributed source control systems, each user’s client hosts a local repository as well as a working folder. In the distributed model, Barb commits to her local repository, saving her changes, and then pushes the updated file to the central repository, which would fail because Fred got there first. We won’t go into detail on what comes next, but it means we’d see different file versions and version numbers in the central repository from what we saw in our “centralized” example. The main point at this stage is simply that merging is “safer” on distributed source control systems because users can always commit their local changes to their local repository.
Another wise practice is: update often. The earlier and more often we update our working folders and commit our changes, the better the processes work for everyone and the easier it is to merge files and resolve conflicts.
Branching
The way in which we organize files within a repository depends on the team’s preferences, the project, and on the source control system itself. One common approach is to organize files by project, with each set of project files, whether related to database development, application development or something else, stored within the main project folder.
We organize the project folder itself according to the standards set for the organization. In many cases, we will store the files related to the main development effort in a common root subfolder, often named trunk, but sometimes referred to by other names, such as master. We then create subfolders in the trunk folder as required; for example, as we saw earlier in Figure 1, a subfolder for database development and another for application development, and so on.
However, relying exclusively on the trunk folder assumes that everyone on the team is working simultaneously on the project files associated with the main development effort. In reality, it is common that certain team members will wish to “spin off” from the main effort to work on separate, but related projects, often referred to as branches. For this reason, you’ll find that the main project folder will also contain a branches folder (or a folder with a comparable name), in addition to trunk.
Let’s assume that we’ve created a project folder in our repository for our AVM project, added the trunk and branches folders, and built our data-driven application. At this point, all our files are stored in the trunk folder.
At Revision 100, the team releases the latest version of the application to customers as v1.0. They’re now ready to begin developing v2.0. At the same time, customers are submitting feedback and bug reports for v1.0. This is a classic example in software development of where it will be useful to create a branch (of course, various other branching strategies are used too). We create a branch at a particular revision in the repository. When we do this, the repository creates a new path location, identified by whatever we call the branch.
In this case, we’ll create a branch at Revision 100 and call it 1.0_bug fixes. From the user’s perspective, this process creates a separate 1.0_bug fixes subfolder in the branches folder, at Revision 101, and populates it with project files that point back to the Revision 100 files in the trunk folder. Developers can work on the branch files as they would in the trunk, but their efforts remain independent of the trunk development efforts, while preserving the fact that each set of files shares the same roots.
Tags and build numbers
Closely related to the concept of a branch is a tag. In fact, a tag is virtually identical to a branch in that it is a named location for a set of files in the repository, created at a particular revision. We can think of creating a tag as a way to name a set or subset of files associated with a particular revision. The big difference is that we don’t ever modify tags. They represent a stable release of a product, with the tag usually representing some meaningful build number. In our example, we might create a tag at Revision 100, called “v1.0.”
While part of the team works on the 1.0 bug fixes in the branch, the rest of the team continues the 2.0 development in the trunk. Those assigned to the bug fixes can work with the trunk folders and files as they would in the trunk. They can edit the files in their working folders and commit changes to the repository, which will maintain revision histories for the life of each branch file, starting from the point of branch creation.
For example, let’s say Barb creates a branch of the AVM project, containing all the project files, called 1.0_bug fixes, in preparation for the first maintenance release (v1.1). This means that the branch folder is at Revision 101, and contains, among other files, the latest revision (let’s say Revision 100) of Animals.txt, as it existed in the trunk at the time she created the branch. Meanwhile, Fred is working in the trunk in preparation for the release of v2.0.
Fred updates his working folder with the latest file versions in the trunk. He retrieves Revision 100 of the Animals.txt file, adds chipmunk and walrus and deletes fox. He saves the file and commits his changes to the repository. This creates Revision 102 in the repository.
Barb updates her working folder with the latest file versions in the branch. She retrieves the latest version of the Animals.txt file in the branch, which is still Revision 100; Fred’s commit has no effect on the file versions in the branch. Barb changes black bear to bear and commits the change, creating Revision 103 in the repository, as shown in Figure 10.
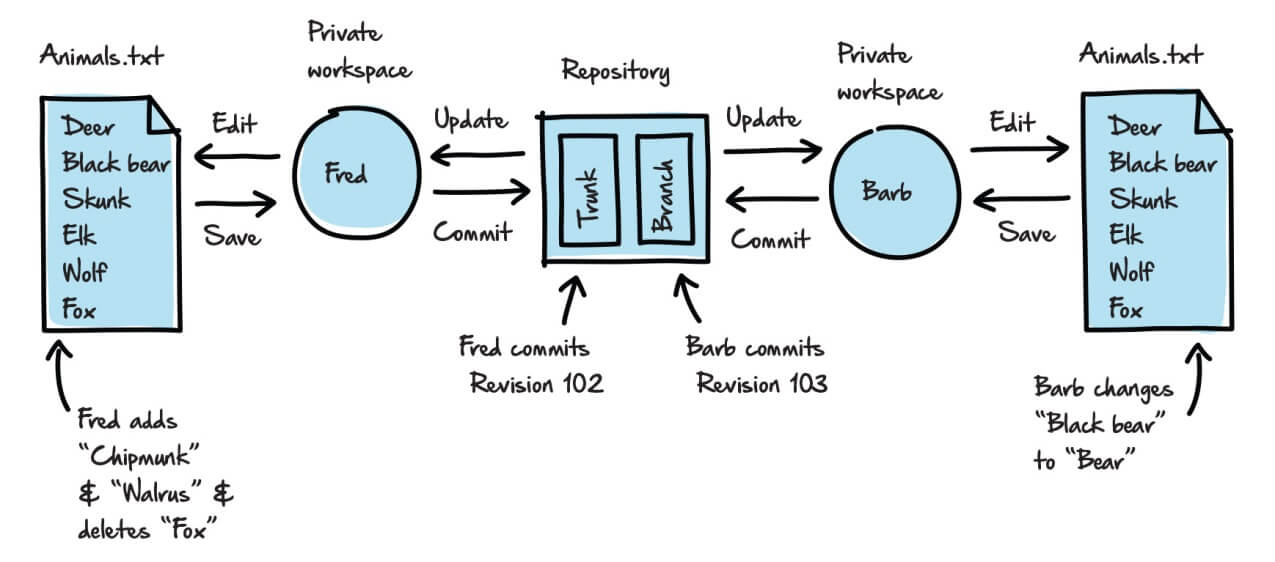
Figure 10: Creating a branch for the Animals.txt file.
As you can see, at this point, we have two simultaneous but separate development efforts. Of course, at some point the team may want to merge changes made in the 1.0_bug fixes branch back into the trunk so the next full product release can benefit from the maintenance fixes.
Merging
Previously, we discussed the need to perform a merge operation to resolve conflicting changes to the same version of a file in the repository. Similarly, when we create a branch, we’ll at some point want to merge the changes made to the branch into the trunk. Conversely, we will also need to merge changes from the trunk into a branch. For example, this might be necessary so that a long-running “feature branch” can catch up with the changes in the trunk. As you can imagine, a merge in either direction could be a complex process, especially if conflicts arise across many project files.
The type of comparison made when merging between branches is similar to merging files during normal concurrent editing. In fact, within a particular source control system, the two processes might seem nearly identical. Conceptually, however, they are somewhat different in intent. When merging during concurrent editing of the same file, we’re trying to resolve all conflicts to produce a copy of the file that represents a single source of truth. When merging a branch to the trunk, or vice versa, we’re retaining two sources of the truth and we’re interested only in incorporating the changes from one into the other.
For example, suppose Barb wishes to merge into the trunk the changes she made in the branch. Barb’s latest commit to the repository was Revision 103 (+bear, −black bear), affecting the Animals.txt file in the branch. Meanwhile, Fred’s latest commit to the repository was Revision 102 (+chipmunk, +walrus, −fox), affecting the Animals.txt file in trunk. The resulting merge operation will produce a new version of the Animals.txt file in the trunk (Revision 104), while the branch version will remain untouched at Revision 103.
Let’s consider each of these changes in turn, in the context of the merge operation.
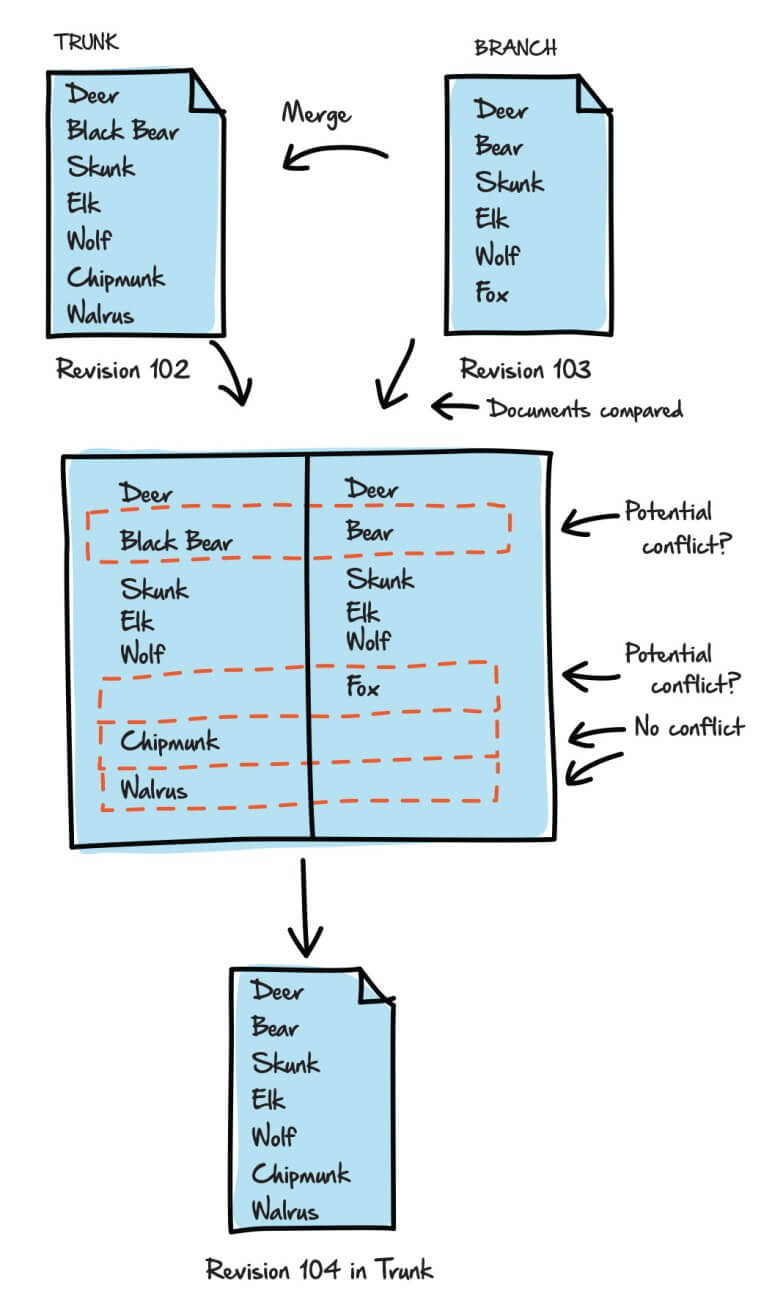
Figure 11: Resolving conflicts in the Animals.txt file.
Fred’s additions of chipmunk and walrus present no problem because they affect only the file slated for v2.0 (the trunk) and have nothing to do with v1.1 (the branch). In other words, Revision 104 will still contain the chipmunk and walrus entries.
The next potential conflict is with the fox listing. Fred removed fox from the file in trunk, but Barb did not remove it from the version in her branch. You might think that in merging from branch to trunk, we’d add fox back in to the trunk version. However, in effect, this would simply overwrite Fred’s change and any effective source control solution will recognize the potential for this sort of problem and avoid it. It may help to think of the merge in terms of the branch change set, in this case all the changes in the current branch revision compared to the revision on creating the branch. Barb wishes to apply this change set (−black bear, +bear) to the trunk file. This means, in SVN at least, that it will retain all other entries as they currently exist in trunk, and so fox will still not exist in the merged version in the trunk. Another VCS might mark this as a possible conflict, and the fact that the branch version assumes that the fox entry exists, but it doesn’t exist in the trunk, is a potential problem.. Ideally, before performing the merge, Barb would have updated her working copy of trunk and merged from trunk to branch, or at least inspected the differences and raised any possible issues with the team before performing her merge in the opposite direction.
Merging works differently in different source control systems
The methods used to perform the branch comparisons and merges vary from product to product, as does the amount of manual input involved to ensure that the merge does not do more damage than good. Each product is different and each configuration within a product can vary.
Finally, we have the potential conflict between bear and black bear. Just because Barb changed it in the trunk does not automatically mean it should be changed in the new release. Even so, SVN does not treat this as a conflict, though another VCS might. Only if Fred had also changed the black bear listing would SVN treat it as a conflict. The result is that the merged file in the trunk will contain the entry bear. Again, the onus is on Barb to ensure that this change to the maintenance release will cause no problems when applied to v2.0.
Branching usually comes off without a hitch; we point to the files and folders in the trunk that we want to branch and within seconds, off we go, with a new branch. Merging is the tricky part. The risks and overhead associated with merging can sometimes keep organizations from taking advantage of these capabilities. They might branch, but they don’t merge, often resulting in duplicated development efforts and manual copy-and-paste operations.
On top of this, it’s arguable that some source control systems are better at merging than others. Git, for example, was designed to merge, whereas SVN has a reputation for inflicting its fair share of agony on those trying to merge files.
Ultimately, though, the ability to branch and merge is crucial to any organization that needs to expedite their projects and work on those projects in parallel. The mantra is to merge early and often. If you do so, then it’s not usually too painful.
Summary
We’ve discussed many of the primary benefits of a source control system, and taken an initial, largely conceptual, look at the components (repository and working folder) and processes (branching and merging) of such a system, which help us realize these benefits.
Application developers have been reaping these benefits for many years, but database developers are only just starting to catch up. It’s true that database development is different from application development and often database developers have to remind the rest of the development team of those differences, but that does not mean they cannot benefit from a proven system to store and manage files, track changes, work with different versions, and maintain a historical record of the file’s evolution.


