
There’s a widespread misconception that SQL Server’s columnstore indexes are like an index on every column.
I debunk that myth in the first 30 minutes of my Fundamentals of Columnstore class, where I explain that a better way to think of them is that your table is broken up into groups of rows (1M rows or less per group), and in each group, there’s an index on every column.
So essentially, every column has a whole bunch of indexes on it.
But there’s no order whatsoever as to which rows end up in which index.
This isn’t a problem for relatively small tables, but as you get to billion-row data warehouse fact tables where columnstore should really shine, performance gradually degrades. In data warehouses, fact tables often have a commonly filtered column, like SaleDate. However, until SQL Server 2022, even if you wanted a small SaleDate range, your query would likely check hundreds or thousands of row groups, each of which had a huge range of data.
Here’s the problem before SQL Server 2022.
Take the Users table from the Stack Overflow database – it’s a bad candidate for clustered columnstore for reasons that we discuss in the class, but it’s the table most of y’all are familiar with, so we’ll start there. We’ll create a new table and put a clustered columnstore index on it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
DROP TABLE IF EXISTS [dbo].[Users_columnstore]; GO CREATE TABLE [dbo].[Users_columnstore]( [Id] [int] IDENTITY(1,1), [AboutMe] [nvarchar](4000) NULL, [Age] [int] NULL, [CreationDate] [datetime] NOT NULL, [DisplayName] [nvarchar](40) NOT NULL, [DownVotes] [int] NOT NULL, [EmailHash] [nvarchar](40) NULL, [LastAccessDate] [datetime] NOT NULL, [Location] [nvarchar](100) NULL, [Reputation] [int] NOT NULL, [UpVotes] [int] NOT NULL, [Views] [int] NOT NULL, [WebsiteUrl] [nvarchar](200) NULL, [AccountId] [int] NULL) GO CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.Users_Columnstore; GO SET IDENTITY_INSERT dbo.Users_columnstore ON; GO INSERT INTO dbo.Users_columnstore([Id], [AboutMe], [Age], [CreationDate], [DisplayName], [DownVotes], [EmailHash], [LastAccessDate], [Location], [Reputation], [UpVotes], [Views], [WebsiteUrl], [AccountId]) SELECT [Id], LEFT([AboutMe], 4000), [Age], [CreationDate], [DisplayName], [DownVotes], [EmailHash], [LastAccessDate], [Location], [Reputation], [UpVotes], [Views], [WebsiteUrl], [AccountId] FROM dbo.Users; GO SET IDENTITY_INSERT dbo.Users_columnstore OFF; GO |
After loading the data, visualize the columnstore contents with sp_BlitzIndex, and at first, it looks like the table is broken up into randomly sized rowgroups, sorted by their Id:

But that’s simply because our source, the Users table, happened to be sorted by Id. Over time, as you delete/update/insert rows in this table, you’re going to need to do index maintenance on it. (I know I talk a lot of smack about people who do too much index maintenance on rowstore tables, but columnstore tables are very different – they actually need maintenance for the reasons we discuss in the class.)
After a couple of rounds of index rebuilds, check the contents again:
|
1 2 3 |
ALTER TABLE dbo.Users_columnstore REBUILD; ALTER TABLE dbo.Users_columnstore REBUILD; sp_BlitzIndex @TableName = 'Users_columnstore'; |
And the rowgroups are literally sorted in random order:
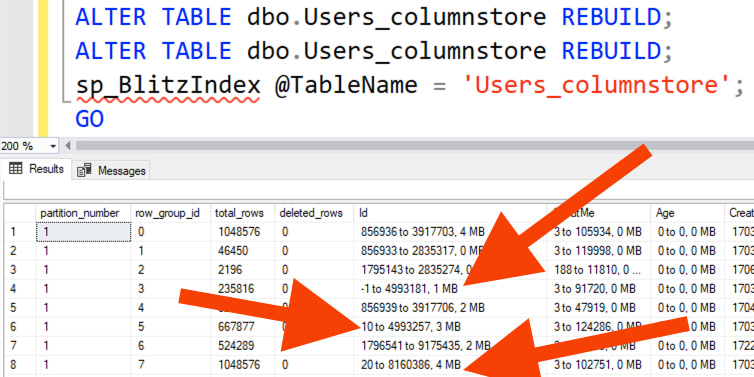
Meaning that if you want to find Id = 26837, you’re going to be checking multiple rowgroups – and more and more over time, as your data’s locations continue to randomize. This isn’t such a big problem for a tiny table like the 1GB Users table – but it’s a terrible problem for real-life sized tables, like the ones that really need columnstore.
You could work around this –
emphasis on work.
You could reload the entire table regularly. It sounds extreme, but if the table isn’t large, and your hardware is fast enough to make a copy of the table sorted in the order where you want rowgroup elimination, it works. Copy the data into a new structure with a clustered index on that column, then create a clustered columnstore index again. The data will be ordered by the rowstore clustered index columns.
That solution doesn’t scale well for the kinds of shops that really need columnstore, though, because we’re talking about blowing the table back up to its full uncompressed size, and then compressing it all back down again – and all of this is a logged operation.
A better option is to partition the data by your commonly filtered column. I like this solution a lot at the billion-row tier because it also enables much better index maintenance strategies. I frequently point out that daily rowstore index maintenance is usually a waste of resources, even suggesting to scale back to monthly, but with columnstore indexes, things get a lot more complicated depending on your workload. We talk about that in class, too.
In theory, I’m a fan of partitioned views, too – using a table per year or per quarter – and then unioning them together. I just haven’t seen that solution implemented in the last several years though. I’m sure it’s out there – I just haven’t seen it lately.
SQL Server 2022 fixes this
with ordered columnstore indexes.
Hey, go figure, indexes need to be put in order! Who knew? I mean, aside from all of us. Literally, every one of us. Here’s the syntax from Books Online:
|
1 2 3 |
CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.Users_columnstore ORDER (Id) WITH (DROP_EXISTING = ON); |
Rejoice! The data is now sorted by Id, so if you’re looking for a particular Id, SQL Server can narrow its search down to just one rowgroup:

Okay, I lied. It’s still not aligned. In fact, if anything, it’s even worse. You might argue that it’s because I didn’t specify a single-threaded index creation, but…those ranges overlap across lots of rowgroups, not just the 4 to represent the 4 cores in my VM.
When I try it again with MAXDOP 1:
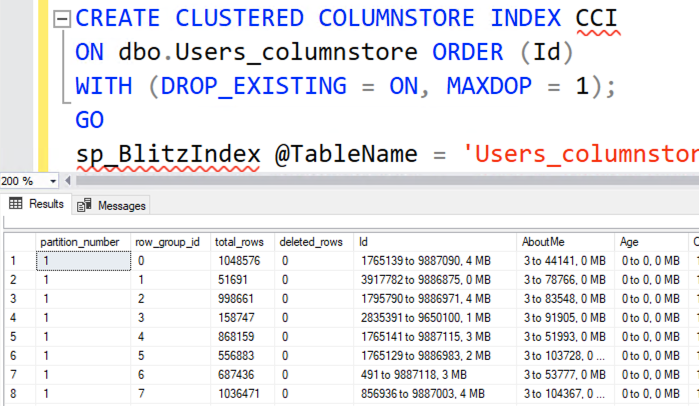
That doesn’t work either, and even if it did, MAXDOP 1 isn’t really doable in real-world table sizes – even the 1GB Users table took over a minute to do the above work.
In theory, when the feature finally works, it’d be useful if many of your reporting queries share a common filter – like in data warehouses, a SaleDate column. Again, definitely doesn’t make sense for the Users table – it’s not a good fit for columnstore at all – but it does fix the problem of the data being randomly ordered between rowgroups.
When examining your own data and reporting queries to figure out which column(s) to order by, check out the guidance for Synapse Analytics, which already has this feature. And I assume it actually works out there. Although you know what they say about assume…
Update 1, 2022-07-05: the command actually executes in CTP 2.0 when you use the right syntax, as pointed out by Adam Machanic in the comments.
Update 2, 2022-07-05: no, it doesn’t work.
Based on suggestions by Joe Obbish in the comments, I spent hours today trying repeated testing with columnstore indexes on tables up to 100GB on a VM with 30GB RAM. I even tried with MAXDOP 1, and still no dice – they’re not sorted:

Note the overlap in CreationDate ranges. I give up – until Microsoft has a demo showing this feature actually works, I’m going to hold off on further testing.
Update 3, 2022-07-11: it kinda works.
Ryan Stonecipher (Microsoft) reached out to me and we talked through it.
The data is kinda sorted, and they’re referring to it as a “soft sort.” The sort order is maintained in-memory as the index is being built, but if the sort runs out of memory, the currently sorted data is flushed to the next operator in the index build plan. Joe Obbish reverse engineered this in this well-written blog post.
The benefit of this design decision is that it avoids spilling to TempDB – that’s good.
The drawback is that the rowgroups aren’t perfectly sorted. There are going to be overlaps between rowgroups. The idea is just that there’s going to be way less overlaps than there would be with a completely unsorted set of rowgroups.
I’m totally fine with this. At the end of the day, it’s way better than the ALTER INDEX REBUILD behavior of columnstore, except for the fact that it’s offline only. The docs just need to better reflect that “order” is a best effort thing, not the kind of exact stuff that we usually expect from databases. I kinda jokingly think of it as a MongoDB simulator.

21 Comments. Leave new
Per the documentation it’s supposed to have an “ORDER” keyword for the column list. I’m not sure if that fixes your example? Also not clear to me why that’s not available for a nonclustered columnstore?
Oh boy – well, thanks for the correction there in that with the right syntax, it executes – but it doesn’t work. I’ve updated the blog post with screenshots showing what a hot mess it is.
Also disappointed this doesn’t apply to nonclustered columnstore and judging from the existing documentation, it looks like there’s no plan for it.
Hi Brent,
I haven’t personally tested this feature, but the following quote from the linked documentation may explain what you’re seeing with the overlapping segments: “If all data can be sorted in memory at once, then segment overlapping can be avoided. Due to large tables in data warehouses, this scenario doesn’t happen often.”
It’s hard not to roll my eyes at the last sentence but perhaps others are more forgiving than I am.
Hmm I would love to know the criteria for “can be sorted in memory at once” – like, will it use up to the default query memory limit? 25% of memory? Or all of the memory, ejecting everything else from the data cache to do it? Or some other limit?
Hoo boy – doesn’t happen often, here we go.
I tried it with the Votes table – 150M rows, 5GB uncompressed, 1.3GB columnstore – on a VM with 30GB RAM, 25GB max. Not large enough – same problem.
Now testing it with the Posts table (40M rows, 80GB uncompressed, only using the left 1000 characters of the Body column) but it’s taking forever (30 minutes and counting). (sigh)
That’s disappointing 🙁 For sure thank you for testing that though!
Bad news – it doesn’t work, even with the Posts table, even with MAXDOP 1. Updated the post to reflect it. Dang.
I wonder if this is affecting the test and it’s just not telling you it’s not using the MAXDOP = 1 option – from:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/performance-tuning-ordered-cci
“Currently, the MAXDOP option is only supported in creating an ordered CCI table using CREATE TABLE AS SELECT command. Creating an ordered CCI via CREATE INDEX or CREATE TABLE commands does not support the MAXDOP option. For example,
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);”
As in – it should throw an error or warning that it won’t use the MAXDOP option specified, but since it’s CTP it a bug that it’s not warning you
I was so excited when I started reading this post, but what a disappointment. Let’s hope by RTM it’s sorted
Pun intended???
I have some questions:
1. Is it already on AzureSQL? Or when it will be?
2. Brent, I have a feeling that you intentionally omitted the topic of partitioning columnstore index tables. Partitioning provides similar feature to dividing / sorting table into pieces.
3. I am wondering if REBUILD will be more resource consuming operation since it will require to sort all data across table/partition. What do you think about it?
1. No.
2. I have a feeling you didn’t read the post, or even bother to do a control-F for “partition”. And that’s where I stop reading your comment.
If this was the only feature (fixed of course and working as expected) added to SQL Server 2022 I bet lots of shops running Data Warehouses would upgrade only to improve querying and maintenance of big data!
By the way, Niko Neugebauer was giving it (ORDER) a try in Azure in 2019:
https://www.nikoport.com/2019/10/04/columnstore-indexes-part-128-ordering-columnstore-in-azure-sqldw/
tuning it with Extra Large Resource Role (xlargerc) achieving even 100% allignment.
Note: that URL doesn’t make browsers happy….not sure what’s going on there….it says its potential security risk…most curious
Niko has an SSL certificate configuration problem.
Niko sadly seems to have stopped working on his page 2 or 3 years ago. There is other stuff that no longer works and I tried once to contact him, but he didn’t reply. And there are no new / updated posts.
I’d assume that specifiying an explicit ORDER to a columnstore would decrease the compression ratio / increases the columnstore size.
As far I remember the common clustered columnstore tries to order the columns for best compression (= most repeats in (multiple) columns, so it may order a user table by country, first_name and city, because there may be MANY Bobs and Marys in New York / USA)
You’re on the right track, but not quite right. I explain how the internals ordering works in my Fundamentals of Columnstore class, but it’s beyond what I can do quickly in a comment here. Check it out!
This seems to be working in Azure SQL now when you rebuild the index with MAXDOP =1 . I’m seeing no overlap in MOST partitions – except for the last couple.