

Summary
A circular reference is a situation where you have two (or more) database projects in SSDT where each project references objects in the other project(s). For example, Project A looks up objects in Project B; Project B looks up objects in Project A. Why would you want to do this? If that is how your databases were designed, and you want to manage them in SSDT, then you don’t have much choice. Strictly, SSDT will not allow you to add a circular reference, but there are two general workarounds to setting up such projects in SSDT.
- Option 1 – Broken Projects with Direct References: break up your database projects into smaller projects so that any semblance of a circular reference is eliminated. You do this by moving objects with circular dependencies into a separate project.
- Option 2 – Complete Projects with Indirect References: use complete database projects while replacing some or all of your reference targets with equivalent (but not co-dependent) targets.
Both options have their advantages and disadvantages. Neither is universally right for all situations. Understand the differences before picking the model that works for your situation.
Introduction
Building and deploying one database without any references to other databases in SSDT is straightforward enough. It becomes slightly more complicated when you have databases that look up objects in other databases. This is because SSDT will want to resolve all your references and check their validity before it will let you successfully build and deploy the project1. You can turn these checks off in the settings, but that defeats the purpose of using SSDT projects and also turns off valid referential errors.
Consider this simple one-database example, with a table and a view that references the table:
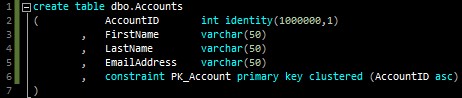
(PSA: please always name your constraints and keys)
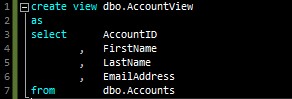
In this example, I can build the database project just fine. However, if I try to add a non-existent column to my view…
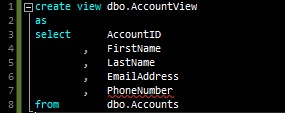
… not only do I get a squiggly error line in the text editor, I also get this error when I try to build the project:

I use this basic example to show the power of reference resolution in SSDT. Don’t think of it as an impediment; it is indeed an advantage as it helps you discover invalid references sooner rather than later in the development cycle, saving precious development and testing time and cost.
The Problem
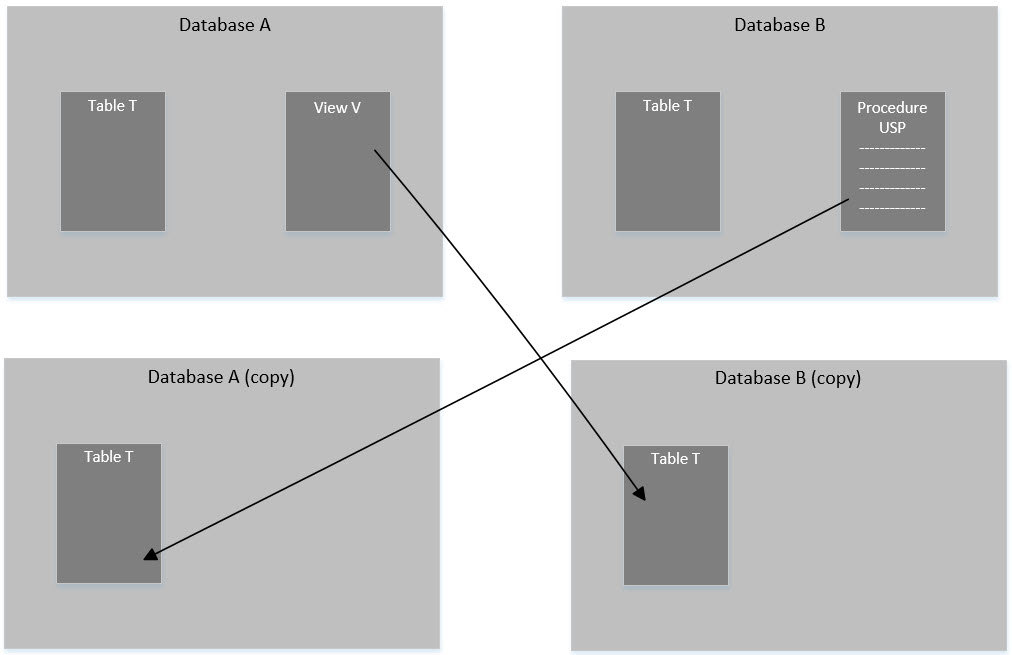
Having taken a quick look at simple references in SSDT, let’s see something more complicated: circular references. Say your SSDT solution has two databases, and both databases have references to each other. Database A has a view that looks up a table in Database B, and Database B has a stored procedure that interacts with a table in Database A, like this:
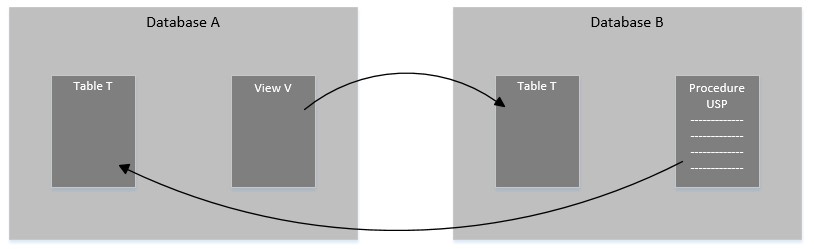
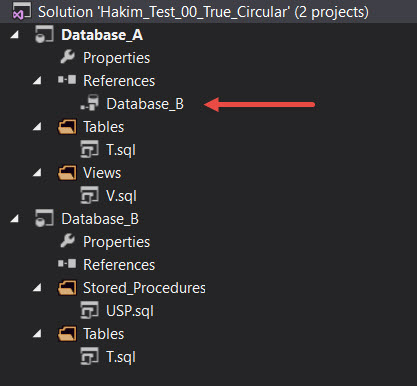
In Visual Studio, the project setup looks like this:
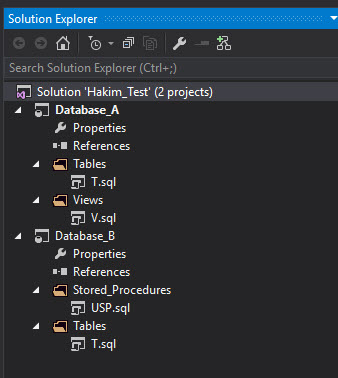
Note that Database_A and Database_B are independent projects at this point with no connections to each other. Their object definitions look like this:
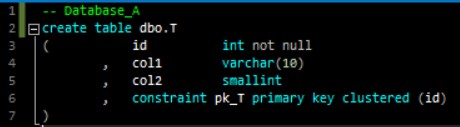
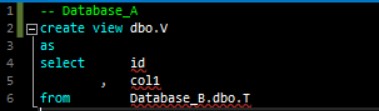
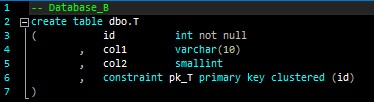
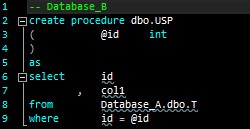
An external reference is an object not contained in the same database/project. As you can see, the objects that do not have any external references (the two tables) have no issues, but the objects with external references (the view and the stored procedure) have problems. Hovering on the squiggly lines reveals why Visual Studio has issues with those object definitions:
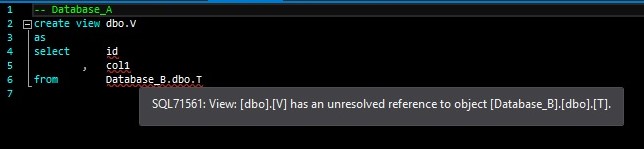
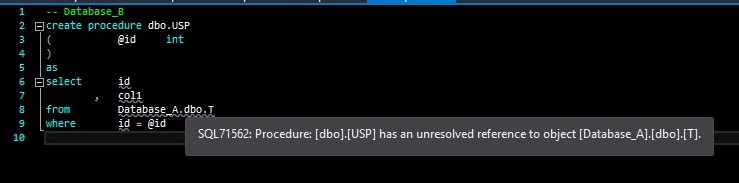
The project Database_A has no idea what Database_B is and thus no way to look up and resolve any objects within Database_B. The same issue exists within the project Database_B, which does not know what Database_A is. Recall from the single-database example above that these errors will prevent you from building and deploying your projects2. How do we resolve this?
We resolve this by adding references. We can add a reference from the project Database_A to the project Database_B. Right-click the References object under Database_A and pick ‘Add Database Reference…’:
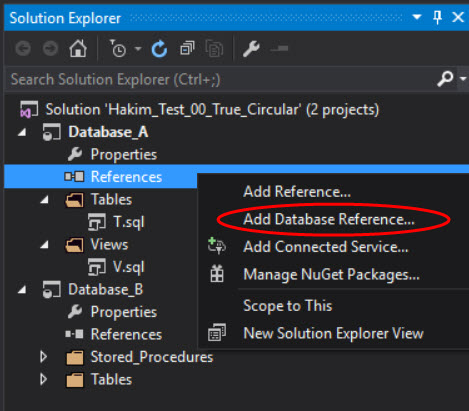
On the pop-up dialog, pick Database_B as the database reference to add. Be sure to clear out the text under ‘Database variable:’ so you can reference that database directly with its name:
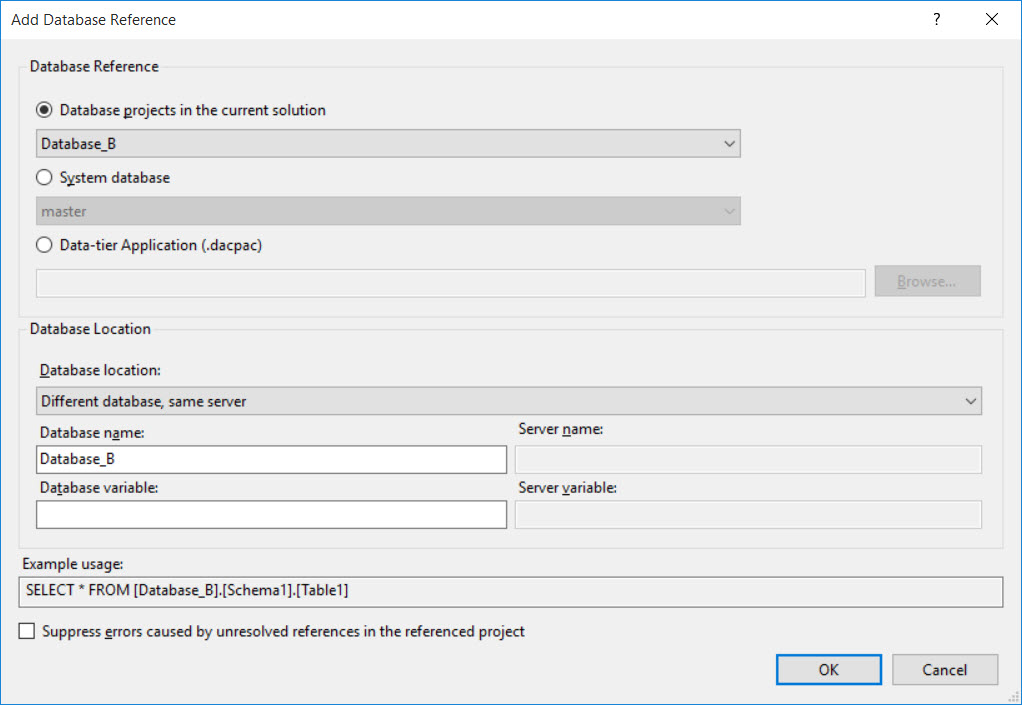
At this point our solution looks like this:
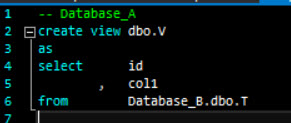
Look at the definition for view V in Database_A. The squiggly lines have gone away:
Now you can build and deploy the project for Database_A successfully3. We still have the unresolved reference to the table Database_A.dbo.T from the stored procedure Database_B.dbo.USP. Let’s try and resolve this by adding a reference to Database_A from Database_B:
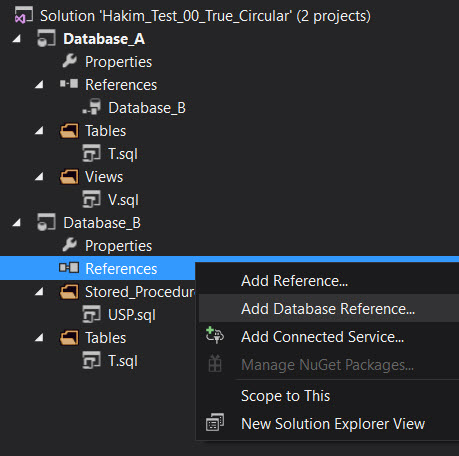
When I try to do this, I get this neat little error message:
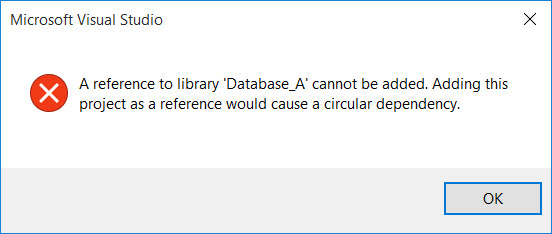
SSDT does not allow circular dependencies. Perhaps this is Microsoft’s way of saying you should avoid circular references while designing your databases. Regardless, sometimes you inherit such designs and sometimes there are good reasons for designing databases with circular references. If you want to maintain these databases in SSDT, you need to find a workaround to getting circular references into your project(s). The following sections show you two ways of implementing this workaround. These are not just two ways of doing the same thing, they are indeed two different philosophical approaches to setting up your projects in SSDT and affect how you will develop and deploy them.
Option 1: Broken Projects and with Direct References
This approach requires breaking up our database projects and moving the pieces that cause circular dependencies into separate projects. Looking at our dependency model from above:
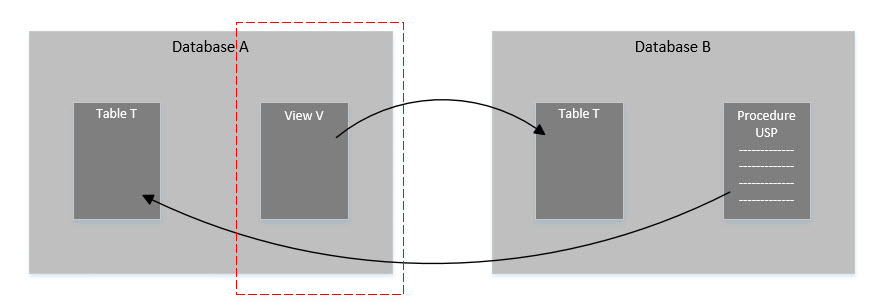
We can take out those parts of project Database_A that are dependent on Database_B (in this case the view V), and put them into a separate project. Now it looks like this:
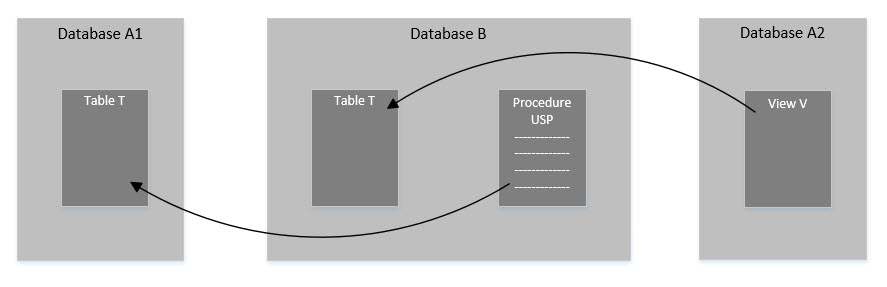
Now, we only have references going in one direction. We add a database reference from Database_A2 to Database_B, and from Database_B to Database_A1. In SSDT, it looks like this:
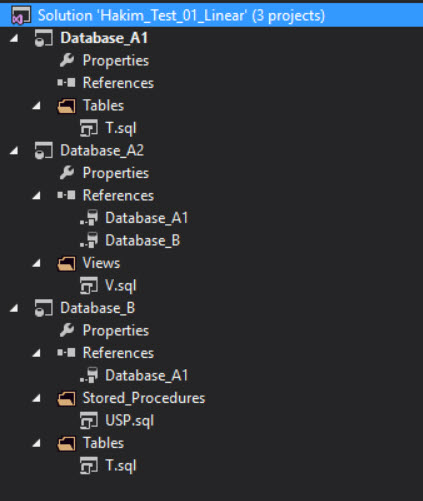
Note that the project Database_A1 has no references under it, because it does not need any. It only has one object, the table T, which does not depend on any other object. The project Database_B has one reference, to Database_A1, because the procedure USP depends on the table Database_A1.dbo.T. Finally, the project Database_A2 has two references. The reference to Database_B should be straightforward enough to grasp at this point.
However, why do we need the reference to Database_A1? This is because each database project within the solution needs to be fully resolvable / buildable / deployable (since projects are the ‘unit’ of building and deployment). So when you build the project for Database_A2, it will follow all reference paths and try to resolve them. It will follow the path from view V to Database_B, and then it will want to resolve the references within Database_B, which means it needs to know about the objects in Database_A1. Note that the choices in the ‘Add Database Reference’ dialog look like this:
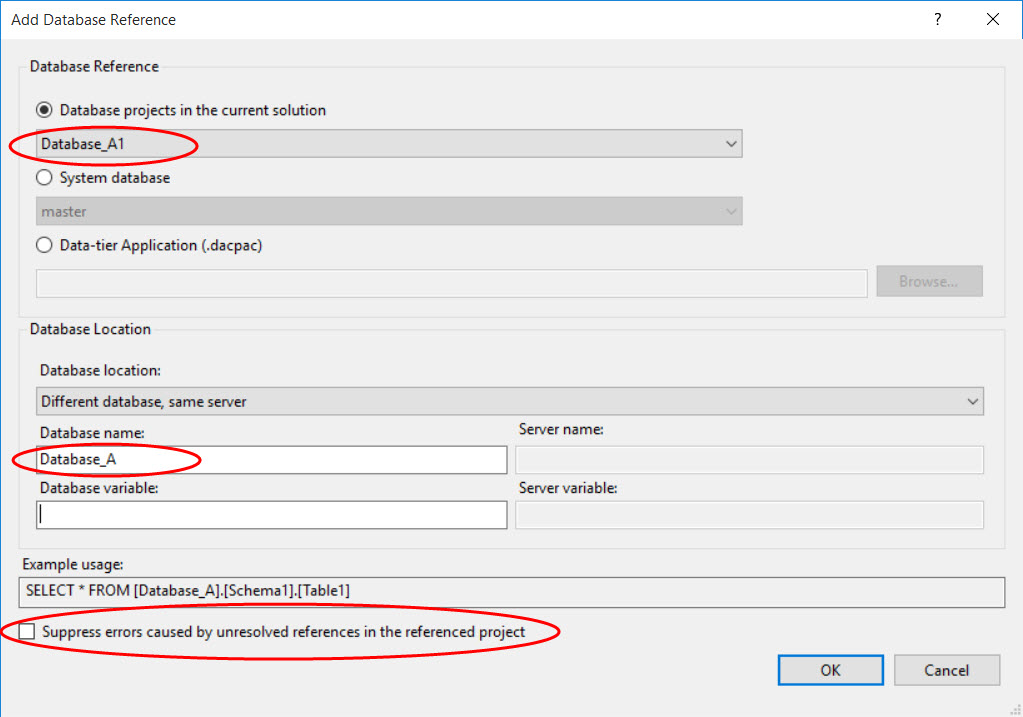
First, the project is called Database_A1 to differentiate it from project Database_A2 in our solution, but the ‘Database name’ value still needs to be Database_A, because that is what it is called in the code. See the ‘Example usage’.
Also, the check box for ‘Suppress errors caused by unresolved references in the referenced project’ is unchecked. This is the purist’s way of setting it up. In our situation, this is why we needed to add the reference from Database_A2 to Database_A1. As mentioned earlier, within project Database_A2, SSDT looks up the reference Database_B and then follows that down to the reference Database_A1. If I had checked this box, SSDT would not try and resolve Database_B’s referred objects within project Database_A2, and I could have gotten away with not adding the reference to Database_A1 from Database_A2. There are arguments for doing it both ways. I lean towards pragmatism and simplicity rather than purism, so I would go ahead and check the box and add one less reference.
Option 2: Complete Projects with Indirect References
In this approach, you keep the database projects intact, and remove the circular references by replacing one or more of them with linear references to equivalent targets. Again, looking at our original dependency model:
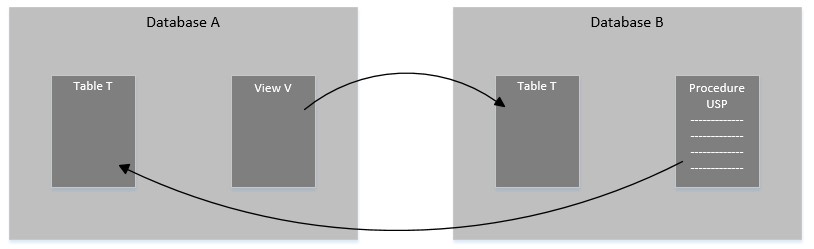
We could replace the dependency from Database_B to Database_A with something that looks like this:
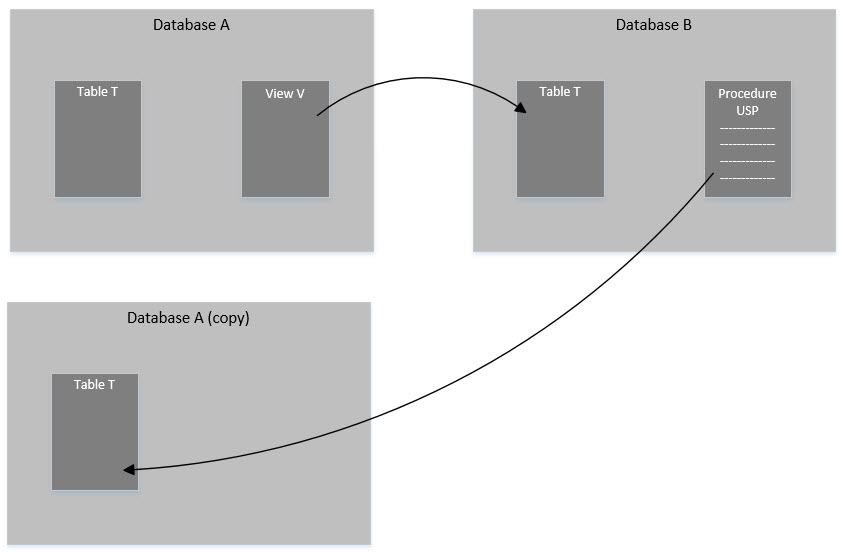
Instead of pointing to the original Database_A, Database_B now points to a copy of Database_A. This is different from the Option 1 scenario because you still use the original project Database_A for all development and deployment. The copy only exists to satisfy the dependency from the procedure Database_B.USP to the table Database_A.T. You wouldn’t necessarily even need to update the copy every time you updated the original Database_A or its schema. You would only update it when needed to satisfy any new objects that Database_B might want to reference.
This copy could be in one of several forms. It could be in the form of a separate database project in your solution where you only keep the minimally necessary objects to support the dependencies. In this case, this copy would only hold table T. You would especially be careful to avoid putting objects like view V here that would have further dependencies of their own.
Another form this copy could take, is the dacpac4 file. This can be created using a command line utility called SqlPackage.exe, or generated from SSDT. When you successfully build a project, SSDT creates a dacpac file for it. This is typically found in the \bin\Debug folder in your project folder. So instead of creating a separate project for Database_A, you would copy the dacpac file from a successful build of project Database_A, add it to a new folder in your project folder for Database_B, and add it as a reference. The options in the ‘Add Database Reference’ dialog box would look like this:
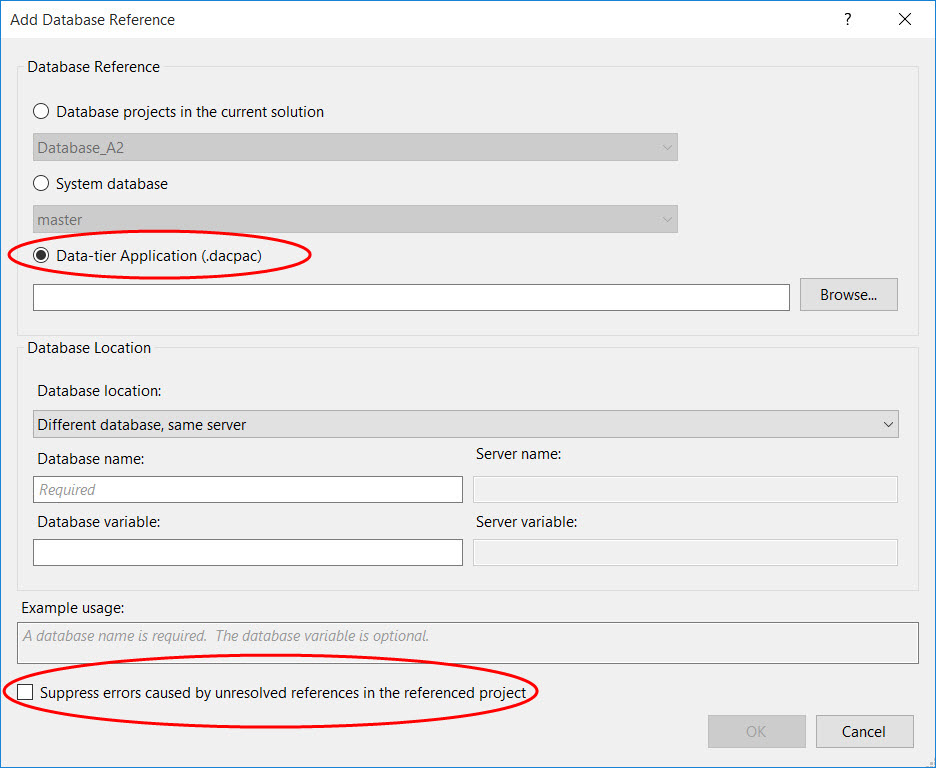
You would also check the ‘Suppress errors caused by unresolved references in the referenced project’ check box. Without this, when you build Database_B, it will follow the references from the dacpac file to wherever they point and try to find those objects, taking you back to your circular dependencies.
You could, of course, go a step further and do something like the following. This isn’t necessary for the purpose of breaking circular dependencies and might even be a little overkill, but I mention it here for the sake of completeness. Also, there might be specific use cases for it (such as more than 2 databases in your circular dependency model):
Comparison Between the Two Options
While you can use one of the two approaches above to get your circularly dependent databases into SSDT, note that both approaches convert circular dependencies into linear dependencies. There doesn’t yet exist a way to get truly circular dependencies into SSDT. Each approach has its benefits and compromises.
The ‘broken projects with direct references’ model will allow you to deploy your projects to brand new instances or servers very easily, and might just be the deciding factor if this is something you do frequently. You would first deploy the projects without any dependency on other projects, then those that depend only on the previously deployed projects, and so on till all your projects are deployed. The downside is that your database is broken up into one or more projects, and schema definitions for objects belonging to one database live in several locations.
This may not be a big problem if you are managing a small number of databases this way. But for anything more than a small handful of databases with several co-dependent objects, this could quickly get out of hand with the number of separate projects you have to maintain. You might end up with some databases broken into two, three or more projects. Multiply that by the number of databases in your solution. Not a very neat or manageable approach, imho.
The ‘complete projects with indirect references’ model takes more hoops to jump through for initial setup. You might have to create a few supporting projects with referenced schema items just so they (or their dacpac files) can be used as reference targets for other database projects. Depending on how you have this set up and how much schema churn you have, you may or may not have to update the supporting projects frequently.
Another drawback is that you will be unable to use this model to deploy to a virgin environment. Say you are trying to deploy Database_A to a new server instance that has no databases on it. Your deployment will fail because SSDT will not find Database_B on the server. This is because the deployment script will contain SQL code that defines schema objects in Database_A that reference Database_B, which does not exist on the server. Likewise, you will not be able to deploy Database_B because its objects require Database_A to exist. You could get around this setup problem by initially deploying the supporting projects for your databases, then the full projects in order from least dependent to most dependent. Once you have it set up, you could use your regular projects for further deployments.
Also, if your shop does not require setting up new instances frequently, you could just restore backups from other servers to get going. The advantage of this approach is that all objects belonging to one database live in one project. This is easier to manage than the alternative.
If you have circular dependencies and you are trying to figure out which model to adopt, I would encourage you to initially set up your databases using both approaches. If they are large and complex, perhaps use simplified versions with fewer schema objects, but be sure to mimic the dependencies. Then practice developing and deploying them with your team to determine which approach works best for you.
Footnotes
1. A related article on co-dependent database development in SSDT: A Complex Database Project in Visual Studio SSDT
2. If you wish to be technically specific, these will prevent you from building/deploying Database_A, but not Database_B. This is because you cannot create a view without the underlying table (this generates an error), but you can create a stored procedure without the underlying table (this only generates a warning). One of the quirks of SQL Server.
3. Often, SSDT will throw multiple errors due to just one erroneous piece of code/reference etc., and fixing the first error will frequently reduce your error count by more than 1. In this case, I go from 5 errors to 0 just by adding the database reference.
4. A dacpac file is basically a database’s entire schema definition in one file. Read up about it here.
