

This article - as is the case for many from many who wish to share their experiences, I suspect - was based on a solution to a real-world conundrum. The problem was deceptively simple: how to load data from one source system, using a specific data architecture, into a separate destination system which was based on a completely different relational model. Oh, and the source data was provided using a flattened (or denormalized) view of the data. Just to make life interesting, the source data would be provided without any usable primary or foreign key information, and the destination database used integer surrogate keys in all its tables that are generated using the SQL Server IDENTITY function. Of course the data has to be added to existing tables, so there are plenty of surrogate keys which exist already, and the enterprise architect wants the keys to be monotonically increasing, to ensure that the system can be queried as fast as possible using any existing applications.
The good news about this challenge is that the source data is that it is guaranteed not to contain any duplicate records, and is considered suitable cleansed, and ready for loading into a destination system. Also - and this is a non-trivial aspect of the problem - each row/record in the source data is a complete and coherent data set which maps to a discrete relational set in the destination tables. In other words, we do not have to handle isolating multiple rows/records in the source data set to establish a flattened or denormalized record, so no multi-row headaches. Finally, (and this is important) we are using SQL Server 2005 or 2008, and not an earlier version.
No real problem - indeed the client had a solution in place, which used a cursor to loop through the denormalized source data, and generate and apply surrogate keys. The problem with this process was that:
- It was verbose and hard to maintain
- It used multiple @SCOPE_IDENTITY references, with potential for error
- And worst of all, it took 2 hours to process a million row data source.
Now, before looking at solutions, I wish to sidestep two subjects -the use of cursors and the use of "Natural" as opposed to "Surrogate" keys. I know that both subjects arouse passions which can blind readers to any other technique or subject under discussion, and here I am simply focussing on a business requirement:
- Use surrogate keys as part of a corporate standard.
- Speed up a process - and using set-based logic seems a good place to start.
So if you prefer "Natural" keys and/or love/hate cursors - or whatever in any combination, then you will have to look elsewhere for a debate, as I am merely dealing with a solution to a specific problem, but one in my experience which can be applied to many data integration solutions.
Anyway, back to the problem to solve. Data appears in a large denormalized recordset (perhaps as a linked server OPENQUERY statement, an OPENROWSET statement, a complex multi-database query or even a flat file that you have imported into a staging table using SSIS) that you can access in SQL Server, and that you now have to normalise into a few tables. To simplify the example, while allowing it to illustrate the challenges, let's say that normalization involves three tables:
- A "Client" table
- An "Order Header" table
- An "Order Detail" table
To make the problem clearer, take a look at the following three sample rows from the source data, as it was delivered as a text file:
ClientName Town OrderNumber OrderDate ItemID ItemQuantity ItemCost ItemTotal
Jon Smythe Stoke 1 29/09/2009 777 5 9.99 49.95
Jon Smythe Stoke 2 25/10/2009 888 3 19.99 59.97
Jon Smythe Stoke 2 05/11/2009 999 10 49.99 499.9
And to complete the high-level perspective, here are the destination tables:
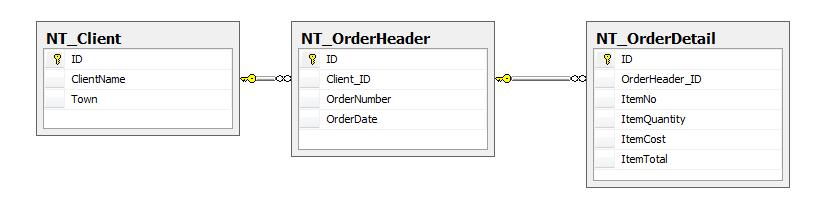
The DML for these tables is given in the attached code file. Obviously this is a gross simplification of the complexity and detail of the real source and destination data, but the aim here is to outline the concept, not share a several day headache!
Now, before leaping into some coding, let's take a step backwards and see the data as it has to be normalized:

So, if all is well thus far, we can see what columns have to be inserted into which tables.
So now we start to attack the real problem - how to set surrogate IDs which do not conflict with existing IDs in three data tables, and perform a fast load.
Just for a second, let's switch to the destination tables. The source data will add:
- One record to the "Client" table
- Two records to the "Order Header" table
- Three records to the "Order Detail" table
So there will be 1 new ID added to the "Client" table, two (and the corresponding Client ID) to the "Order Header" table, and three (and the corresponding Order Header ID) to the "Order Detail" table. This will maintain referential integrity on the source data.
So the next question seems to be, when do we add these IDs? There seem to be two main possibilities:
- When the data is added to the destination tables
- In the source table, then carried into the destination tables.
Now, as the current cursor-based solution uses the first approach, and out of a spirit of contradiction, I will try and use the second approach - add all required surrogate IDs to the denormalized source data, and see if that can be used to port the data into the normalized destination tables.
This seems to imply:
- Add a column to the source data table for each ID required for a destination table
- For each destination table, find the last (greatest) ID.
- Add IDs, increasing monotonically according to the relational structure.
Hang on, that last one sounds more complex. In fact it is not, it just means that, to take the example given above, the new columns will look like this:
ClientID OrderHeaderID OrderDetailID
1 1 1
1 2 2
1 2 3
So, at the lowest level of granularity, there will be a new, distinct ID for each Order Detail record, two IDs for the two Order Header records, and one ID for the client.
All well and good - but is it possible?
Surprisingly (or not depending on your level of cynicism), it is not only possible, but relatively straightforward. So time to get coding, and see how.
First, get your IDs
Nothing hard here, we just need to get the latest IDs from the IDENTITY column of two of the three destination tables. Yes indeed, only two are necessary in this scenario, as the surrogate ID for the lowest level table in the relational hierarchy (the NT_OrderDetail table in this example) can be added perfectly normally using an IDENTITY column
DECLARE @Client_ID INT
DECLARE @OrderHeader_ID INT
SELECT @Client_ID = ISNULL(IDENT_CURRENT('NT_Client'),0) + 1
SELECT @OrderHeader_ID = ISNULL(IDENT_CURRENT('NT_OrderHeader'),0) + 1
Notes:
- Note the use of ISNULL - this allows you to provide an initial identity value even if the table is empty.
- Yes, you can use MAX() to get the last I Identity value, but IDENT_CURRENT is apparently faster.
Second, grab your data
I will presume for the purposes of this example that the source data resides in a SQL Server staging table (though, as mentioned above, this does not have to be the case), and that we will SELECT the data, as follows:
SELECT
ClientName
,Town
,OrderNumber
,OrderDate
,ItemID
,ItemQty
,ItemCost
,ItemTotal
,CAST(NULL AS INT) AS Client_ID
,CAST(NULL AS INT) AS OrderHeader_ID
INTO #Tmp_SourceData
FROM dbo.NT_SourceData
Please note straight away a few important points:
- The source data is being used to populate a temporary table. This table can be output to disk in your database, or be a standard temp table as is shown here.
- If the source data is already in a SQL Server table, you may prefer to add any new columns required for the IDs, and update the source data in its original table, rather than using a temporary table.
- The addition of the two columns for the IDs, which will be updated once the table has been populated.
I have avoided all type conversions, data cleansing questions and real-world ETL potential pitfalls in this example deliberately, as they would distract from the point of the article. Of course, you may well have to apply business rules and data type conversions, as well as various levels of data sanitation to the input data, but if this is required, you may well find that it is best applied to the source data table, before dispatching into the relational structure.
Thirdly, Update the IDs corresponding to the remaining destination tables
We now need to provide IDs which will be used by the "Order Header" and "Client" tables. This is done by grouping the source data by whatever criteria allow you to isolate the corresponding records, and add ID as follows:
;
WITH OrderHeader_CTE (OrderNumber, ID)
AS
(
SELECT TOP (100) PERCENT
OrderNumber
,ROW_NUMBER() OVER (ORDER BY OrderNumber) + @OrderHeader_ID - 1 AS ID
FROM #Tmp_SourceData
GROUP BY OrderNumber
ORDER BY OrderNumber
)
UPDATE T
SET T.OrderHeader_ID = CTE.ID
FROM #Tmp_SourceData T INNER JOIN OrderHeader_CTE CTE
ON T.OrderNumber = CTE.OrderNumber
-- Set Client ID
;
WITH Client_CTE (ClientIdentifier, ID)
AS
(
SELECT TOP (100) PERCENT
ClientName + Town AS ClientIdentifier
,ROW_NUMBER() OVER (ORDER BY ClientName + Town) + @Client_ID - 1 AS ID
FROM #Tmp_SourceData
GROUP BY ClientName + Town
ORDER BY ClientName + Town
)
UPDATE T
SET T.Client_ID = CTE.ID
FROM #Tmp_SourceData T INNER JOIN Client_CTE CTE
ON T.ClientName + Town = CTE.ClientIdentifier
The points to note here are:
- Getting the grouping right is fundamental, and will depend on the nature of your data set.
- A CTE (as used here) is not the only solution to group and update, but it is, I feel, easier to understand and possibly maintain.
- The SQL Server 2005/2008 function ROW_NUMBER() allows the creation of monotonically incrementing numeric sequences, just like the IDENTITY function.
Fourth, add the data to the destination tables
Once the source data has had the required ID columns added (either to the original data, or as here to a temp table), the data can be output into the destination tables.
SET IDENTITY_INSERT NT_Client ON
INSERT INTO dbo.NT_Client
(
ID
,ClientName
,Town
)
SELECT
Client_ID
,ClientName
,Town
FROM dbo.#Tmp_SourceData
GROUP BY
Client_ID
,ClientName
,Town
SET IDENTITY_INSERT NT_Client OFF
-- Order Header - need "upper" & "lower" refs...
SET IDENTITY_INSERT NT_OrderHeader ON
INSERT INTO dbo.NT_OrderHeader
(
ID
,Client_ID
,OrderNumber
,OrderDate
)
SELECT
OrderHeader_ID
,Client_ID
,OrderNumber
,CONVERT(DATE, OrderDate, 126)
FROM dbo.#Tmp_SourceData
GROUP BY
OrderHeader_ID
,Client_ID
,OrderNumber
,OrderDate
SET IDENTITY_INSERT NT_OrderHeader OFF
-- Order Detail
-- don't need identity insert off for lowest table in hiererchy...
INSERT INTO dbo.NT_OrderDetail
(
OrderHeader_ID
,ItemNo
,ItemQuantity
,ItemCost
,ItemTotal
)
SELECT
OrderHeader_ID
,ItemID
,ItemQty
,ItemCost
,ItemTotal
FROM dbo.#Tmp_SourceData
drop table tempdb..#Tmp_SourceData
Note that:
- The data can be added to the destination tables in any order - as all IDs are in place only if (and this "if" probably only applies to ETL staging processes) there is no relational integrity in place on the destination tables. Otherwise the data must be added in the order "parent" -> "Child" -> "Grandchild" etc. - or you will get foreign key errors.
- You must SET IDENTITY_INSERT ON (and OFF afterwards) for each table.
- The grouping logic used to define the ID for each destination table must be the same as that used to identify the data when output to the destination table, or you will lose the relational structure.
Outcomes
So is this approach really worth the effort?
Well let's begin with let's see if the process runs any faster. Remember that one million rows took two hours previously. Well on the same rig using the approach described above, it took 104 seconds.
Yes, that's right, 1.44% of the original time taken - I make that to be 69 times faster.
"Ah", procedural programmers may say, "but were the data in the destination tables the same?"
Well,, erm... yes, absolutely. The corporate test team proved this conclusively.
What about code complexity and maintainability. This is, of course, harder to quantify. Let's say that the cursor-based approach took nearly twice as many lines of code, and leave it at that.
So what about system resources? Well here again tests showed that the set-based approach used considerably fewer resources. The. ahem, multiple stresses being placed on our test server during test mean that I do not care to publish the results. However if anyone wants to try this out and give me any valid comparison gigures, then I would be most grateful.
Further notes and ideas
Before getting carries away with this approach to data normalization, there are a few potentially negative points to consider.
One potential problem with this approach is the risk of another process inserting data into the destination tables while the whole data set is being inserted. Clearly this would mess up relational integrity in a major way. If you are updating data in a staging database, or as part of data preparation in a datawarehousing workflow, then you probably control the entire procedure, and can ensure that no other processes are running in parallel. If this is the case, then as long as you maintain careful control of your ETL, there should be no problems.
Conclusions
So we are looking at a massive speed gain, and much simpler coding than the cursor-based approach. Certainly the approach may require a little experimentation in order better to comprehend it, but there can be no doubt that productivity and maintainability were drastically improved this way with this data set.

