

Introduction
Often in database development, developers need to query to find the data differences between two tables. One approach is to use SQL Server's EXCEPT operator, as described in detail by Stephen Tirone (http://www.sqlservercentral.com/articles/T-SQL/69046/). This technique works very well when the data values to be compared are 100% identical, down to the last decimal point. At times, however, numeric values deviate slightly, and an alternate method that accounts for these deviations is needed. For example, the developer might want the numbers 4.4999 and 4.5000 to be considered equal for the purposes of the comparison, which is beyond the capabilities of an EXCEPT comparison. This article offers an alternate approach, which applies a FULL JOIN to generate a difference report and can apply a numerical tolerance to filter the differences as desired.
Example
Create two tables, SourceTable and DestinationTable.
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[SourceTable]') AND type in (N'U')) DROP TABLE [dbo].[SourceTable] GO IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[DestinationTable]') AND type in (N'U')) DROP TABLE [dbo].[DestinationTable] GO CREATE TABLE SourceTable ( ID INT NOT NULL PRIMARY KEY, RandomNumber DECIMAL(18,4) NOT NULL ); CREATE TABLE DestinationTable ( ID INT NOT NULL PRIMARY KEY, RandomNumber DECIMAL(18,4) NOT NULL ); GO
Next, populate the SourceTable with 5 rows of sample data, then duplicate it exacty to the DestinationTable. (As these are random numbers, your results will be different).
--Generate 5 rows of random sample data using a recursive CTE
--Use newID() to get a unique value for each row, as rand() returns the same number for each row.
DECLARE @numrows INT; SET @numrows = 5;
WITH Q1 AS (
--Anchor portion
SELECT
1 AS ID,
ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT)) / 100.0 AS RandomNumber
UNION ALL
--recursive portion
SELECT
ID + 1 AS ID,
ABS(CAST(CAST(NEWID() AS VARBINARY) AS INT)) / 100.0 AS RandomNumber
FROM Q1
WHERE ID < @numrows
)
INSERT INTO SourceTable (ID, RandomNumber)
SELECT ID, RandomNumber
FROM Q1
OPTION (MaxRecursion 0);
--Duplicate the table exactly from SourceTable into DestinationTable
INSERT INTO DestinationTable (ID, RandomNumber)
SELECT ID, RandomNumber
FROM SourceTable
Now, use the EXCEPT method to query for any row differences.
--query for differences between the two datasets, using an EXCEPT query SELECT 'Src-->Dest' AS Label, * FROM ( SELECT * FROM SourceTable EXCEPT SELECT * FROM DestinationTable ) LEFT_DIFFS UNION SELECT 'Dest-->Src' AS Label, * FROM ( SELECT * FROM DestinationTable EXCEPT SELECT * FROM SourceTable ) RIGHT_DIFFS ;
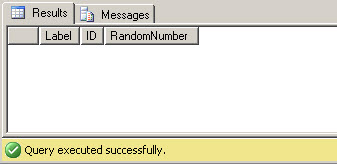
The results, as expected, are an exact match, and this EXCEPT query returns no results.
Next, let's simulate the situation where the data has a slight deviation, such as in the third or fourth decimal place. In practice, this kind of deviation can occur as a result of rounding error, such as the case when the source and destination tables arrive at the same numbers via different formulas or methods. It can also happen when FLOAT datatypes are used, as FLOATS don't guarantee precision as do fixed-decimal point datatypes such as INTEGER or DECIMAL.
--create a tiny deviation (4th decimal place) in each randomnumber in the destination table. UPDATE SourceTable SET RandomNumber = RandomNumber + (CAST(CAST(NEWID() AS VARBINARY) AS INT) / 1000000000000.0); --rerun the row difference query SELECT 'Src-->Dest' AS Label, * FROM ( SELECT * FROM SourceTable EXCEPT SELECT * FROM DestinationTable ) LEFT_DIFFS UNION SELECT 'Dest-->Src' AS Label, * FROM ( SELECT * FROM DestinationTable EXCEPT SELECT * FROM SourceTable ) RIGHT_DIFFS ;
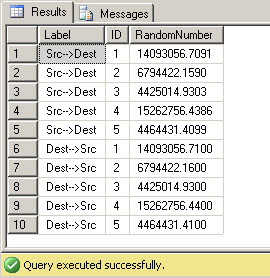
The EXCEPT query now returns every row twice, as it's meant to return ANY deviation between source and destination.
An Alternative - Full Joins
Next, let's take a look at an alternative technique using a full join. Full joins work by combining a LEFT OUTER, INNER, and RIGHT OUTER join into one query. Thus, any rows that match, have only a left side, or only a right side, are returned. To avoid a Cartesian product, full joins need to match on one or more columns, generally the primary key.
In our example, we're matching on the simple 'ID' primary key. Note that if the column(s) used to join are nullable, make sure to wrap them with ISNULL() on each side of the join to get an accurate comparison. Usually full joins are combined with the COALESCE() function, which returns the first non-null value it finds. This is important to include, so that all rows from either the left or the right are returned, regardless of whether they have a match on the 'other' side of the join. This will become clear in a moment.
--query for differences between the two datasets, using a FULL JOIN. WITH SRC AS ( SELECT ID, RandomNumber FROM SourceTable ), DEST AS ( SELECT ID, RandomNumber FROM DestinationTable ), DIFFS AS ( SELECT COALESCE(S.ID, D.ID) AS ID, S.RandomNumber AS SrcRandomNumber, D.RandomNumber AS DestRandomNumber, ISNULL(S.RandomNumber, 0) - ISNULL(D.RandomNumber, 0) AS RandomNumberDiff FROM SRC S FULL JOIN DEST D ON S.ID = D.ID ) SELECT * FROM DIFFS;
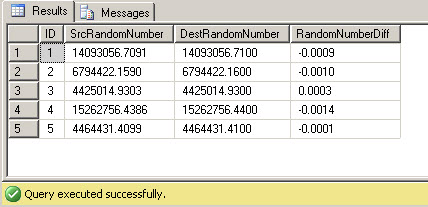
This query returns the ID, source value, destination value, and difference between the two. I prefer to construct these difference queries as 2 CTEs ("WITH" queries) at the top, followed by the comparison query, as this provides the most readable and maintainable query structure. Notice the use of the ISNULL() functions in the RandomNumberDiff column. This is needed to report on any differences when the matching row does not exist on the source or destination side, i.e. when the row is missing or extra from source to destination. Let's produce both of those scenarios as the next example.
--Insert one new record in the source that's not matched in the destination. INSERT INTO SourceTable (ID, RandomNumber) VALUES (6, 1234567.890); --Insert one new record in the destination that's not matched in the source. INSERT INTO DestinationTable (ID, RandomNumber) VALUES (7, 98765.432);
Now, rerun the same full join difference query as before. We can see that the new rows don't have an equivalent matching entry in the other table. The new records either have a null source or destination value field, yet the difference field still returns a number, thanks to the ISNULL(<field>, 0) function in the query.
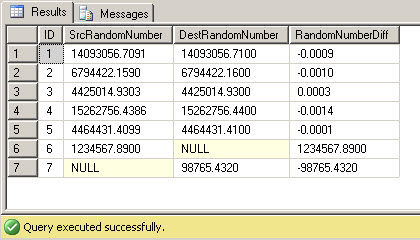
Finally, let's say that we only want to find deviations over 10 cents, so that all these differences at the 3rd or 4th decimal place fall out of the analysis. We simply need to define a tolerance variable and filter the query to only include deviations outside that tolerance with a WHERE clause.
DECLARE @Tolerance DECIMAL(18,4); SET @Tolerance = 0.10; WITH SRC AS ( SELECT ID, RandomNumber FROM SourceTable ), DEST AS ( SELECT ID, RandomNumber FROM DestinationTable ), DIFFS AS ( SELECT COALESCE(S.ID, D.ID) AS ID, S.RandomNumber AS SrcRandomNumber, D.RandomNumber AS DestRandomNumber, ISNULL(S.RandomNumber, 0) - ISNULL(D.RandomNumber, 0) AS RandomNumberDiff FROM SRC S FULL JOIN DEST D ON S.ID = D.ID ) SELECT * FROM DIFFS WHERE ABS(RandomNumberDiff) > @Tolerance;
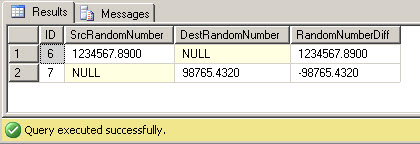
Now, with the tolerance variable defined and used in the query predicate, the miniscule differences fall out of the report, and only the two unmatched records are reported as differences.
WRAP UP
This full join comparison technique can be useful when running dataset comparisons that require a numerical tolerance. An added benefit is that it includes the exact difference between source and destination, which can be useful for further analysis or even ETL operations. In a future article, I'll explain how to use this technique for synchronizing between source and destination tables, by pushing just the difference records into the destination table incrementally.

