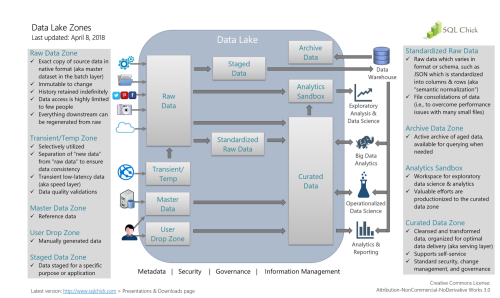
I subscribe to the idea of using zones in a data lake, and having a "raw zone" that is immutable. The data in other zones should be replaceable by rerunning a repeatable process that "selects" data form the immutable raw zone and places/replaces it in the downstream zone. Melissa Coates has a great diagram showing a data lake with different zones for a visual: https://www.sqlchick.com/entries/2017/12/30/zones-in-a-data-lake