Should the Data Lake be Immutable?
-
Comments posted to this topic are about the item Should the Data Lake be Immutable?
-
In my world a data lake is not a data warehouse.
The data lake contains data in as near to the raw source data format as possible at the time it was captured. The general idea is that it is cheap storage into which data can be stored indefinitely. It isn't a database as traditionally described. I'd say that, yes, it should be immutable.The data warehouse is a thing of rigour and discipline where facts become available at different times and therefore updates may be required. If I am using the Kimball model then I have the various slow changing dimension (SCD) approaches to choose from. This has to be driven by business requirements. As the business requirements change then the data lake means I can revisit the SCD strategy on the basis of those requirements.
Even if I tilt towards something more Inmon esque I may still need the concept of updateable data due to facts becoming available out of sequence. For example, the process of switching an energy supplier is a lengthy process for many reasons including legislated cooling off periods. There is valuable insight (subject to GDPR permissions from the customer) even though the data won't be fully complete until 2 months after the original application.
-
I am a fan of anchor modelling and temporal databases. I find powerful the idea that the database's current dataset includes all previous datasets, and that the current schema version includes all previous schema versions. One organization should be able to obtain today a report with the same results already obtained in the past, even if the underlaying dataset has been corrected, completed, or has evolved in any way. A data warehouse should be a temporal database, allowing to provide information both in its current state and in the past states (when it was still wrong or incomplete), as well as provide details on when and how was later corrected, completed or even deleted. And the same concept should apply to a datalake, whatever its implementation. Rather tan "immutable", it should be updatable in a non-destructive way.
-
Just because a dataset is immutable doesn't mean we can't amend it when looked at.
-
Is this more of a religious debate about whether everybody is 'sposta' make their data lake immutable?
Azure Blob Storage already has an optional immutable (Write Once, Read Many) feature. It's used by financial, legal and other industries that must comply with auditing and retention regulations.
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-immutable-storage"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
-
The first question that should be asked is, should you even have a data lake or data warehouse?
Harking back to the whole security issue, a data lake is precisely the kind of holy grail hackers would be salivating for. Since you're dumping (mostly) raw data into it, what are the chances that it contains PII? Or even sensitive information that could embarrass/seriously threaten your company?
Second, if you make the data immutable how do you update data that's erroneous? Or delete data in accordance with GDPR / some as yet unwritten law?
I suspect immutability should be asked after asking if you should even have the data lake or warehouse in the first place.
- Eric M Russell - Tuesday, February 26, 2019 6:49 AM
Eric, you make an excellent point on the legal aspect, and it is the first thing that came to mind when I read the article. My wife and I are actually involved in a legal situation that is scheduled to go to trial in April. and the historical aspect of the original medical data is critical. In our situation, one of the first things I did three years ago was collect records as they existed at that time, under the guise of providing them to our other medical care providers. Of course, the argument of modification can work both ways, and we as technical people understand that, but at least we have basis for argument in the event data has been 'interpreted'.
As another aside here, the current trend in attempting to 'rewrite history' in this nation presents an interesting situation in the effort to have it both ways, depending on motivation. As the current discussion of 'reparations' illustrates, financial motivation is a powerful force, and the victims are not always the perpetrators. Rewriting history can change who the victims are.
The legal ramifications of data are immense regardless of it's veracity.
Rick
Disaster Recovery = Backup ( Backup ( Your Backup ) ) - roger.plowman - Tuesday, February 26, 2019 7:24 AM
Having or not having data is a real problem in the legal arena, and can help or hurt. Obviously it can and does work both ways, and unfortunately will likely depend on the skills of your legal defense versus the opposition. Ideally I would have to favor the historical method of correcting rather than modifying the original, but either way carries its own risks. At least preserving history and making a real record of corrections offers an honest approach and would serve to remove suspicion of tampering from consideration of other problems.
Rick
Disaster Recovery = Backup ( Backup ( Your Backup ) ) - roger.plowman - Tuesday, February 26, 2019 7:24 AM
In a lot of cases yes there is usually a lot of value for a company to be able to see historically what changes have been made to data over time. And as was mentioned above from auditing perspective it might in fact be required to store historical change of PII.
-
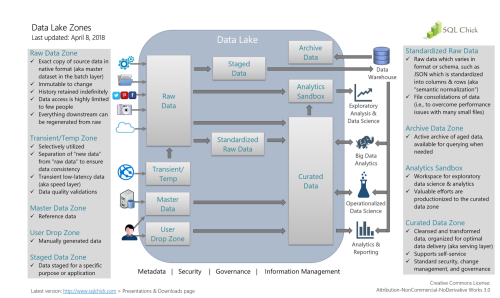
I subscribe to the idea of using zones in a data lake, and having a "raw zone" that is immutable. The data in other zones should be replaceable by rerunning a repeatable process that "selects" data form the immutable raw zone and places/replaces it in the downstream zone. Melissa Coates has a great diagram showing a data lake with different zones for a visual: https://www.sqlchick.com/entries/2017/12/30/zones-in-a-data-lake

- kinzleb - Tuesday, February 26, 2019 8:03 AM
Great thinking and an excellent solution to the situation. I love it! I'll run down the link. Thanks.
Rick
Disaster Recovery = Backup ( Backup ( Your Backup ) ) - kinzleb - Tuesday, February 26, 2019 8:03 AM
Very interesting idea. I've never seen this approach. Another team (I'm not on it) are considering how to handle data lakes (although they're not using that term) right now. I'm going to bring this to their attention. Thank you!
Kindest Regards, Rod Connect with me on LinkedIn.
-
Maybe I'm missing something, but the CS idea of immutable doesn't mean the variable can't change. It just means it needs to be copied, which can be expensive.
For instance in C#:
String x = new String("abc")';
x = x + "def";
Is perfectly legit. But the run time x to a temp place, reallocates x then concatenates it.
The issue is efficiency, which is why C# (and I believe Java) have StringBuffer. That is allocated dynamically,Hope this helps.
JJ
- jj3pa - Tuesday, February 26, 2019 1:19 PM
JJ3pa, I think we're thinking more along the lines of the pros and cons of 'fixing' original data that is proven defective, versus making adjustments that can be traced historically, keeping the original in tact and unmodified. For instance, if you identify that a system has a bug that is creating invalid data, how much do you fix by alteration and how much to you fix by traceable adjustments. In other words, do you bury the evidence, or provide evidence why the data is being modified. One can always adjust results without altering the elements.
My experience is that by far the greatest problem is getting management to admit that the original data is invalid and that something needs to be done. All downhill from there. 🙂
Regarding the example provided above, I like it overall, but might suggest that the original data actually be taken 'offline' and archived in the event is it appropriately needed. This accomplishes availability AND protection Just because cloud space is available doesn't mean it MUST be used. Offline data in the company vault is sometimes good, even off-premises. Even back in the 70's I was trading off-premises bulk data storage with another company nearby. It was secured in company vaults and extremely inexpensive, and we always had the unmodified version.
Rick
Disaster Recovery = Backup ( Backup ( Your Backup ) ) - skeleton567 - Tuesday, February 26, 2019 1:53 PM
I'm sorry, I wasn't speaking in db terms - I'm a newbie at that :). That's why I'm here, to learn from you guys and gals. I just meant perhaps it takes a different meaning in CS vs DB circles.
I'm getting my head around window functions 🙂jj
Viewing 15 posts - 1 through 15 (of 23 total)
You must be logged in to reply to this topic. Login to reply