Finding the MIN or a group of values not used in a previous group
-
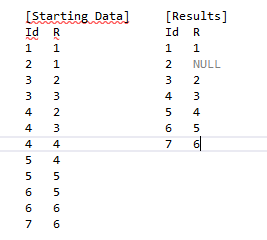
I have been having trouble finding anything on google because I'm not sure how to phrase the search. What I need to do is to select the MIN R from each Id group that hasn't already been selected by a previous group. This is the trimmed down version with an example of a row that has no R value.
I have a table simplified
CREATE TABLE Data(Id int, R int)
INSERT INTO Data VALUES(1,1),(2,1),(3,2),(3,3),(4,2),(4,3),(4,4),(5,4),(5,5),(6,5),(6,6),(7,6)
I think I should be able to do it using a tally table and window functions, but the grouping is giving me a headache. I want the min in the group that has not been previously used. I know I can create a cursor to do what I want, but I think there should be a way to do this set based. Any help is appreciated. - Chris Souchik - Thursday, November 1, 2018 12:13 PM
So expected results based on the above data.
-
This may not be the most efficient, but I believe it works, and shouldn't be too much overhead anyway unless you have lots of unqiue Ids:
;WITH cte_group AS (
SELECT Id, MIN(R) AS R
FROM Data
GROUP BY id
)
SELECT cg.Id, cg_unique.R
FROM cte_group cg
LEFT OUTER JOIN (
SELECT *, ROW_NUMBER() OVER(PARTITION BY R ORDER BY Id) AS row_num
FROM cte_group
) AS cg_unique ON cg_unique.row_num = 1 AND cg_unique.Id = cg.IdSQL DBA,SQL Server MVP(07, 08, 09) A socialist is someone who will give you the shirt off *someone else's* back.
-
Correct
-
Scott,
Very close, but I am seeing this:
Id 4 should not be null it should be 3. Thanks -
I think this will do it:
with X as
(
select id, max(R) over (order by id, R) as maxR
from #Data
),
Y as
(
select id, min(maxR) as R
from X
group by id
)
select
id, nullif(R, lag(R,1) over (order by id))
from Y -
My entry...
IF OBJECT_ID('tempdb..#TestData', 'U') IS NOT NULL
BEGIN DROP TABLE #TestData; END;CREATE TABLE #TestData (
Id INT NOT NULL,
R INT NOT NULL
);
INSERT #TestData(Id, R) VALUES
(1,1),(2,1),(3,2),(3,3),(4,2),(4,3),(4,4),(5,4),(5,5),(6,5),(6,6),(7,6);--================================================================================
SELECT
x1 .Id,
R = CASE WHEN x1.R > ISNULL(MAX(x1.R) OVER (ORDER BY x1.R, x1.Id ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 0) THEN x1.R END
FROM (
SELECT
td .Id,
td.R,
r1 = ISNULL(MIN(td.R) OVER (PARTITION BY td.Id ORDER BY td.Id, td.R ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), td.R),
r2 = ISNULL(MAX(td.R) OVER (ORDER BY td.Id, td.R ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 0)
FROM
#TestData td
) x1
WHERE
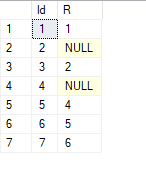
x1.R = CASE WHEN x1.r1 >= x1.r2 THEN x1.r1 ELSE x1.r2 END;Results...
Id R
----------- -----------
1 1
2 NULL
3 2
4 3
5 4
6 5
7 6 - andycadley - Thursday, November 1, 2018 1:14 PM
Very nice!
-
Andy and Jason,
Thanks for your solution. It works great on this data set, but unfortunately it doesn't work for all data sets. For example,
I'm starting to think it may be easier to use a cursor, even if it will be slower. The recursive nature of the query may not allow a set based solution, at least it has me stumped.
-
I also think, it would need a recursive solution to since lead / lag values based solution looks at the values when the query was kicked off and doesnt get influenced by the values that changes when the query progresses.
I could do this using recursive cte as follows
CREATE TABLE Data(Id int, R int)
INSERT INTO Data VALUES (1,1);
INSERT INTO Data VALUES (2,1);
INSERT INTO Data VALUES (3,2);
INSERT INTO Data VALUES (3,3);
INSERT INTO Data VALUES (4,2);
INSERT INTO Data VALUES (4,3);
INSERT INTO Data VALUES (4,4);
INSERT INTO Data VALUES (5,4);
INSERT INTO Data VALUES (5,5);
INSERT INTO Data VALUES (6,5);
INSERT INTO Data VALUES (6,6);
INSERT INTO Data VALUES (7,6);/*
truncate table dataINSERT INTO Data VALUES (1,1);
INSERT INTO Data VALUES (2,1);
INSERT INTO Data VALUES (2,2);
INSERT INTO Data VALUES (2,3);
INSERT INTO Data VALUES (3,3);*/with data1
as (select id /*This block only to generate row_numbers based on the records in the table..*/
,r
,row_number() over(order by id,r) as rnk
from data
)
,cte(id,r,rnk,grp_flag,concat_val)
as (select a.id,a.r,a.rnk,1 as grp_flag,cast(a.r as varchar2(100)) as concat_val
from data1 a
where rnk=1 /*Start with first record and construct the concat_val only if the "r" is not previously used and "r" value is not already populated for the id*/
union all
select b.id,b.r,b.rnk,case when a.id=b.id and a.grp_flag=1 then 0
else case when a.concat_val like '%'||b.r||'%' then 0
else 1
end
end as grp_flag
,case when a.id=b.id and a.grp_flag=1 then a.concat_val
else case when a.concat_val like '%'||b.r||'%' then a.concat_val
else b.r||'/'||a.concat_val
end
end as concat_val
from cte a
join data1 b
on a.rnk+1=b.rnk
)
select x.id,y.r
from ( select distinct id
from data1
) x
left join cte y
on x.id=y.id
and y.grp_flag=1
order by x.id -
Did the above query work out?
-
George,
I will try and test this today. At a quick glance, it looks promising.
Thanks,
Chris -
Unfortunately really busy week. I haven't had a chance to review yet. Will update when I get a chance. Thanks
-
Here's an actual cursor. I thought about this one for a long time, and realized I could not use a recursive CTE and still use any form of aggregate, or a 2nd reference to the CTE itself. That was really crimping my style, so I gave up and went this way instead. Run times were about 0.01563 seconds, +/-, before caching took over and both queries would run instantaneously. Fortunately, it works for both sets of input data:
SET NOCOUNT ON;
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;IF OBJECT_ID(N'tempdb..#Results', N'U') IS NOT NULL
BEGIN
DROP TABLE #Results;
END;CREATE TABLE #Data(
Id int,
R int
);
INSERT INTO #Data (Id, R)
VALUES (1,1),
(2,1),
(3,2),
(3,3),
(4,2),
(4,3),
(4,4),
(5,4),
(5,5),
(6,5),
(6,6),
(7,6);CREATE TABLE #Results (
Id int NOT NULL PRIMARY KEY CLUSTERED,
MIN_R int NULL
);DECLARE @Id AS int, @r AS int, @First AS int = 1, @BegDateTime AS datetime2 = sysdatetime(),
@EndDateTime AS datetime2;DECLARE MYCURSOR CURSOR FAST_FORWARD READ_ONLY FOR
SELECT
D.Id,
MIN(D.R) AS R
FROM #Data AS D
GROUP BY D.Id;OPEN MYCURSOR;
FETCH NEXT FROM MYCURSOR INTO @Id, @r;WHILE @@FETCH_STATUS = 0
BEGIN;
IF @First = 1
BEGIN;
BEGIN TRAN;
INSERT INTO #Results (Id, MIN_R)
VALUES (@Id, @r);
COMMIT TRAN;
END;
ELSE
BEGIN;
BEGIN TRAN;
INSERT INTO #Results (Id, MIN_R)
VALUES (@Id,
CASE
WHEN (
SELECT MIN(D.R)
FROM #Data AS D
WHERE D.R NOT IN (SELECT R.MIN_R FROM #Results AS R WHERE R.MIN_R IS NOT NULL AND R.Id < @Id)
AND D.Id = @Id
) IS NULL
AND (SELECT COUNT(1) FROM #Data AS D WHERE D.Id = @Id) = 1
THEN NULL
ELSE (
SELECT MIN(D.R)
FROM #Data AS D
WHERE D.R NOT IN (SELECT R.MIN_R FROM #Results AS R WHERE R.MIN_R IS NOT NULL AND R.Id < @Id)
AND D.Id = @Id
)
END)
COMMIT TRAN;
END;SET @First = @First + 1;
FETCH NEXT FROM MYCURSOR INTO @Id, @r;
END;CLOSE MYCURSOR;
DEALLOCATE MYCURSOR;SET @EndDateTime = sysdatetime();
PRINT 'Total Run Time, Query Only: ' + CONVERT(varchar(11), CONVERT(decimal(10,9), DATEDIFF(microsecond, @BegDateTime, @EndDateTime)/1E6)) + ' Seconds';SELECT *
FROM #Data
ORDER BY Id;SELECT *
FROM #Results AS R
ORDER BY R.Id;
GOSET NOCOUNT ON;
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;IF OBJECT_ID(N'tempdb..#Results', N'U') IS NOT NULL
BEGIN
DROP TABLE #Results;
END;CREATE TABLE #Data(
Id int,
R int
);
INSERT INTO #Data (Id, R)
VALUES (1,1),
(2,1),
(2,2),
(2,3),
(3,3);CREATE TABLE #Results (
Id int NOT NULL PRIMARY KEY CLUSTERED,
MIN_R int NULL
);DECLARE @Id AS int, @r AS int, @First AS int = 1, @BegDateTime AS datetime2 = sysdatetime(),
@EndDateTime AS datetime2;DECLARE MYCURSOR CURSOR FAST_FORWARD READ_ONLY FOR
SELECT
D.Id,
MIN(D.R) AS R
FROM #Data AS D
GROUP BY D.Id;OPEN MYCURSOR;
FETCH NEXT FROM MYCURSOR INTO @Id, @r;WHILE @@FETCH_STATUS = 0
BEGIN;
IF @First = 1
BEGIN;
BEGIN TRAN;
INSERT INTO #Results (Id, MIN_R)
VALUES (@Id, @r);
COMMIT TRAN;
END;
ELSE
BEGIN;
BEGIN TRAN;
INSERT INTO #Results (Id, MIN_R)
VALUES (@Id,
CASE
WHEN (
SELECT MIN(D.R)
FROM #Data AS D
WHERE D.R NOT IN (SELECT R.MIN_R FROM #Results AS R WHERE R.MIN_R IS NOT NULL AND R.Id < @Id)
AND D.Id = @Id
) IS NULL
--AND (SELECT COUNT(1) FROM #Data AS D WHERE D.Id = @Id) = 1
THEN NULL
ELSE (
SELECT MIN(D.R)
FROM #Data AS D
WHERE D.R NOT IN (SELECT R.MIN_R FROM #Results AS R WHERE R.MIN_R IS NOT NULL AND R.Id < @Id)
AND D.Id = @Id
)
END)
COMMIT TRAN;
END;SET @First = @First + 1;
FETCH NEXT FROM MYCURSOR INTO @Id, @r;
END;CLOSE MYCURSOR;
DEALLOCATE MYCURSOR;SET @EndDateTime = sysdatetime();
PRINT 'Total Run Time, Query Only: ' + CONVERT(varchar(11), CONVERT(decimal(10,9), DATEDIFF(microsecond, @BegDateTime, @EndDateTime)/1E6)) + ' Seconds';SELECT *
FROM #Data
ORDER BY Id;SELECT *
FROM #Results AS R
ORDER BY R.Id;Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy)

Viewing 14 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply