T-SQL help needed to eliminate duplicates from table
-
To make a long story short, one of our tables that have rx data has got messed up because the files get loaded more than one and as a result we now have duplicate records. Your help is needed to clean this up.
So to make the problem simple, I created a script to describe the issue. MEMBER 1234 has 4 records for 100.00. I only need 2 of them. Why ? One of them is needed to cancel out with the record that has -100.00 in the amt_adjusted column. THen out of the 3 remaining. One is a new charge and the other 2 are simply duplicates. Same issue with the user 4567.
So help me with the syntax of eliminating the duplicates.
If object_id(‘tempdb..#t’) IS NOT NULL DROP TABLE #t
Create table #t( member varchar(10), amt_paid MONEY, amt_adjusted MONEY, dt VARCHAR(8) );
INSERT INTO #t( member,amt_paid,amt_adjusted,dt)
Select ‘1234’, 100.00,0.00, ‘20180101’
UNION
Select ‘1234’, 0.00,-100.00, ‘20180101’
UNION
Select ‘1234’, 100.00,0.00, ‘20180101’
UNION
Select ‘1234’, 100.00,0.00, ‘20180101’
UNION
Select ‘1234’, 100.00,0.00, ‘20180101’
UNION
Select ‘4567’, 100.00,0.00, ‘20180101’
UNION
Select ‘4567’, 0.00,-100.00, ‘20180101’
UNION
Select ‘4567’, 100.00,0.00, ‘20180101’
UNION
Select ‘4567’, 100.00,0.00, ‘20180101’
UNION
Select ‘4567’, 100.00,0.00, ‘20180101’
-
syntax is "delete from table where key = (desired key to delete)"
So what have you tried so far and why has it failed e.g. expected results and the real results of your attempt at doing it alongside the logic for doing it the way you did.
And I do expect to see more than 1 type of sql for this.
-
Like this? It's not super clear what you want. In this case, a sample expected result would be a big help. Something like this?
Create table #t( member varchar(10), amt_paid MONEY, amt_adjusted MONEY, dt VARCHAR(8) );
GOINSERT INTO #t( member,amt_paid,amt_adjusted,dt)
VALUES ( '1234', 100.00,0.00, '20180101')
,('1234', 0.00,-100.00, '20180101')
,('1234', 100.00,0.00, '20180101')
,('1234', 100.00,0.00, '20180101')
,('1234', 100.00,0.00, '20180101')
,('4567', 100.00,0.00, '20180101')
,('4567', 0.00,-100.00, '20180101')
,('4567', 100.00,0.00, '20180101')
,('4567', 100.00,0.00, '20180101')
,('4567', 100.00,0.00, '20180101');SELECT *
FROM (
SELECT member
, amt_paid
, amt_adjusted
, dt
, row_number() over (PARTITION BY member, amt_paid, amt_adjusted, dt ORDER BY member, amt_paid, amt_adjusted, dt ) dup
FROM #t ) x
WHERE x.dup = 1; -
Kinda would help if I wrote an actual delete query... =)
Test the CTE out by doing SELECT from it first instead of DELETE;WITH
cteMembers(member, amt_paid, amt_adjusted, dt, dup)
AS
(
SELECT member
, amt_paid
, amt_adjusted
, dt
, row_number() over (PARTITION BY member, amt_paid, amt_adjusted, dt ORDER BY member, amt_paid, amt_adjusted, dt ) dup
FROM #t
)
DELETE
FROM cteMembers
WHERE dup>1; - mw_sql_developer - Sunday, June 10, 2018 3:00 PM
Fundamental mistake in the sample data, you must use UNION ALL, otherwise the sample set will NOT have any duplicates!
😎 -
Virtually everything here is wrong. SQL Server has had table constructors in it's insertion statement for several years now; so there is no need to use the old Sybase SELECT-UNION notations (which are not standard ANSI ISO SQL). The other problem is that you meant to say union all, because union by itself removes duplicates.
By definition, and not by option, a valid table must have a key. Essentially what you've got here is a deck of punch cards written with SQL. Your column names do not follow ISO 11179 naming rules. There is no reason to use character data when we have a DATE data type. Never use the old Sybase money datatype; it literally does not work! It has rounding errors when you multiply or divide. It also violates EU rules about financial calculations, as well as GAAP rules in the United States. Google it.
Let's start by making your bad code, less bad. This code is still crap, but it's a little better:
CREATE TABLE Foobar
(member_id VARCHAR(10) NOT NULL,
payment_amt DECIMAL(10, 2) DEFAULT 0.00 NOT NULL
adjustment_amt DECIMAL(10, 2) DEFAULT 0.00 NOT NULL,
foobar_date DATE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (??? )
);At least the names are right and the datatypes are correct. Notice the use of default values. Here is your insertion statement written in current notation.
INSERT INTO Foobar
VALUES
('1234’, 100.00, 0.00, '2018-01-01’),
( ‘1234’, 0.00, -100.00, '2018-01-01’),
( ‘1234’, 100.00, 0.00, '2018-01-01’),
( ‘1234’, 100.00, 0.00, '2018-01-01’),
( ‘1234’, 100.00, 0.00, '2018-01-01’),
( ‘4567’, 100.00, 0.00, '2018-01-01'),
( ‘4567’, 0.00, -100.00, '2018-01-01’),
( ‘4567’, 100.00, 0.00, '2018-01-01’),
( ‘4567’, 100.00, 0.00, '2018-01-01’),
( ‘4567’, 100.00, 0.00, '2018-01-01’);My recommendation for your problem is to first find the guy the created this table and fire him. I've been at this for 30+ years and have found the main problem is incompetent people. Once he is gone, examine every piece of code he's written. With so many mistakes in one table, it is quite likely that the rest of his work is just as bad or worse.
I would then move the non-table data over to a file, sort it and scrub it, then loaded into a new properly designed table. Having done a few of this sort of cleanups, I found trying to do it in SQL is usually just a waste of time. Sometimes things are so bad, you just have to throw them out and start over.
Please post DDL and follow ANSI/ISO standards when asking for help.
- Eirikur Eiriksson - Monday, June 11, 2018 2:47 AM
Mr Eirikur Eiriksson: I dont use UNION or UNION ALL in real life. I only used this for the purpose of creating a sample script. In real life the data is loaded via a SSIS module. The error occurs because the same transaction can be in many files ( Example This months data may appear again in next months file, so it gets loaded 2 times )
- pietlinden - Sunday, June 10, 2018 5:08 PM
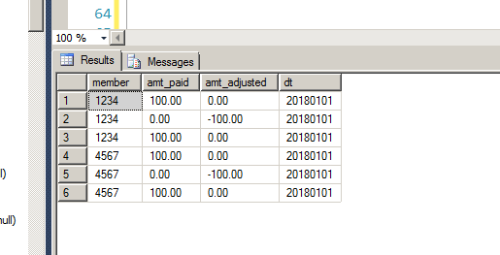
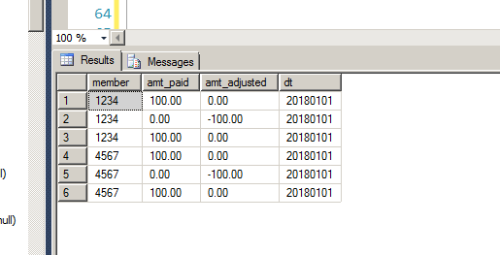
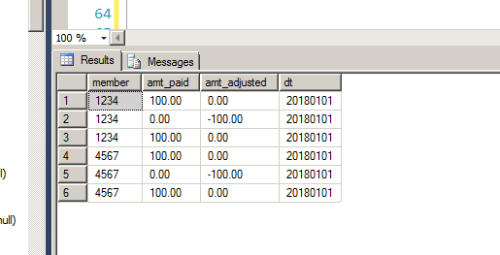
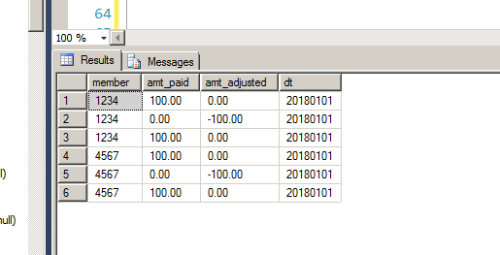
Expected Output:

My explanation:
#2 cancels out #1. #3 was resubmitted. So #3 has to remain
What happend here is They paid #1 and then found out it was in error. So they created #2 which cancels out #1. Now later the customer sent a new claim again and this got inserted #3
ISSUE : When loading multiple files, #3 got loaded several times..BTW- This is not a simple issue of getting rid of duplicates... What needs to happen is:
1.) get rid of all duplicates that have a negative value ( amt_adjusted < 0 ).
2.) for each of the records ( where amt_adjusted < 0 ) find the matching partner and keep him.
3.) From the remaining records ( That have the amt_adjusted = 0 ) Keep one record and delete others.Thank you for your effort so far, i think i have a solution in mind and i am working on it based on the above 3 steps...
Shall post it later.
But if you do have a short quick reply please post. - jcelko212 32090 - Monday, June 11, 2018 9:23 AM
Mr Joe:
Please ! Please !
This is not about correcting syntax. I created the script so that a reader will have something to work on......
My issue is only about getting rid of certain duplicates.....
In other words, this is what i need help. Using the above data ( in my original script ) can you write SQl code that will give me the following outpout - mw_sql_developer - Sunday, June 10, 2018 3:00 PM
Sorry....
To make it clear...
Here is the output I expect... -
One more time... Let me make my issue clear.
Please help me write SQl that will give me the following output:ANO NOW HERE IS THE SQL ... So that you will have something to work on your end....
If object_id('tempdb..#t') IS NOT NULL DROP TABLE #t
GOCreate table #t( member varchar(10), amt_paid MONEY, amt_adjusted MONEY, dt VARCHAR(8) );
GO
-----------------------------------------------------
INSERT INTO #t( member,amt_paid,amt_adjusted,dt)
VALUES ( '1234', 100.00,0.00, '20180101')
,('1234', 0.00,-100.00, '20180101')
,('1234', 100.00,0.00, '20180101')
,('1234', 0.00,-100.00, '20180101')
,('1234', 100.00,0.00, '20180101')
,('1234', 100.00,0.00, '20180101')
,('1234', 100.00,0.00, '20180101')
,('4567', 100.00,0.00, '20180101')
,('4567', 0.00,-100.00, '20180101')
,('4567', 100.00,0.00, '20180101')
,('4567', 0.00,-100.00, '20180101')
,('4567', 100.00,0.00, '20180101')
,('4567', 100.00,0.00, '20180101')
,('4567', 100.00,0.00, '20180101');select * FROM #t;
- mw_sql_developer - Monday, June 11, 2018 9:46 AM
Thanks for the explanation... the 3 steps make it much easier.
-
Maybe this?
SELECT member,
amt_paid,
amt_adjusted,
dt,
dupeNum
FROM
( SELECT member,
amt_paid,
amt_adjusted,
dt,
ROW_NUMBER() OVER (PARTITION BY member, dt, amt_adjusted ORDER BY member, dt) AS dupeNum
FROM t) x
WHERE dupeNum <= 2; -
My problem, you were also asked to show what you have tried to solve your problem. At this time, all I see is you asking others to do for free what you are getting paid to do.
We are volunteers, not paid workers. We are here to help you so that you can get better at writing the SQL you need to accomplish you work and perhaps need less help. That could lead you to begin helping others here as well. That is how many of us got started here, looking for help, getting the mentoring to get better, then giving back to the community that help us get better. - Lynn Pettis - Monday, June 11, 2018 10:31 AM
Lynn: Believe me.. if I were to show you my work, it would only be the same us what was posted by pietlinden ( or similar ). I got stuck and that is why I asked.
The script code that I posted and one more SQl was all that i did.. Thought about it and didn't see myself progressing.. so that is whey i asked....
Viewing 15 posts - 1 through 15 (of 26 total)
You must be logged in to reply to this topic. Login to reply