Trying to reduce RID Lookups
-
Hi All
I'm trying to help a colleague optimise an SQL query that looks for parts of a persons name across two tables and produce one combined result to be shown in a suggestion list eg like when you start to type in a browser address bar etc
The query looks like this.
I'm sure it can be written differently but what I am specifically looking for is a significant reduction in RID Lookups as they take 87% of the execution plan
Perhaps it's the nature of the beast with this type of query and there is not much that can be done ?
Thanks in advance for any advise !
Select Top 15
Row_Number()
Over (
Partition by "Name"
Order by "Name","PCSortReference","DON0001"."Donor_No"
),"Name","DON0001"."Donor_No","Post_code",IsNull(Stuff((Select '|~' +rTrim("Alias") from "DonAlias"
Where "DonAlias"."Donor_No"="DON0001"."Donor_No" for Xml Path ('')),1,2,''),'')
from "DON0001" where '#'+[Name]+'#' like '%[^a-z0-9]william%[^a-z0-9]%'
Or Exists (
Select * from "DonAlias" Where "DonAlias"."Donor_No"="DON0001"."Donor_No" and '#'+[Alias]+'#' like '%[^a-z0-9]william%[^a-z0-9]%'
)
Order by "Name","PCSortReference","DON0001"."Donor_No"
-
Quick thought, change the table from a heap to a clustered index table.
😎 -
Thanks for the prompt reply
Please can you explain the best way to do/try this ? - Eirikur Eiriksson - Wednesday, April 11, 2018 3:50 AM
This blog would seem to suggest it would not improve things ?
https://sqlperformance.com/2016/05/sql-indexes/rid-lookup-faster-key-lookup - andrew 67979 - Wednesday, April 11, 2018 4:37 AM
To change the table, you just have to add a clustered index.
😎What Aaron is talking about on that blog is not relevant, you can bypass the key lookup by using an included column in an index if needed.
-
This bit of code:
like '%[^a-z0-9]william%[^a-z0-9]%'Means that you're always going to be seeing scans of whatever indexes you have. I'm with Eirikur (always), in that a clustered index and a key lookup generally will outperform RID. However, in this case, nothing you do is going to prevent the scans unless you can avoid the wild card searches. It sounds like the solution is cleaner data and better structures if you really want improved performance.
Just eliminating the RID lookup is unlikely to improve performance much at all. However, to do that, simply add all columns being retrieved through the RID lookup operation to the INCLUDE portion of your nonclustered index. Get those columns from the Output property of that RID lookup operator in the execution plan if it's not clear to you from the query.
However, that won't improve performance much. You'll still be doing scans.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Thanks all
I just wanted to make sure I was not missing a face palm !
It's not an option for us but I guess the only other option is to use full text indexes and use contains() in the where clause ?
If we were to do this would you expect a significant improvement ? - andrew 67979 - Wednesday, April 11, 2018 5:20 AM
Hi,
the best way to find out would be to restore to a development instance and test it.
The people assisting you so far have an enormous amount of experience (and ability). What they don't have is your database schema, data and use patterns, so while they can give advice / guidelines they can't guarantee.
As an example, a system where I was investigating significant performance problems a few weeks back had a large very active heap as part of a key, time critical process, which was taking 3 hours plus at peak times. We recommended the supplier added a PK to it, based on our own testing. With no additional changes at that point, this dropped the time at peak to under 3 seconds. Will you get the same kind of improvement? Absolutely impossible to tell without testing I'm afraid. I've done the same on other systems with different structure, data and use patterns and the improvement was nowhere near that good. As the saying goes, it depends.I'm a DBA.
I'm not paid to solve problems. I'm paid to prevent them. - andrew 67979 - Wednesday, April 11, 2018 5:20 AM
Probably not, but it's worth a shot.
I've never found fulltext indexes to be much good and, they're really designed for searching through a book worth of information, not discerning that 'Grant' is in 'Data types are one of Grant's pet peeves." However, if you can't fix the root cause, it might work.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
I guess the type of search we are doing is something akin (on a much much smaller scale) to what google MAPS might do when looking for words in the first line of an address
Thanks for all the feedback I will also try some other performance monitoring to see if there are any significant hardware bottlenecks
-
Are you trying to eliminate URL encoded characters with the regex pattern in the where clause?
😎like '%[^a-z0-9]william%[^a-z0-9]%'
If so, you could alter the FOR XML part to correctly handle the text, something like this (in bold)
Select Top 15
Row_Number()
Over (
Partition by "Name"
Order by "Name","PCSortReference","DON0001"."Donor_No"
)
,"Name"
,"DON0001"."Donor_No"
,"Post_code"
,IsNull
(
Stuff
(
(
Select
'|~' + rTrim("Alias")
from "DonAlias"
Where "DonAlias"."Donor_No"="DON0001"."Donor_No"
for Xml Path (''), TYPE).value('(./text())[1]','NVARCHAR(MAX)'),1,2,'')
,''
)
from "DON0001"
where '#'+[Name]+'#' like '%[^a-z0-9]william%[^a-z0-9]%'
Or Exists
(
Select
*
from "DonAlias"
Where "DonAlias"."Donor_No"="DON0001"."Donor_No" and '#'+[Alias]+'#' like '%[^a-z0-9]william%[^a-z0-9]%'
)
Order by "Name"
,"PCSortReference"
,"DON0001"
."Donor_No"; -
Personally, I have pushed this kind of functionality out to SOLR and the developers can then use that to return values as you type. I wouldn't normally recommend a NOSQL solution, but its free and performs this much faster than SQL ever will, also, all you need to do is make sure you update SOLR often enough with deltas. The only downside is if the values you are looking for are very frequently changed.
- Rick-153145 - Wednesday, April 11, 2018 8:44 AM
I think it is premature to choose a tool when one doesn't have the full picture and not having explored all available options.
😎 -
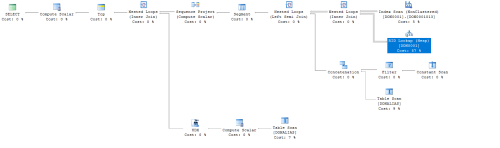
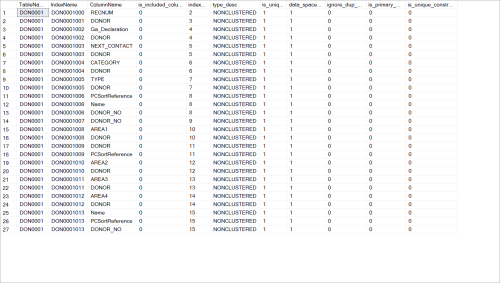
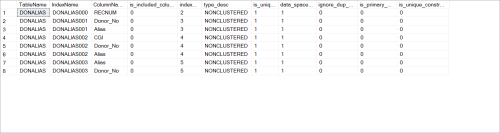
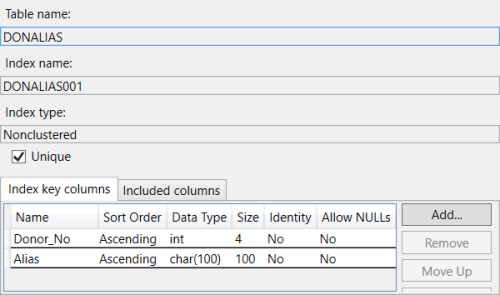
1) Verify that table "DonAlias" is (1A) clustered by Donor_No or (1B) a nonclus index is keyed by Donor_No and contains Alias (as key or not, with or without other columns); if not, create such an index.
2) Change the code to directly check for a direct match rather than the hack of adding #s before and after the column (coded below).
3) You might gain performance by having a trigger set a flag bit to indicate whether non-alphanum char is present, then index and search that flag. [Btw, did you mean to exclude a space from the chars to not match?]
IF certain specific name(s) are searched for (very) often, you might gain performance by having a trigger set a flag bit to indicate that, then index and search that flag.
Just possibilities that would need further fleshing out, but could massively speed up the searches.
Select Top 15
Row_Number()
Over (
Partition by "Name"
Order by "Name","PCSortReference","DON0001"."Donor_No"
),"Name","DON0001"."Donor_No","Post_code",IsNull(Stuff((Select '|~' +rTrim("Alias") from "DonAlias"
Where "DonAlias"."Donor_No"="DON0001"."Donor_No" for Xml Path ('')),1,2,''),'')
from "DON0001"where [Name] like 'william%' or [Name] like '%[^a-z0-9]william%[^a-z0-9]%'
Or Exists (
Select * from "DonAlias"
Where "DonAlias"."Donor_No"="DON0001"."Donor_No" and
([Alias] like 'william%' or [Alias] like '%[^a-z0-9]william%[^a-z0-9]%')
)
Order by "Name","PCSortReference","DON0001"."Donor_No"SQL DBA,SQL Server MVP(07, 08, 09) A socialist is someone who will give you the shirt off *someone else's* back.
-
Ref point 1B is this what you mean ?
Viewing 15 posts - 1 through 15 (of 15 total)
You must be logged in to reply to this topic. Login to reply