Skip rows when import a Flat File
-
Hi,
I need to import two Flat Files, but I need to skip the 2nd and 3rd row from one of them (Headers in 1st row) and the other I need to skip the last two rows.- sample of Flat File 2nd and 3rd row:
Row 1 - Header
Row 2 -12/01/2017 00:00 12/31/2017 0:00
Row 3 - No of Complete Downloads No of Partial Downloads Asset Name Series Info Genre Desc Sub Genre Desc Provider Brand Provider Id
- sample of Flat File last two rows:
Row *** - Period From Period To
Row *** - 01/10/2017 00:00 31/10/2017 00:00Any help is very much appreciated
Thanks in advance,All help and Any help
is appreciated - Vitor da Fonseca - Wednesday, January 3, 2018 5:58 AM
Before answering, we need a special piece of information. How are you importing the files?
- Luis Cazares - Wednesday, January 3, 2018 7:02 AM
Hi,
I intend to import the data with an SSIS package, which would load the source file from a defined location.
Please bear with me as I am quite new to SQL, still loads to learn.
Thanks in advance,All help and Any help
is appreciated - Vitor da Fonseca - Wednesday, January 3, 2018 8:25 AM
Sure, no problem.
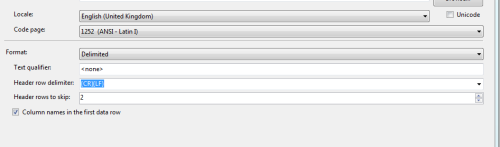
For SSIS, in the Flat File Connection Manager, you have an option that mentions Header rows to skip. On that option, you need to set it to 2 and check the Column names in the first row checkbox.
That should handle the file if the row delimiters are consistent. - Luis Cazares - Wednesday, January 3, 2018 8:37 AMLuis Cazares - Wednesday, January 3, 2018 8:37 AMLuis Cazares - Wednesday, January 3, 2018 8:37 AMLuis Cazares - Wednesday, January 3, 2018 8:37 AM
Hi,

I've done that but for some reason it starts at row 3, where it should start at row 1 and ignore row 2 and 3??All help and Any help
is appreciated -
The standard flat file source can skip n rows and deal with a header row. It can't skip rows 2, 3, n-1, and n. There is one possible solution by re configuring the flat file souce, otherwise you may have to write actual code that can open a file, read it, and parse it.
If rows 2, 3, and the last two rows throw errors because they can't be parsed into the correct number of columns, add an error output to the flat file source that redirects these rows somewhere else. You have to set the error action to Redirect instead of Fail. The other rows should be read normally.
You could use a script source task that has special handling for the four extra rows (ignore them or do something else with them if the data is useful). It has to open the file, read and parse each row, and load buffer rows with the data field values. The rest of the dataflow can use normal components.
You could script a task that modifies the input files by deleting rows 2, 3, and the last two rows (or makes a copy of the input file excluding these four rows). Then use a dataflow with the regular flat file source to read it.
-
This was removed by the editor as SPAM
Viewing 7 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply