XQuery error
-
I am trying the following:
declare @packXML XML = '<Pack>
<PackID>1</PackID>
<Item>
<ItemNumber>1</ItemNumber>
<Qty>1</Qty>
</Item>
</Pack>
<Pack>
<PackID>2</PackID>
<Item>
<ItemNumber>1</ItemNumber>
<Qty>5</Qty>
</Item>
<Item>
<ItemNumber>2</ItemNumber>
<Qty>10</Qty>
</Item>
</Pack>
'create table #PackItems (PackID int, ItemNumber int, Qty int)
insert into #PackItems(PackID, ItemNumber, Qty)
select N.value('PackID[1]','int'), N.value('(Item/ItemNumber[1])','int'), N.value('(Item/Qty)[1]','int')
from @packXML.nodes('Pack') as T(N)select * from #PackItems
drop table #PackItems
This gives me this error:
Msg 2389, Level 16, State 1, Line 24
XQuery [value()]: 'value()' requires a singleton (or empty sequence), found operand of type 'xdt:untypedAtomic *'What am I doing wrong?
-
Your first Xpath Expression for Item/ItemNumber is wrong
Instead of
N.value('(Item/ItemNumber[1])','int')
You wantN.value('(Item/ItemNumber)[1]','int')
declare @packXML XML = '<Pack>
<PackID>1</PackID>
<Item>
<ItemNumber>1</ItemNumber>
<Qty>1</Qty>
</Item>
</Pack>
<Pack>
<PackID>2</PackID>
<Item>
<ItemNumber>1</ItemNumber>
<Qty>5</Qty>
</Item>
<Item>
<ItemNumber>2</ItemNumber>
<Qty>10</Qty>
</Item>
</Pack>
'
select N.value('PackID[1]','int'), N.value('(Item/ItemNumber)[1]','int'), N.value('(Item/Qty)[1]','int')
from @packXML.nodes('Pack') as T(N)"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
- Alan.B - Monday, April 24, 2017 3:24 PM
Thanks Alan, that resolves the error, but now I realize that it doesn't give me the results I'm looking for.
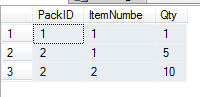
I really need a row for each Item node, so my expected results should be:

- Lisa Cherney - Monday, April 24, 2017 3:37 PM
This should do the trick:
SELECT
N.value('(../PackID/text())[1]', 'int'),
N.value('(ItemNumber/text())[1]','int'),
N.value('(Qty/text())[1]','int')
FROM @packXML.nodes('Pack/Item') as T(N);"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
Using the parent axis when extracting values from XML is not good for performance.
Use an extra cross apply instead.select P.X.value('(PackID/text())[1]','int') as PackID,
I.X.value('(ItemNumber/text())[1]','int') as ItemNumber,
I.X.value('(Qty/text())[1]','int') as Qty
from @packXML.nodes('/Pack') as P(X)
cross apply P.X.nodes('Item') as I(X);For more info on the problem with the parent axis you can have a look at this question on StackOverflow:
Cross apply xml query performs exponentially worse as xml document grows
. -
Thanks Alan and Mikael for helping solve my issue, and for the info on performance issues.
- Mikael Eriksson SE - Monday, April 24, 2017 11:34 PM
Well done Mikael. I would have thought that the extra APPLY would increase the overhead but you are 100% right - the parent axis is a killer. I looked at the link you posted which includes some good info but also did a quick performance test and was blown away at the difference.
IF OBJECT_ID('tempdb..#tmp') IS NOT NULL DROP TABLE #tmp;
CREATE TABLE #tmp (packkey int identity primary key, packXML XML NOT NULL);INSERT #tmp(packXML)
SELECT TOP (100000)
'<Pack>
<PackID>'+ CAST(abs(checksum(newid())%10) AS varchar(2)) +'</PackID>
<Item>
<ItemNumber>1</ItemNumber>
<Qty>'+ CAST(abs(checksum(newid())%20)+1 AS varchar(2)) +'</Qty>
</Item>
</Pack>
<Pack>
<PackID>2</PackID>
<Item>
<ItemNumber>1</ItemNumber>
<Qty>'+ CAST(abs(checksum(newid())%20)+1 AS varchar(2)) +'</Qty>
</Item>
<Item>
<ItemNumber>2</ItemNumber>
<Qty>'+ CAST(abs(checksum(newid())%90)+1 AS varchar(2)) +'</Qty>
</Item>
</Pack>'
FROM sys.all_columns a, sys.all_columns b;SET NOCOUNT ON;
IF OBJECT_ID('tempdb..#dump1') IS NOT NULL DROP TABLE #dump1;
IF OBJECT_ID('tempdb..#dump2') IS NOT NULL DROP TABLE #dump2;
GOSET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT
packkey,
N.value('(../PackID/text())[1]', 'int') as PackID,
N.value('(ItemNumber/text())[1]','int') as ItemNumber,
N.value('(Qty/text())[1]','int') as Qty
INTO #dump1
FROM #tmp
CROSS APPLY packXML.nodes('Pack/Item') as T(N);SELECT
packkey,
P.X.value('(PackID/text())[1]','int') as PackID,
I.X.value('(ItemNumber/text())[1]','int') as ItemNumber,
I.X.value('(Qty/text())[1]','int') as Qty
INTO #dump2
FROM #tmp
CROSS APPLY packXML.nodes('/Pack') as P(X)
CROSS APPLY P.X.nodes('Item') as I(X);
SET STATISTICS TIME OFF;
SET STATISTICS IO OFF;
GODROP TABLE #dump1;
DROP TABLE #dump2;
DROP TABLE #tmp;Results
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table '#tmp_0000000002B3'. Scan count 3, logical reads 2278, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.SQL Server Execution Times:
CPU time = 25422 ms, elapsed time = 13259 ms.
Table '#tmp_0000000002B3'. Scan count 3, logical reads 2278, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.SQL Server Execution Times:
CPU time = 6313 ms, elapsed time = 3205 ms.
I learned something new today before 9AM."I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
- Alan.B - Tuesday, April 25, 2017 8:07 AM
Wow Alan. Thanks for the effort to show the performance differences.
I'll definitely go with Mikael's solution.
Viewing 8 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply