
If you’re looking for SQL Server news, just skip this post. I’m going to talk about general business & capacity planning type stuff here today.
Our SQL ConstantCare® customers install an app that polls diagnostic data from their SQL Servers and Azure SQL Databases, upload it to us daily, and then automatically get advice on what they should do next.
 We use Amazon Aurora PostgreSQL as the back end, and I wrote about that design decision last year. I followed up later with a discussion of our hosting costs. Throughout 2018 and most of 2019, the production servers were:
We use Amazon Aurora PostgreSQL as the back end, and I wrote about that design decision last year. I followed up later with a discussion of our hosting costs. Throughout 2018 and most of 2019, the production servers were:
- Two r4.xlarges in a cluster (for high availability)
- 2 physical cores, 4 with hyperthreading on
- 30GB RAM
That served us really well, except for the times when Richie needed to vacuum out deleted rows. PostgreSQL keeps deleted rows inside the user database (just like SQL Server 2019’s new Accelerated Database Recovery), and the automatic vacuuming processes can’t always keep up, especially with app designs like ours. We only keep a rolling 30 days of data, and we roll through billions of rows per month in some of the tables, so there’s a lot of deleting going on.
When Richie needs to do big vacuums manually, he spins up the biggest RDS instance available: the r5.24xlarge with 96 cores, 768GB RAM, and 14,000 Mbps storage throughput. (One of the slick advantages of Aurora’s architecture is that since the compute and storage are completely separate, you can amp up to insane performance quickly without waiting for storage to catch up.) At only $14 per hour, that’s worth it to make maintenance tasks fly temporarily.
However, our workloads are growing.
We’ve been adding new features that gather more data and run more queries against it, like our index recommendations and multi-server emails. I found it incredibly hilarious that our most resource-intensive Postgres query by far was the query that analyzed your indexes and told you what to add. And you know what that query needed? Indexes. Of course.
By October, our reserved instances had expired. With Amazon, you can reserve your database server capacity for 1-3 years, even prepay in advance if you want, and get deeper discounts. In the hosting cost discussion post, I talked about how I’d decided to reserve a pair of db.r4.xlarge instances for production for 1 year – but that reservation was up. I didn’t want to make a decision back then, though, because…
We’ve been adding users and servers: the population had been fairly stable through 2018/2019 because I didn’t promote SQL ConstantCare® too hard, and like any SaaS product, we had a churn of subscribers. New people would sign up, and older users would let their subscription lapse once they’d taken care of the basic issues on their servers. However, with the annual Black Friday sale, I knew a big population jump would come – I just didn’t know if it would be big or fast.
So we decided to wait out through November to see how the sales & installations went. Now, in early December, we’re approaching 500 users sending in data on almost 4,000 servers. I expect those numbers to grow over the coming year as more Black Friday sale buyers start to leverage their newly purchased goodies. Over 1,000 folks have active subscriptions that include SQL ConstantCare as a benefit, and we’ve seen that folks tend to monitor just a server or two at first, then gradually add more of their servers over time as they see the value in the service. I wouldn’t be surprised if we were analyzing over 10,000 servers by this time next year.
So what should we use next?
Richie and I talked through our options:
Switch to Azure SQL DB or Azure PostgreSQL: I’m only mentioning this because I know you’re gonna suggest it in the comments, but no, this didn’t make any financial sense. Changing back ends or cloud providers would have been an expense with no appreciable benefit to end users.
Switch to Aurora Serverless: it’s still PostgreSQL-compatible, so no code changes required, but the Serverless version can automatically scale up and down very quickly. This would be really cool for a business like ours where the database server is idle for hours at a time, then gets hammered when lots of users send in data on a timer:

That graph is from our new upsized primary – it used to be banging up against 100% for hours at a time during peak loads – but you get the idea. Serverless seems like a good idea here, but the Aurora Serverless limitations had just enough gotchas that we couldn’t quite migrate production to it yet. (Once a couple of those limitations are gone, though, we might be able to cost-effectively deploy SQL ConstantCare® in the EU. Fingers crossed.)
Stay with on-demand (not reserved) instances: this didn’t make sense because the savings are so large on reserved instances. You can easily save 35%-45% if you’re willing to lock in rates for a while:
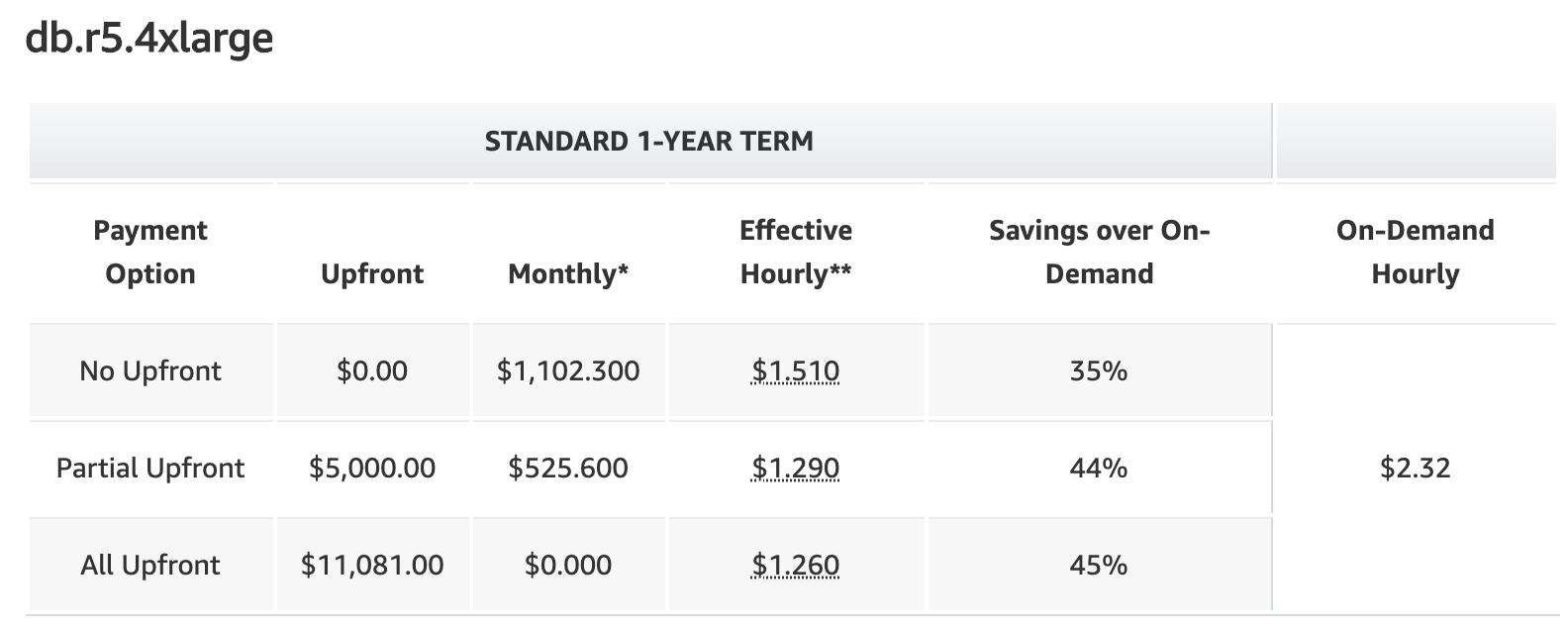
Buy reservations for larger instances: instead of the r4.xlarge (4 cores, 30GB RAM), we could commit to larger instance sizes:
- r5.xlarge: 4 cores, 32GB RAM = $5,540/year for 2 reserved instances (current state)
- r5.2xlarge: 8 cores, 64GB RAM = $11,082/year
- r5.4xlarge: 16 cores, 128GB RAM = $22,162/year
- r5.12xlarge: 48 cores, 384GB RAM = $66,486/year
Since there’s nothing in between the 4xlarge and 12xlarge, that made my decision process pretty easy: we went for a pair of 4xlarge reservations for the next year. It lets Richie focus on building features rather than troubleshooting Postgres performance problems that neither of us are particularly good at, and it also let me add more queries into my Power BI dashboard that I use for analyzing client data quickly. That even drove improvements to the way I do my consulting process, and I’ll be updating that product early next year.
The database is still by far, far and away the most expensive thing in our entire infrastructure. It’s not even close: serverless apps are just so, so affordable to host compared to fixed assets like database servers. I love seeing the same problem that my clients see: the decision about when it makes more sense to hire a performance tuner versus just throw hardware at it. SQL ConstantCare®’s asynchronous queue-based serverless architecture definitely helps keep database costs low, but there’s going to come a time in the next couple/few years when we’ll have to bring in a serious Postgres performance tuner to help push our bill back down. (And no, I’m not gonna be the person who does it!)

17 Comments. Leave new
Don’t know if you came across it, but this is a PostgreSQL compatible distributed db, on azure or self hosted.
Came across some years ago, but never got the chance on using it sadly.
But Microsoft bought them, so I guess they have some potential 😉
https://www.citusdata.com/product/hyperscale-citus/
We didn’t want to run our own servers though.
On the list of prices near the end, I don’t see anything about hard disk space. So, that 48Core monster costs > $66K per year… what does that include for Hard Disk space, backup space, I/O cost, etc, and at what speed is the I/O or is that extra if you want speeds faster than my old USB 2.0 thumbdrive?
Great question! Space is separate from compute – our space is relatively small (around 2TB if I remember right). Backup space is effectively free because we keep such a short time span of backups. IO throughput is dictated by the size of compute you buy, and it’s a whopping 14,000 Mbps on the 48-core monster.
Thanks for the info, Brent. Always much appreciated.
Happy New Year!
Provisioned IOPS are an extra, but pale in comparison to the licensing costs. And yet relying upon IOPS alone to determine disk performance is like buying a one-legged stool and expecting a semblance of stability :). The R5Ds we have run Intel Xeon Platinum 8175M CPUs. Set AWS’s sales-drivel about “CPU optimized” side, and consider Z1Ds – the ones we have run Intel Xeon Platinum 8151CPUs.
What AWS lacks (but I hear is about to offer, or has just been offered) is more customization options, such as allowing customers to ask for a system with more RAM per CPU than the constrained (cookie-cut) AWS Z1D and R5D instance types. I cannot remember what AWS calls their new offering, in part because I am disappointed with what AWS has been offering, and in part because actively I try to forget sales-drivel ;).
It’s not clear from the article, but have you looked at the VACUUM settings for Postgres? (I’m no expert on Postgres, I’m just somebody that gets a strange kick out of reading very technical database-related posts!)
The VACUUM defaults are very often not aggressive enough when you get into the millions (it doesn’t run soon enough or do enough on each pass to keep up).
https://www.percona.com/blog/2018/08/10/tuning-autovacuum-in-postgresql-and-autovacuum-internals/
https://medium.com/coding-blocks/optimizing-storage-and-managing-cleanup-in-postgresql-c2fe56d4cf5
If they are still the defaults, then the big tables might need autovacuum_vacuum_scale_factor to be set to something a *lot* lower than 0.2 (20% of the table has to change before even considering a VACUUM).
I’m sure a bit of tweaking by someone with knowledge would give you more wiggle room. The Postgres mailing lists are pretty friendly as well.
Yeah, I leave that to Richie.
We have adjusted the autovacuum settings and it has been running a whole lot better as of late. I still bring the system down for a few hours every two weeks or so to perform db and data related cleanup. Vacuuming the tables is just one of the tasks I perform while the system is down.
it just means that autovacuum is not handled properly; when you set it up properly it will naver happen
Tell me you’ve never worked on a multi terabyte OLTP system without telling me you’ve never worked on a multi terabyte OLTP system
I am having my fingers crossed for EU rollout
Yes, can’t wait for it to happen.
I think I would have been tempted by the R5n instances, which do come with an 8xlarge if that was really the size you wanted, and have improved networking.
Alternatively there’s the r5d with the fancy NVMe SSD (for the postgres equivalent of tempdb?) which also comes in an 8xLarge.
I haven’t checked the prices of any of these!
Toby – they’re not available for Aurora Postgres.
Brent: For future AWS projects, I recommend you investigate Amazon’s new feature, Savings Plans, as an alternative to reserved instances. The savings are identical to the existing reserved instance system, but the maintanence is much simpler and the flexibility is a bit better.There are really only a few disadvantages:
1) If you’re only managing 1-2 VMs and are confident those machines will never need to be upgraded or downgrades, it’s slightly simpler (though less flexible) to buy an identical reserved instance.
2) Unlike reserved instances, savings plans cannot be sold to other AWS customers.
Note: Savings plans do not reserve capacity, but a non-billing capacity reservation can be done separately (simultaneously with a regional reserved instance or a savings plan), and does not introduce a commitment. So, I consider this to be an advantage, rather than a disadvantage.
I appreciate the note, but those are for EC2, not RDS. We’re talking about RDS Aurora here.