

Introduction
So what’s all the fuss about Fill Factor? It is a SQL Server parameter I’ve ignored for 20+ years. The main reason was/is I’ve had no idea about what value to use. There is just no documented definitive guidance.
Back in April at SQL Saturday #830 - Colorado Springs, I attended two sessions by Jeff Moden, titled “Black Arts” Index Maintenance: How the “Best Practice” Methods are Silently Killing Performance. These sessions were outstanding and are downloadable from the SQL Saturday web site (https://www.sqlsaturday.com/830/Sessions/Schedule.aspx). A Reader’s Digest version of his presentations is as follows: contrary to the popular concept to reorganize at 10% fragmentation and rebuild indexes at 30%. He showed (in the 2 presentations) that page splits caused tremendous performance degradation, and you should probably rebuild indexes at 1% fragmentation. I don’t want to steal his “thunder” (and it is forthcoming in another series by him).
But on the flight back home, I got to thinking about everything he said and how fill factor also “factors” into index performance and maintenance. It got me to thinking about a brute force optimization technique I implemented way back when I worked at the Air Force Rocket Propulsion Laboratory. Yes, I was once a rocket scientist and still a geek! It was a technique that involved tweaking various parameters (plus and minus percentages) and reducing the tweaks to an “optimum” solution. This optimization technique was not always perfect as in a multi-dimensional scenario there are valleys that this solution could drill down on, but would offer “near” optimum solutions that let us explore options.
Frankly speaking, what happened is somewhat amazing. Using the “still experimental” methods that I explain in this article on a client’s system, the end result is that the overall database wait times showed improvement (decreases) of about 30%. That’s not a trivial improvement. I hope this article will serve as an impetus for others to try these and other experiments on their indexes to come up with other improvements they might wish to share with the community at large.
Part 1 of this series will include an Overview and Code Details (including the actual TSQL script). Part 2 will cover an analysis of the code and its results over a 3 month period as well as performance details and sections on performance, current limitations, and anticipated future improvements.
Overview
What was needed was to collect index parametrics and look for patterns. This involved using the sys.dm_db_index_physical_stats and sys.dm_db_index_operational_stats views and capturing these index parametrics before and after each index rebuild. Prior to this task, my choice for index fragmentation was a modified version of Ola Hallengren’s defrag script that is configured to only start rebuilds at 10% and no reorganizes. For this project, this script was modified to capture and store (in a table) the before and after parametrics for each index rebuild within a specified database.
Initially I started looking at the top 15 average fragmentation indexes greater than 1.0%, but eventually changed it to 1.2% because of logical fragmentation issues. In the meantime, if a fill factor has not established, the previous fill factor (for that index) is decremented and the resulting average fragmentation compared to the previous average fragmentation. All indexes prior to this task had 100% fill factors.
This process is repeated every 24 hours in a SQL Agent job until the index’s new average fragmentation is greater than the previous one. The previous fill factor is notated and fixed for that specific index. A secondary look at the data over 90 days (since the fill factor was established), inserts an index for a once again review (data collection). While this may temporarily degrade that index’s performance it ensures that a once again “near optimum” fill factor can be established taking into account any new data skew and application utilization of the database.
Details
This process (index rebuild and fill factor perturbation) was incorporated into a SQL Agent job that runs daily during a period of low server activity. It stores data from the SQL Agent job and inspects that data for possible fill factor adjustments. The following discussion describes the attached script in detail. I recommend turning on Line Numbering in SSMS and having the script listed in a second window for following this discussion.
Line 4 is the specification of the database name. Currently the script is setup for only one database, however, coding within the working tables will allow the script to eventually be expanded to multiple databases within a server. If this line remains uncommented the script will use the current database.
![]()
Line 60 gets the name of the current database.
![]()
The commented code in lines 65-68 should be uncommented when used in an Always On environment.
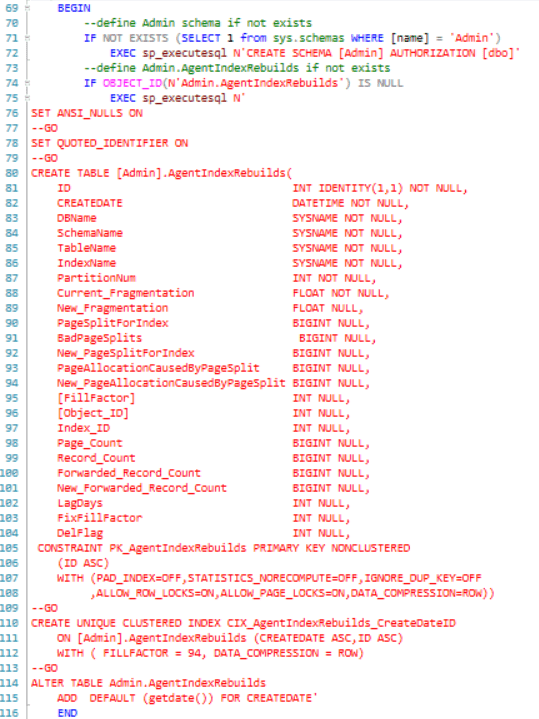
Lines 70-116 define the Admin schema and also the Admin.AgentIndexRebuilds table. This table has evolved during the study to this final version. Not all parameters are used to determine each index’s fill factor, but I thought (and still do) that too much data collection allows sufficient analysis rather than not enough. Note that the database name is retained so that this code can be extended to multiple DBs on the same server. Variables prefaced with “New” are the results after the particular index rebuild has completed (with or without a new fill factor). There will be more discussion on this table later in the Analysis section (Part 2).
Lines 120-125 are the primary configuration parameters for this script. @RedoPeriod is the number of days to wait until an identified index is re-evaluated (more on this in the code discussion below). @TopWorkCount is a specified number for the TOP command to return the specified number of most fragmented rows. Initially I started with a value of 15, but within 3 weeks most of the time the result set returned less than 15 rows (this was primarily due to the improved fill factor and decreased split pages). @Database is the current database name.

The commented code in lines 133-136 should be uncommented when used in an Always On environment.
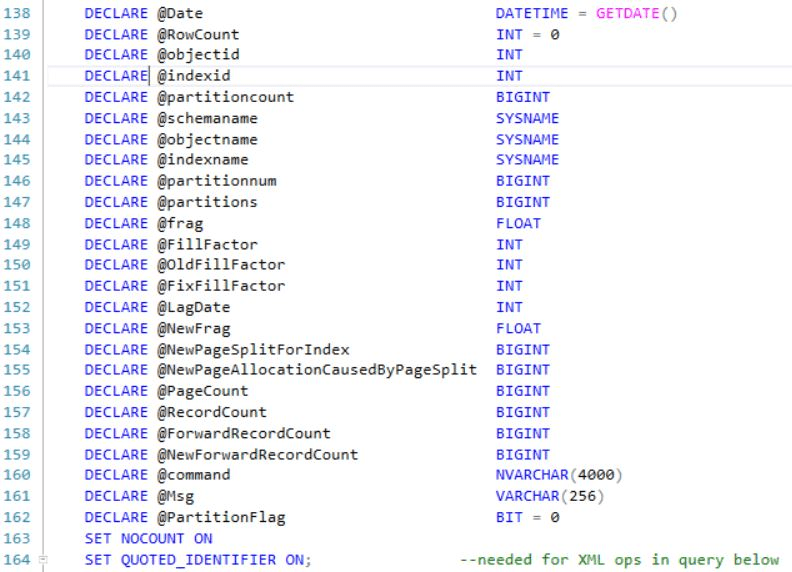
Lines 138-162 are variable declarations used in the subsequent code.
Lines 171-237 is the code used to select the TOP worse fragmented and split page indexes at the current time. The query calls sys.dm_db_index_physical_stats to get the current fragmentation and sys.dm_db_index_operational_stats to get page splits as well as sys.indexes and sys.objects to get table and index data. This data is put into a working table (#work_to_do) for subsequent utilization. This query is dual-functional; it always does an index rebuild (for the specified index) as a de facto defrag, but also a fill factor perturbation if not already fixed. If you examine the ORDER BY clause it is also dual-functional – even days the TOP n rows are returned by maximum average fragmentation descending and on odd days the TOP n rows are returned by maximum page-splits per index descending.
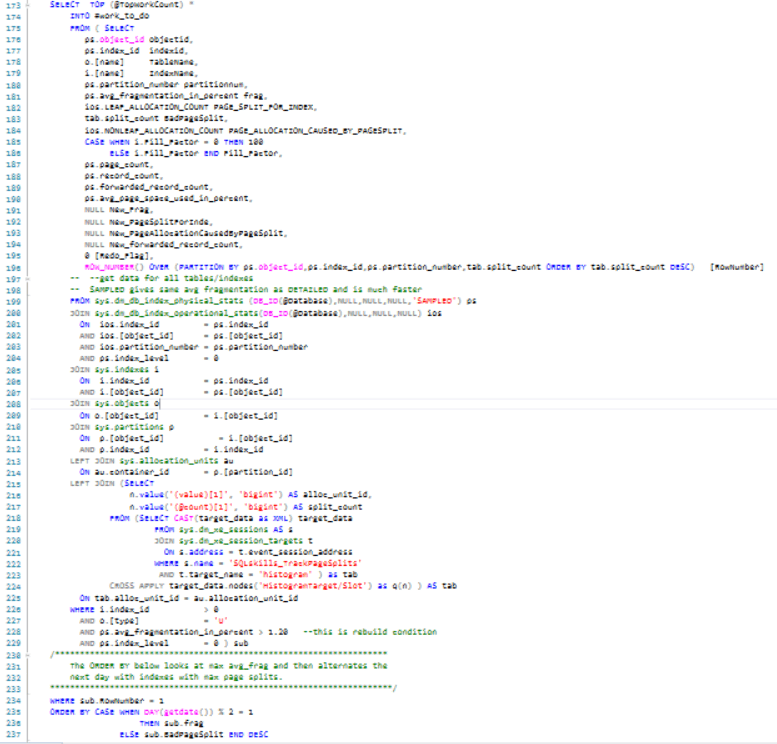
Lines 239-271 review the existing data to see if there is a candidate index for re-evaluation of its fill factor (where the fill factor is already set).

If there is, a row is added to #work_to_do for that index and the @Redo_Flag is set to one. As configured, the @RedoPeriod is 90 days – this looks at any existing index in the Admin.AgentIndexRebuilds table to see if last adjustment > @RedoPeriod .

Lines 328-359 define the cursor used to rebuild each table/index in #work_to_do.

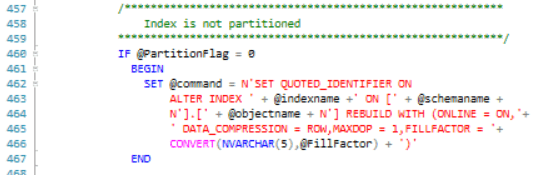
Lines 369-380 set up a flag to specify if an index is partitioned or not. Since you cannot change fill factor for a single partition within a partitioned index, the flag signals the code to only rebuild that particular index partition without a perturbation of the fill factor.
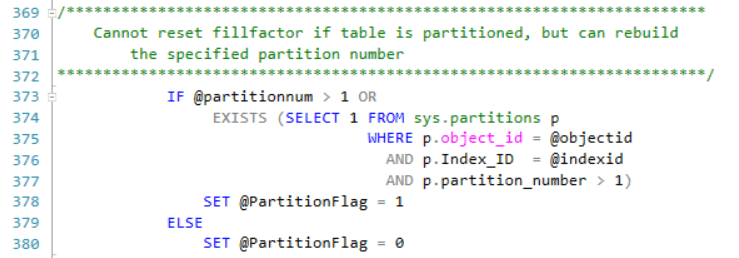
Lines 382-393 test to see if the fill factor is already fixed or not.
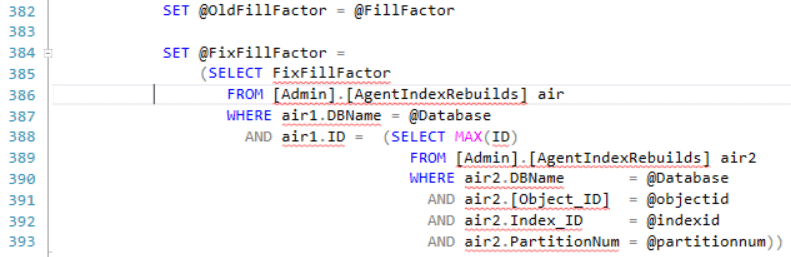
Lines 396-455 contain the logic for perturbing the fill factor. The code is very readable. Clustered Indexes are perturbed by decrementing the current fill factor by 1 and Nonclustered indexes fill factors are decremented by one or two, depending on the length of time since the index was last rebuilt. Code is there to ensure the perturbed fill factor is never less than 70%. This is an arbitrary number I set and can be changed if required.
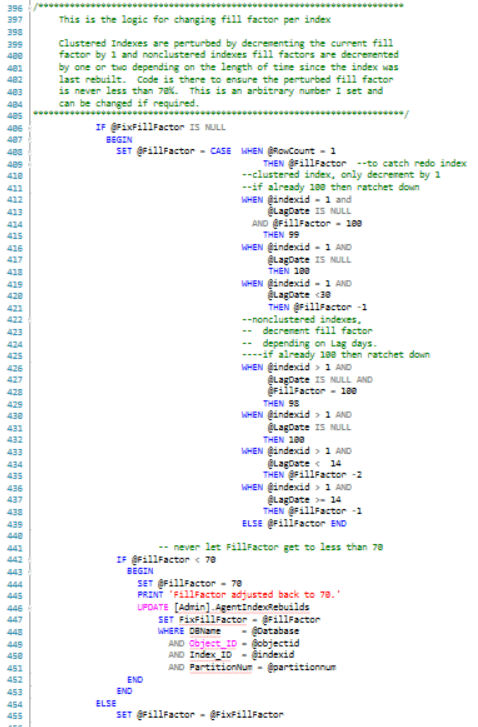
Lines 436-443 setup the dynamic SQL to rebuild the index with the specified fill factor if the table is not partitioned.
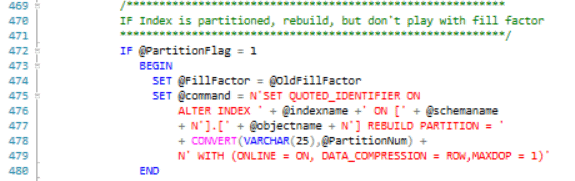
Lines 469-480 set up the dynamic SQL to rebuild the specified index for partitioned indexes. The Fill Factor is not changed for partitioned indexes.
Lines 482-483 executes the generated dynamic SQL.
![]()
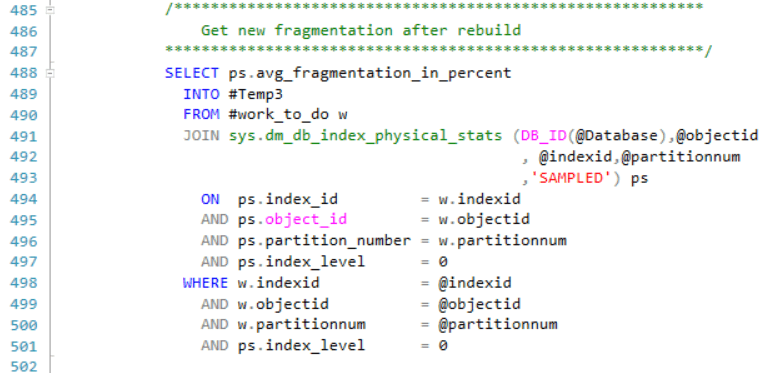
Lines 485-501 gets the new index fragmentation.
Lines 503-544 contain the logic to determine if the current fill factor causes more fragmentation. If so, the fill factor is backed up (decremented by 1), specified as fixed, and rebuild with the fixed fill factor.

Lines 546-581 inserted the old and new index parametrics into the [Admin].AgentIndexRebuilds table for subsequent review by the next script run.

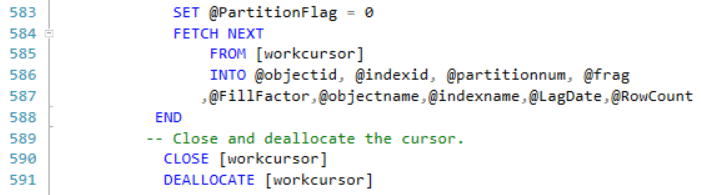
Lines 583-588 take care of some administrative book-keeping and fetch the data for the next cursor loop.
Lines 594-606 are just clean-up code.
Requirements
This code was developed and tested with SQL Server 2017 Enterprise Version. However, it is applicable to all versions of SQL Server from 2012 and upward.
It can also be used for Standard Editions (same versions) except the WITH Statement in the Index Rebuilds needs to have the “ONLINE = ON, Data_Compression = ROW,” statement removed (3 occurrences). Data_Compression = ROW option can (and should be) retained in SS 2016, SP 2 and upward for Standard Edition. In the event you are using Standard Edition consider scheduling this task when there is minimal database activity as without the ONLINE option you may have schema locking during the index rebuilds.
Otherwise, there are no other restrictions that I am aware of.
Summary
This whole project started as a proof of concept and as most POCs has made its way into production. While I agree that it’s not complete and isn’t perfect, it did result in a substantial decrease in wait time on a real system. It also demonstrates that effective automatic determination of Fill Factor IS possible.
I look forward to constructive critique and suggestions for improvements from the SQL Server Community.
Cheers,
Mike