
When you build a VM for SQL Server in Amazon EC2, Azure VMs, or Google Compute Engine, it’s all too easy to overlook the CPU speeds that you’re getting. Most of the time, it doesn’t really matter because SQL Server isn’t usually CPU-bottlenecked: your queries are doing table scans with 16GB RAM, starving for IO throughput.
But if you’re seeing high CPU usage, or you’re seeing SOS_SCHEDULER_YIELD waits on your queries, stop to check the VM type you used when building this VM. Once you’ve found it, the easiest ways to look up your CPU speed are:
- AWS EC2: ec2instances.info
- Azure VMs: azureinstances.info is great, but doesn’t show CPU speed. You have to click through the documentation for each VM type.
- Google Compute Engine: the docs, because you specify the minimum CPU platform when you build a VM
In AWS, for example, I run across a lot of customers in the 2xlarge tier: 8 cores and 61GB RAM. Most of the CPUs in that price range are tragically slow:
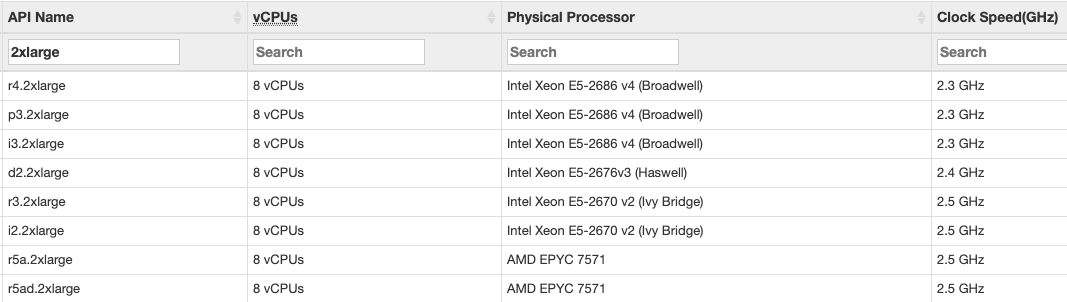
That means if you’ve got queries that suffer from a CPU bottleneck, and they’re not able to go parallel (like because they call scalar functions), you’re not going to have a great time with these instance types.
To pick a better instance type, do a little more digging. EC2instances.info shows some clock speeds as “unknown” when the processors are custom silicon built for Amazon:

To learn more about those models, hit the AWS documentation pages:
- r5.2xlarge: custom Xeon with “sustained all core Turbo CPU clock speed of up to 3.1 GHz”
- z1d.2xlarge: custom Xeon with “sustained all core frequency of up to 4.0 GHz”
The prices aren’t much higher than the instance types you’re already running, either. In fact, it’s been just the opposite for me on two clients in a row! Both had built their SQL Server VMs a couple years ago, and newer instance types not only gave them faster CPU speeds, but reduced costs as well. On a mature application, once it’s been up for a year or two with a stable user base, it’s easy to measure the SQL Server’s performance needs to figure out if it’s constrained by CPU, memory, storage, locks, or something else. Then, you’re better equipped to build the right VM type to save yourself money while making queries go faster.
And before you say, “But I wanna tune the code and indexes!” – you can totally do that too. Why not both? (Especially if changing the VM type saves you money.)
This is also a good reason to touch base with management to see if you’re using reserved instances, and if so, when those reservations expire. If you’ve had a reservation for more than a year, it’s probably time to revisit the latest instance types for a free speed boost.

15 Comments. Leave new
Nice post. Thanks Brent!
Very handy Brent!
One small typo – a1.2xlarge tier is 16 GB RAM, not 61GB RAM.
Stephen – hmm, sorry – where am I showing a1.2xlarge on this post? I can’t find what you’re referring to.
“In AWS, for example, I run across a lot of customers in the 2xlarge tier: 8 cores and 61GB RAM.” Is what I think he’s referring to.
Ah, gotcha – no, I’m talking about the ones in those screenshots. They’re 61-64GB RAM.
Ah yes – my apologies. I see what you mean now. Correction retracted.
The 2xlarge tier has RAM ranging from 15 GigliBits (C3) through 244 GigliBits (x1e) – with quite a few having 61 GigliBits…
I just went through migrating our production machines from m5 and r5 instances to z1d over the last couple months. I’m a big fan of the z1d instance family now.
Where I work, our workloads are very heavy on CPU, in addition to wanting a good chunk of RAM (what database doesn’t, though?). The m5 and r5 instances don’t cut it in the CPU department, and the c5 family is just poor RAM per dollar.
While this blog post is highlighting the CPU, the z1d also has the instance storage NVMe ssd (as does the r5d). Set the database service to automatic delayed start, and toss TempDB on that disk. That local NVMe ssd is great in multiple ways.
First, it’s already included in the price of the EC2 instance.
Secondly, I’ve seen throughput in the neighborhood of 750 MB/s of against it (YMMV). Considering the cost of a io1 volume with a good chunk of provisioned IOPS is NOT cheap, plus you need an instance large enough to support that level of throughput to EBS in the first place, this is a big deal.
Lastly, the throughput against this local drive does not count against your EBS throughput. Meaning, TempDB can be getting hammered while it’s on the local ssd, but you’ll still be able to get the full 250 MB/s of a gp2 volume, or the full 291-ish MB/s to EBS that the z1d.2xl instance itself is capable of.
If you’ve got the gp2-blues, with TempDB performing poorly, or worse, even experiencing buffer latch wait timeouts for our good buddy database ID 2, making a change to a z1d (or r5d, if you don’t need that CPU) to leverage that local ssd is really something to consider.
This is cool stuff, Brent. I enjoy these type of posts!
I’ve been holding out for a Z1d, but there’s a pretty big jump between instance sizes, and they aren’t currently available in our region 🙁
I did some testing of the R5d class before we moved our DB servers to it.
It has an advertised speed of “sustained all-core 3.1 GHz Turbo Boost” (I could swear it was only 3.0GHz when it was first released), but if you push it too hard it’ll drop down to 2.7GHz.
That’s fine for us, because we’re massively over-specced for cores anyway.
“custom Xeon with “sustained all core frequency of up to 4.0 GHz””
What a beast!
Nice topic
[…] dan.j.newhouse: I just went through migrating our production machines from m5 and r5 instances to z1d over the last couple months. I’m a big fan of the z1d instance family now. Where I work, our workloads are very heavy on CPU, in addition to wanting a good chunk of RAM (what database doesn’t, though?). The m5 and r5 instances don’t cut it in the CPU department, and the c5 family is just poor RAM per dollar. While this blog post is highlighting the CPU, the z1d also has the instance storage NVMe ssd (as does the r5d). Set the database service to automatic delayed start, and toss TempDB on that disk. That local NVMe ssd is great in multiple ways. First, it’s already included in the price of the EC2 instance. Secondly, I’ve seen throughput in the neighborhood of 750 MB/s of against it (YMMV). Considering the cost of a io1 volume with a good chunk of provisioned IOPS is NOT cheap, plus you need an instance large enough to support that level of throughput to EBS in the first place, this is a big deal. If you’ve got the gp2-blues, with TempDB performing poorly, or worse, even experiencing buffer latch wait timeouts for our good buddy database ID 2, making a change to a z1d (or r5d, if you don’t need that CPU) to leverage that local ssd is really something to consider. […]
Great timing for this article, I’m doing a proof of concept for recommending the z1d AWS servers and hopefully dropping the number of cores required now that we’re getting our tempdb contention under control. This article will hopefully help me make the case and save us some cash.
One of the first things to check when a query is running sluggishly isn’t actually the database itself, but rather possible issues with the server that it’s running on. If you have access to the server, you might consider using a tool like System Monitor or Perfmon to look at the processes that are running on the server itself. High memory usage, high CPU usage, and slow network traffic are all red flags that the issue may not be the database itself.