In recent years, I worked as a DBA for an organization whose software teams embraced agile methodologies while the business systems were undergoing a prolonged period of major development. For the DBAs, this meant a stream of database change requests, the demand for faster promotion of those changes through our test systems, and everything compressed within shorter release cycles to Production.
The impetus for initiating a project to improve database lifecycle management (DLM) came from the Software side of the house, who urged us to revisit our deployment framework in order to achieve continuous database integration. The ultimate goal was that when any database change was committed to source control, an automated process would trigger tests and deployment to a CI system. The key word for the DBAs was “any” database change: some types of changes were part of our CI automation, and some were not. If my immediate enthusiasm wasn’t boundless, it was because my prior reading around the topic left me wondering how the principles could apply to an enterprise database architecture.
My sticking point with the early literature was the use of the term “the database”: as in how to include “the database” in Continuous Integration. The principles worked neatly when submitting a change to “CREATE TABLE [A]” within a single-database application, yet didn’t seem to map so clearly to more complex systems.
Creating or updating a table, a simple DDL change, could affect the meaning of data in multiple databases across multiple servers through cross-database views, indexed views, synonyms, triggers. The change may affect tables under Replication, under Change Data Capture and Change Tracking; tables horizontally partitioned for archiving; tables vertically partitioned for performance.
Likewise, a DML update could start a chain of data flow across data centers, managed by SQL Agent Jobs, Service Broker queues, SSIS packages; each impacting disk IO, memory, CPU and network; each affected by the addition of table [A] in “the database”.
Nevertheless, we set out to address the challenge posed by agile software development. Bob Walker’s recent articles mentioned the DevOps question: “what do we have to change in our processes to be able to deploy to Production ten times a day?”
I was a little less ambitious when I started to break down the tasks for the DBA team. My question was: “what do we have to change in our processes to be able to commit DDL updates daily?”
A Starting Point
There’s an old Irish joke about a tourist stopping at a crossroads to ask a local farmer how to get to Dublin. “If I were you,” replies the farmer, “I wouldn’t start from here.”
So, where were we starting from? Continuous Database Integration has some general requirements, of which we met about four.
- Everything was in source control, including all database assets: stored procedures, DDL, reference data, SQL Server configuration scripts, SQL Agent jobs, replication scripts, Service Broker scripts – every component deployed to a fresh SQL Server instance. (https://www.simple-talk.com/sql/database-delivery/database-version-control/)
- There was a scripted baseline build that produced a database system for test purposes. (https://www.simple-talk.com/sql/database-delivery/database-build-automation-the-first-step-to-continuous-integration/)
- There was a process of scheduling and orchestration of database builds. We used NAnt/TeamCity/Octopus, but there are plenty of alternatives.
- All changes to database assets were scripted and versioned.
At this point, we began to diverge from the tenets. To take a textbook quote (from Continuous Integration: Improving Software Quality and Reducing Risk): “Database Integration…is based on the principle that database code (DDL, DML, configuration files, etc.) is, in essence, no different from the rest of the source code in a system.” As everything is code and should be treated the same, then all changes should be synchronized with the integration build throughout the day.
A hallmark of our set-up was that the CI systems were as close to Production as feasible within the limits of licensing and other costs. Replication, job scheduling, ETL processes and other features were up and running, and ready to break under change. The principle driving this set-up was to integrate all the consequences of change as early as possible in the development cycle, in line with a shift-left philosophy.
In practice, this encouraged a division of labor between developers and DBAs on the submission of changes. Stored procedures and user-defined functions were committed by developers, and deployed without intervention from DBAs. In contrast, most other database changes were managed by the DBA team. The next section will illustrate why.
Division of Labor
Let’s consider what happens when a change is introduced to create table [A] in database [B]. In this article, I’ll side-step the topic of review and approval. Let’s assume that approval has been given.
I think it’s fair to say that the CI vision is that this simple SQL script should be checked into source control by a development team, which triggers an automated process to send it through a series of test systems until it reaches Production.
To explain why I found it hard to reconcile that vision with most systems I’ve maintained, I’ll diagram the “change” activities like this:
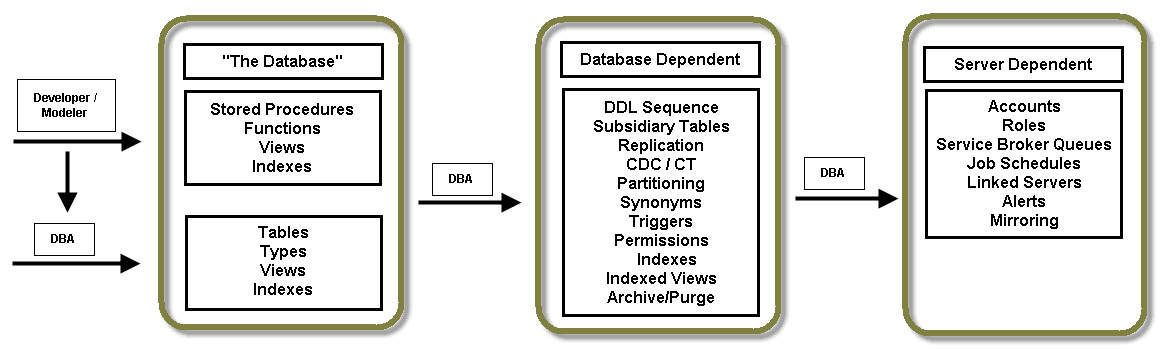
Figure 1
The left panel in Figure 1 includes the database changes prepared and committed by data modelers and developers: for us, this was stored procedures, functions, and a set of views and indexes. These database assets were synchronized to the CI systems without DBA intervention.
Then there are the tables and user-defined types that support application functionality. Developers and modelers provide approved changes to the DBAs for inclusion to the build process.
Still in the left panel, some databases were so isolated that views were left under the management of the developers, as changes did not need to be reflected elsewhere in the system. In other databases, they were treated like tables and were under the remit of the DBAs. DBAs will also review the consequences of DDL changes on indexing within that database.
The middle panel has components that are dependent on DDL changes, and may be stored in other databases and other servers. A new table may need to be added to publications, to CDC. It may need to be modified for partitioning.
By “subsidiary tables” in Figure 1, I refer to subscriber tables, staging tables, auditing tables – those storage objects that “hang off” an application table, and may not be in sight of the software development teams. The decision-making as to which tables are replicated or audited is often the remit of developers, but because the SQL Server features require some specialist knowledge, the implementation is scripted and delivered by DBAs.
The third panel lists DBA-maintained components that are less sensitive to DDL amendments, but may be subject to change arising from new functionality. DDL may come with new requirements for scheduling, cross-server communication, and security and permissions.
For our example of “create table [A] in database [B]”, this may require additional scripts to
- Create one or more modified variants of the table in other databases
- Add the table to one or more replicated publications
- Create views or indexed views for partitioning or performance
- Enable CDC or CT on the table or its variants
- Add read/write permissions on the table and its variants
Some tables require nothing more than the original script.
Some tables may require all additional pieces to be in place for Production deployment. Different DBAs may be involved in different pieces, e.g. one DBA looks after replication, and another maintains security. The different component scripts may be interdependent, and require specific sequencing across multiple servers.
Associated Scripts
To illustrate further, I’ll dive a little deeper into the DBA scripting requirements that arise from DDL changes submitted by developers: We’ll take transactional replication and Change Data Capture as examples.
Let’s say that Development Team 1 creates a table, while Development Team 2 adds a column to an existing table.
|
1 2 3 |
Create Table T1 (a int, b int, constraint PK_T1 primary key clustered (a)) Alter Table T2 Add d int NULL |
We are informed that new table T1 should be part of Publication P to a subscriber database on another server, but does not need to be part of our auditing solution.
Table T2 is already part of publication P, replicating data to a copy of the table on another server. As part of our auditing requirements, Change Data Capture (CDC) is enabled on this copy.
Ultimately, the system will change to what’s shown in Figure 2. Publication P now includes a new table. The CDC schema now includes column [d].
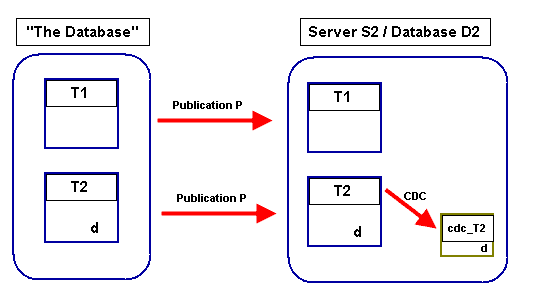
Figure 2
The scripting requirements for these associated changes to transactional replication and CDC are markedly different.
If the publication of T2 is configured in a specific way, the addition of a new column to the subscriber table will itself be replicated i.e. the engine will sending the ALTER statement to the subscriber database. There is no need for an associated script.
The new table, however, must be explicitly created on the target subscriber database(s), and added to the publication in “the Database”. The subscriber table may differ in structure to the original table. You may need to explicitly synchronize data. Scripting will vary depending on the way that the publication is configured.
If you’re not familiar with CDC, then just note that enabling it on a table results in a system table being created that contains the columns in the parent table at that time. Unlike replication, adding a column to the parent table does not result in the column automatically being added to the system table.
Therefore, altering tables under CDC usually requires more extensive scripting. To capture data for new column “d” in T2 without overall data loss, we need to produce a script to:
- copy the data in system table [cdc_T2] to some form of temporary storage
- drop/create (or create a second) CDC on the replicated table to ensure that the new column appears in system table [cdc_T2]
- migrate the data back into [cdc_T2] from temporary storage
To complete the picture, if the publication of T2 was configured differently, then we may need a script to
- add the column to the subscriber table
- add the column to the publication article
- apply an initial synchronization of data
All of this is complex the first time, and even the fourth time, but with repeated practice a DBA will look to make their life easier by auto-generating as much as possible the required syntax for these associated scripts. Dynamic SQL, stored procedures, metadata, PowerShell, Management Studio directives – any and all will make up a DBA’s box of tricks.
As it happens, there were three DBAs involved in producing the associated scripts. One looked after Publication P, the other looked after CDC, and the third maintained a filtered publication with very specific scripting requirements. It’s nice and clear here that the CDC script must be sequenced after the alteration of Publication P to include the new column, but the correct sequencing across multiple associated scripts can also get complex.
The Goal
So, to return to the question: “what do we have to change in our processes to be able to commit DDL updates daily?”
One way to automate this is via a process that cycles through each update and:
- Applies the DDL script to the target database
- Determines if any associated action is needed
- If YES — generates and applies the associated scripts to their target servers and databases
For example, the process must discern that the script contains a CREATE TABLE statement, and answer a series of questions such as:
- Should this new table T1 be added to a publication, and if so, which one?
- Should CDC be enabled on a subsidiary table of T1 in database D2 on server S3?
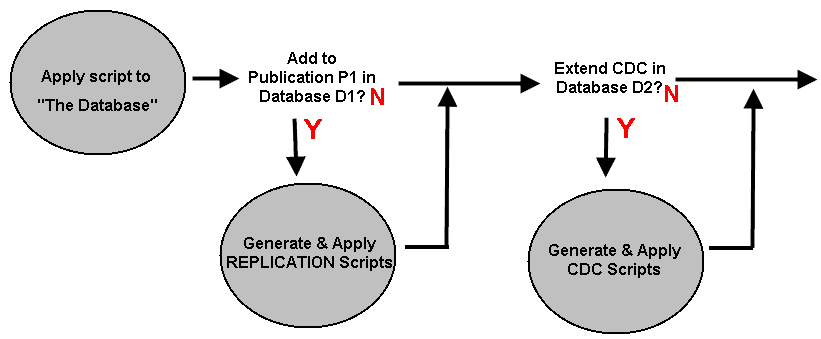
Figure 3
In some circumstances, these questions are relatively straightforward. There may be a requirement that all tables within a schema are replicated or should be under CDC.
In other circumstances, there must be a prior discussion with analysts and development teams. One development team may be the primary owner of the table for an application, but a different development team may work with a transformed subset of the data. An analyst may define the list of tables required for business auditing.
Without automation, this information will be provided to the DBA, who ensures that the appropriate additional scripts are produced and applied.
Automation would be likely to need access to reference data associating the table with the additional requirements, populated at the same time as the “CREATE TABLE” script is submitted to the process.
Deployment to “The Database”
The first sub-process in Figure 3 represents what is usually presented as the CI process: applying a series of DDL updates to a single database.
For us, meeting the prevailing approaches described in the CI literature represented a significant change in how we laid out our SQL scripts for incremental deployment. To summarize, the main changes were these:
- To move from large and lengthy SQL scripts doing many things, to a set of small “atomic” SQL scripts doing single things.
- To move to a process which determined at run-time which change scripts were needed to bring the system to the desired revision.
- To move to standardized logging for all deployments
I will address this topic in another article.
Planning for Automation
Referring to figure 1, I reiterate that significant effort by DBAs was taken up with the associated changes caused by requests submitted by the development teams: views, indexed views, synonyms, triggers, replication, change data capture and change tracking, horizontal and vertical partitioning.
The overall goal was to reduce the manual effort of producing the associated scripts, and to automate their generation wherever possible. That in itself was going to take work, and we couldn’t tackle everything at once.
So, where to start?
We can start by using a whiteboard to list out all the dependencies that must be scripted when receiving DDL changes from data modelers and developers. Don’t put any ordering at this point.
It helps to sketch out the topology of the system, and then throw out some hypothetical scenarios.
- The Business wants to record additional customer attributes, which must be audited, archived, and included in Reports and BI.
- What if we were given a script to “Drop Table [Customer]” from the mission-critical Orders database?
- The development team requests a new column to be added to every single table in “the database”. Why? ORM (sigh). It’s going to be a GUID, or XML; something awkward.
Map the ramifications all the way through to that server tucked away on the edge of the system. Work your way through different parts of the system, mentally throwing changes at it. Don’t forget the fun parts, those two databases with bi-directional data flow and linked-server views.
The benefit of an open-sky approach at the start is that you thereby avoid getting sucked into the recency effect, which can induce you to focus unduly on what transpired with the prior release, or to concentrate on a particularly headache-inducing change that took weeks to script in the past – but in light of project direction is unlikely to reoccur.
With the thought-experiments out of the way, then look at the hard evidence. Trawl through the past year or so of change scripts and add anything that isn’t already on the whiteboard. This task may, by itself, take hours.
Now that there’s a list of activities on the board, the next step is to rank them against a set of criteria. These are the headings I used, again in no particular order.
-
Most straightforward to script?
This is subjective, as it depends on the experience and skill-sets within the DBA team. For me, these are the processes where SQL Server command completion can be asynchronous: Service Broker is one example, Change Data Capture is another. Peer-to-peer replication aged me five years the first time I deployed it. -
Most associated script changes?
Which single DDL change resulted in ten other scripts? Looking back over a year of releases, we had a single table change where we changed the primary key. That itself is not trivial within “the database”, but this particular table had ramifications throughout the system. -
Most frequent occurrence?
Are there changes with the same scripting consequences with each and every release? For us, there were our auditing requirements for certain tables. New columns brought consequences to associated tables, triggers, views etc. -
Most likely to re-occur in 12 months?
For this category, it may be easier to think of the least likely changes and stick in a zero for their rank, and work upward from there. Sometimes the legacy databases are the most awkward to deal with, but they may be scheduled for end-of-life. -
Closest to already done?
It’s likely that DBAs who work frequently with a particular element of SQL Server technology already have a bundle of scripts in their back pocket that go a long way towards automation. Up front, there may be a nervousness as to whether personal scripts running on a box under the desk are ready to be made part of a formal process. Part of planning is carving out the time required for someone to make their own scripts suitable for general usage.
Sticking our categories across the top of an excel spreadsheet, and the list of associated changes down the side, we can throw subjective numbers into the matrix and tot up the totals.
For me, the top two were transactional replication, and our customized auditing solution. That left a whole lot of other pieces on the board that could be phased in over time. My goal was to get a process in place which could be extended, piece by piece.
Online References
When I started planning changes to a database deployment framework in light of Agile requirements, I used a variety of online resources to frame my approach. The blog list below dates back to what was available at the time of research, and represents what particularly clicked for me as a DBA who is primarily working with SQL Server.
-
https://martinfowler.com/articles/evodb.html#AutomateTheRefactorings
Our software colleagues are most likely to be familiar with Martin Fowler’s work on code refactoring. The linked article describes further work with Scott Ambler and Pramod Sadalage to extend the principles into database refactoring, and has been recently updated. Even just to converse with Software folk, it’s worth reading through this presentation as it may well be the jump-off point for our colleagues when they come to talk about continuous integration. This particular article is full of detailed examples of developers putting the principles into practice. -
https://michaelbaylon.wordpress.com/2011/04/13/managing-sql-scripts-and-continuous-integration/
Michael Baylon covers what a CI process looks like in a database context. As Michael is primarily into data architecture, as opposed to coming from a software slant, his layout made a lot of sense to me. -
http://paulstovell.com/blog/database-deployment
Paul Stovell provides another good look at deployment, with a SQL Server slant. What I also found heartening was the discussion in the comments of this blog, where Sly Gryphon confirmed that he had used the approach on “some very large systems”. This, along with some threads in the SQL Server forums, gave me validation that DBAs were genuinely implementing these techniques in an enterprise setting. -
http://www.sqlservercentral.com/articles/webinar/101776/
Grant Fritchey’s webinar is full of good advice about methodology and practice, sprinkled with accounts of real-life scenarios and conversations with developers that were becoming increasingly familiar to me. What sticks with me in particular is validation that there is no single correct answer or tooling to put automation and CI into place. “I don’t care what you’re using…take advantage of the tools you know to make sure that you automate this stuff.” -
https://www.scribd.com/document/80497683/Taking-Control-of-Your-Database-Development
This paper by Nick Ashley was originally presented on dbdeploy.com, but that website seems to come and go. It documents an open-source project to automate a CI database deployment process for a database using Ant, PowerShell and a source control management tool. As the tooling was pretty close to what we used for our baseline builds, I paid a lot of attention to this article as a means to building on what we already had. -
https://www.simple-talk.com/collections/database-lifecycle-management-patterns-practices-library/
My initial research predated the build-up of articles in the Simple-Talk library, and I’d recommend anyone trying to get to grips with this area to work through the articles here.
Load comments