
In Level 10 we looked at the internal structure of an index. Given this knowledge of index structure, we can examine index fragmentation: causes, cures, and when not to care.
Some Background / Review Information
The following knowledge is essential to understanding index fragmentation. Some of this information has been presented in earlier levels, in the context of using indexes to retrieve data. In this level, the context is index maintenance; thus, some old information is repeated here, and some new information is added.
Every table is either a heap or a clustered index.
If the table is a heap, then the bookmark portion of the nonclustered indexes is a row identifier (RID). If the table is a clustered index, then the bookmark portion of the nonclustered indexes is the clustered index’s key values.
Index entries are stored in pages. Eight physically consecutive pages comprise an extent.
Index levels are numbered from the bottom up, starting at zero. Thus, the leaf level is always Level 0 and the lowest intermediate level is always Level 1. The root page will be a level unto itself, and will have the highest level number.
To scan an entire index means each page at the leaf level must be read once and only once. Each page contains a pointer to the next page and to the previous page. The logical sequence and the physical sequence of pages may differ. The pointer to the next page might point to a page in the same extent; or to a page that resides hundreds of pages in front of, or behind, the current page; or even to a page in a different file.
The greater the correlation between the physical and logical sequence of pages, the fewer the number of IOs required to scan the index. When the two sequences are aligned, SQL Server can read an entire extent, or more, per IO. Also, the greater the correlation between the physical and logical sequence of pages, the more read-ahead reads can be used, bringing pages into memory before they are needed. This is true whether the entire index, or just a section of the index, is being scanned.
To retrieve a single index entry, one page from each level, starting with the root page, must be accessed. The performance of this operation is not affected by the correlation between an index’s logical and physical sequences.
With this information in mind, we can examine the subject of index fragmentation.
What is Fragmentation?
Index fragmentation comes in two varieties – internal fragmentation and external fragmentation. The best tool for determining the fragmentation, either internal or external, of an index is the sys.dm_db_index_physical_stats dynamic management function. Because this function displays the index id, but not the index name, queries often join it with the sys.indexes view, so as to include the index name in the output. We’ll be using this function throughout this Level, as first we cover internal fragmentation and then address external fragmentation.
Internal Fragmentation
Every page can hold a certain number of entries. That does not mean that a page always holds the maximum number of entries. Usually an index page is not completely full, for reasons that will be covered in later in this Level. When we say that an index has internal fragmentation, we mean that the pages are not completely full. The average amount of occupied space per page in an index is a measure of the internal fragmentation of the index; also referred to as the average page fullness of the index. Note that the higher the measurement, the lower the internal fragmentation; a page that is 100% full has no internal fragmentation.
Internal fragmentation is normally reported as a percentage; and it indicates the fullness in bytes, not in entries. Thus, an index page that has an internal fragmentation of 96% might be completely full. That is, 4% of the page might not be enough empty space for a new entry to be added. When the space occupied by page header information and page offset pointers is accounted for, a page whose individual index entries are relatively large might be “full” at 90%, 80% or even less..
The sys.dm_db_index_physical_stats function reports internal fragmentation in its avg_page_space_used_in_percent output column. The query shown in Listing 1, which examines the SalesOrderDetail table’s clustered index, displays internal fragmentation information:
SELECT IX.name AS 'Name'
, PS.index_level AS 'Level'
, PS.page_count AS 'Pages'
, PS.avg_page_space_used_in_percent AS 'Page Fullness (%)'
FROM sys.dm_db_index_physical_stats(
DB_ID(),
OBJECT_ID('Sales.SalesOrderDetail'),
DEFAULT, DEFAULT, 'DETAILED') PS
JOIN sys.indexes IX
ON IX.OBJECT_ID = PS.OBJECT_ID AND IX.index_id = PS.index_id
WHERE IX.name = 'PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID';
GO
Listing 1: A query to return internal fragmentation values
The query returns one row of output for each level in the index, as shown in Figure 1:

Figure 1: Output from the internal fragmentation query
The subject of this particular query is a clustered index; thus, the leaf level of the index is the rows of the table. The output row for level 0, the first row in the above output, tells us that the table’s rows are spread over 1234 pages which are, on the average, 99% full. In other words, this table has minimal internal fragmentation.
External Fragmentation
In contrast to internal fragmentation, external fragmentation refers to the lack of correlation between the logical sequence of an index and its physical sequence. It also is reported as a percentage. To quote Microsoft Technet, it is “the percentage of out-of-order pages in the leaf pages of an index. An out-of-order page is a page for which the next physical page allocated to the index is not the page pointed to by the next-page pointer in the current leaf page.” Although the Technet definition limits itself to the leaf level only, you will note that sys.dm_db_index_physical_stats can return fragmentation information for all levels of an index.
Note that, unlike internal fragmentation, a higher number means a greater amount of external fragmentation; thus an index with an external fragmentation of 100% is completely fragmented externally. That is, there is no correlation at all between its logical and physical sequence of pages.
Consider the simple example illustrated in Figure 2. A sixteen page index occupies the extents starting at pages 40 and 56 of a database file. Except for the last page in each extent, every page’s next-page pointer points to the next page in the extent. The last page in the extent at page 40 points to the first page in the extent 56. The last page in the extent at page 56 does not point to any page, for it is the last page in the index.
In this example, the number of out-of-order pages is zero. Although the eighth and ninth pages are not physically contiguous within the file, they are contiguous within the space that has been allocated to the index, and that is what counts. Thus, the external fragmentation for this example is zero.
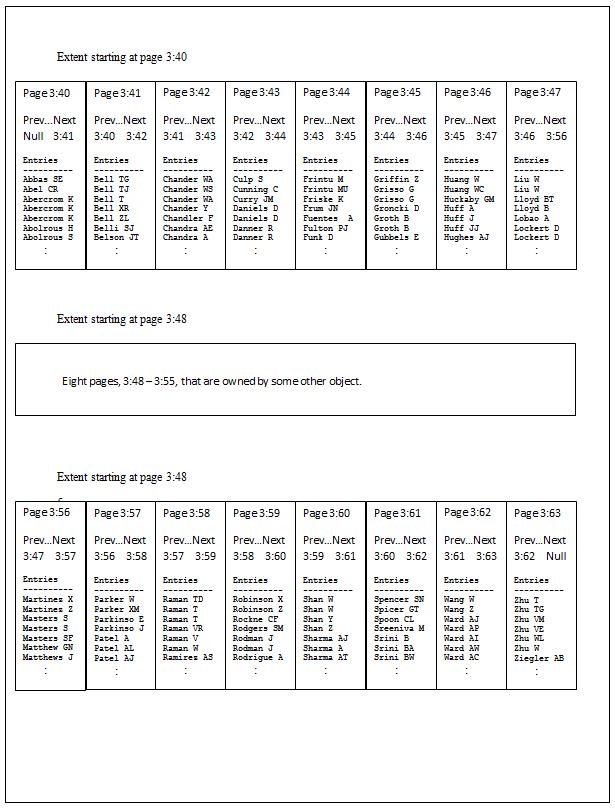
Figure 2 –Index with no external fragmentation
On the other hand, the Figure 3 shows the same table, but with some out-of-order pages. The first three pages are logically contiguous, but after that there is no correlation at all between logical sequence and physical sequence.
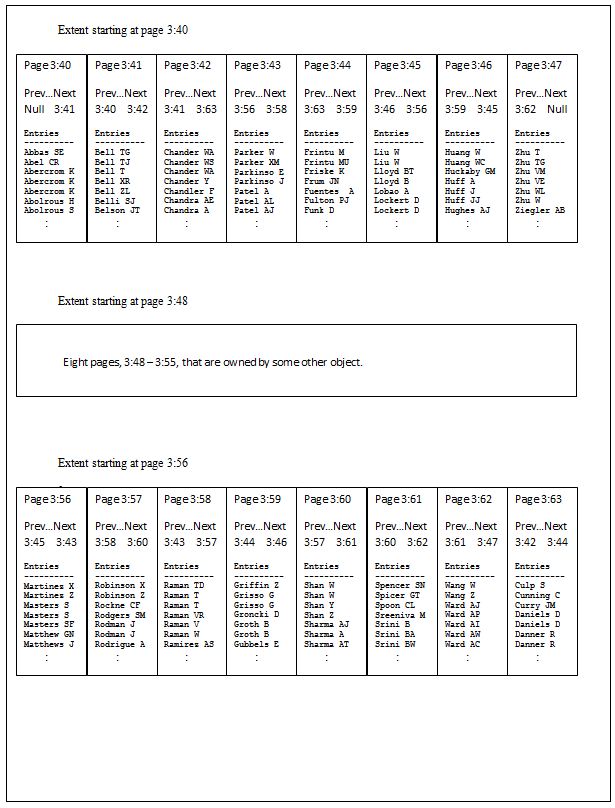
Figure 3 –Index with external fragmentation
Any next-page pointer that does not point to the next physically allocated page of the index is an out-of-order pointer; regardless of whether it points forwards, backwards, within the extent, across extents, or even across files.
To illustrate how to obtain external fragmentation information for an index, we make two changes to our previous query.
Because external fragmentation concerns the relationship between pages, but not the content of the pages, it can be determined by scanning Level 1 of the index; rather than having to scan the much larger leaf level of the index. We inform SQL Server that a leaf level scan will not be necessary by changing the function’s last parameter from DETAILED to LIMITED (or DEFAULT).
Also, we modify the SELECT clause to include a slightly different set of columns, those that provide external fragmentation information.
The resulting query is shown in Listing 2:
SELECT IX.name AS 'Name'
, PS.index_level AS 'Level'
, PS.page_count AS 'Pages'
, PS.avg_fragmentation_in_percent AS 'External Fragmentation (%)'
, PS.fragment_count AS 'Fragments'
, PS.avg_fragment_size_in_pages AS 'Avg Fragment Size'
FROM sys.dm_db_index_physical_stats(
DB_ID(),
OBJECT_ID('Sales.SalesOrderDetail'),
DEFAULT, DEFAULT, 'LIMITED') PS
JOIN sys.indexes IX
ON IX.OBJECT_ID = PS.OBJECT_ID AND IX.index_id = PS.index_id
WHERE IX.name = 'PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID';
GO
Listing 2: A query to return external fragmentation
Because we specified LIMITED for the last parameter, we will get only one row of output, shown in Figure 4:

Figure 4: Output to the external fragmentation query
The results tell us that our index is 1234 pages in size, consisting of 20 fragments with an average size of 61.7 pages each. Just as one cut through a piece of wood results in two pieces, and two cuts results three pieces; one out-of-sequence next-page pointer results in two fragments, two out-of-sequence next-page pointers results in three fragments, and so on. Therefore, our index has 20-1 = 19 pages that have out-of-sequence next-page pointers. On average, when scanning this index in logical sequence, 61contiguous pages will occur between each out-of-sequence page. This is an index with very little external fragmentation.
Management studio’s Index Properties window, shown in Figure 5, obtains its information by doing a query similar to the one we have been doing. It refers to internal and external fragmentation by the terms Page fullness and Total fragmentation respectively.
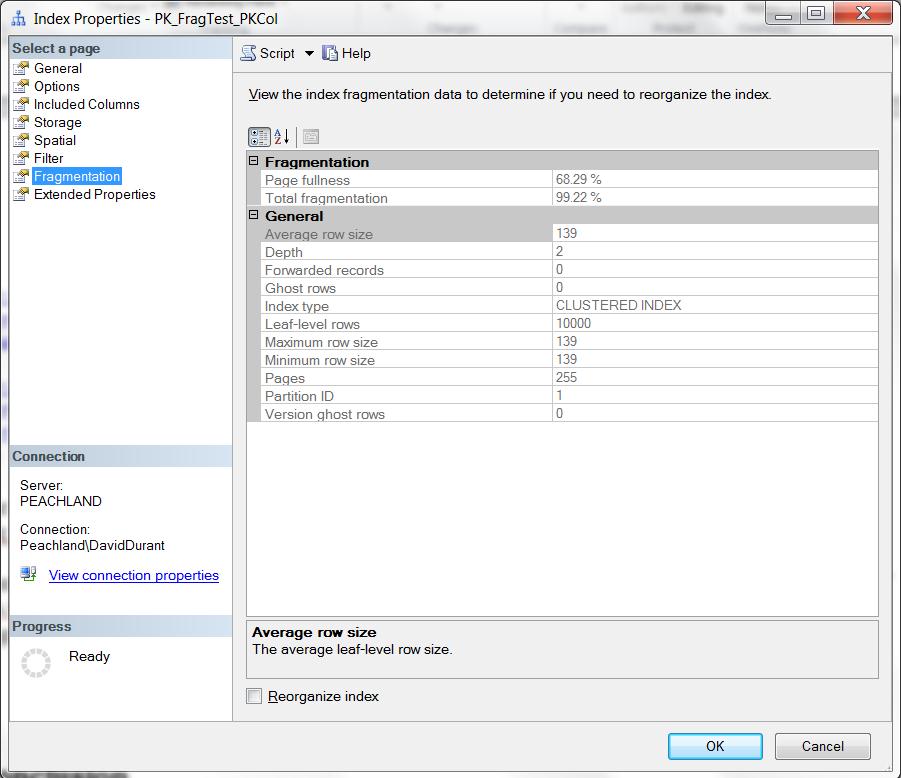
Figure 5: SQL Server Management Studio’s Index Properties window
What Causes Fragmentation
To discuss the cause of fragmentation, and the techniques for avoiding and removing fragmentation, we must steal some information from two upcoming topics of this Stairway: information about creating / altering an index, and about inserting rows into an indexed table.
As we cover this information, remember what was mentioned in the background section of this Level; fragmentation is undesirable only if your application is scanning an index; be it a complete or partial scan. Fragmentation is not a problem when your application is retrieving a small number of entries for a single index key value; as in the five row query shown in Listing 3:
SELECT * FROM Sales.SalesOrderDetail WHERE SalesOrderID = 56080; GO
Listing 3: A highly selective query
When you create or rebuild an index on a table that has been populated, a reallocation of disk space occurs, resulting in an index that has little or no external fragmentation. The amount of internal fragmentation is determined the value you specify for the FILLFACTOR option; which determines page fullness. No attempt is made by SQL Server to preserve this page fullness during subsequent data modifications. As rows are inserted into a table, and the resulting entries are inserted into the index pages, those pages will become ever fuller.
Eventually SQL Server may attempt to insert an entry into a page that is already full. When this happens, SQL Server will search its allocation structures to find an empty page. Once it has found an empty page, it will do one of three things, each dependent on the sequence in which new index keys are being inserted:
Random Sequence: Normally, SQL Server will move half the entries (those of higher key value) from the full page to the empty page, and then insert the new entry into the appropriate page, thus producing two pages that are half full. This technique is called page splitting, and is the reason why indexes of this type are known as balanced tree indexes. Since there is little chance that the new page is physically adjacent to the old page, there will be an increase in external fragmentation. If your application continues to insert, but not delete, rows; these two pages will eventually grow from half full to full, where upon they will split into pages that are half full. Over time, every page cycles from half full to full, again and again; resulting in an internal fragmentation (average page fullness) of approximately 75%.
Ascending Sequence: If, however, SQL Server notes that the new entry would be the last entry on the full page, it will assume that rows are being inserted into the table in the same sequence as the index. In this scenario, if the index was created on the LastName column; and a “Kimmel” entry is to be placed at the end of the page, SQL Server assumes that the “Kimmel” row will be followed by another “Kimmel” row, or perhaps a “Kinder” row. Therefore, it places the new row, and only the new row, in the empty page. If the table was empty when the inserts began, the new page is the last page in the index, both logically and physically. Thus, the external fragmentation remains near zero. If SQL Server was correct in its assumption that rows are arriving in index key sequence, a full page will never split. Once a page becomes full, it stays full; resulting in little or no internal fragmentation.
Descending Sequence: Conversely, if SQL Server notes that the new entry would be the first entry on the full page, it will assume that rows are being inserted into the table in descending sequence. In this situation; SQL Server assumes that a “Kimmel” row will be followed by another “Kimmel” row or perhaps a “Kimato” row. Once again, it places the new row, and only the new row, in the empty page. The increase in external fragmentation is the same as for the random sequence scenario. But the internal fragmentation is the same as the ascending sequence scenario; at or near 100%.
Once new the entry is placed into a page, some cleanup must be done. Four next-page / previous-page pointers, spread over three pages, must be updated; and an entry pointing to the new page must be inserted at the next higher level of the index; which, in turn, might result in page split at that index level.
So, although page splitting is beneficial because it keeps the index balanced, unnecessary page splitting should be avoided; this topic will be covered later in this Level.
We can verify the three behaviors mentioned above with three simple demos. Each one will use a simple two column table that has an index on one column that you can create by running the code in listing 4.
USE AdventureWorks; GO CREATE TABLE dbo.FragTest ( PKCol INT NOT NULL , InfoCol NCHAR(64) NOT NULL , CONSTRAINT PK_FragTest_PKCol PRIMARY KEY NONCLUSTERED (PKCol) ); GO
Listing 4: A simple table with 1 index
In each demo we insert 50,000 rows into the table in one of the three possible sequences; random, ascending and descending. At the end of each load, we view the fragmentation using the query shown in Listing 5.
SELECT IX.name AS 'Name'
, PS.index_level AS 'Level'
, PS.page_count AS 'Pages'
, PS.avg_page_space_used_in_percent AS 'Page Fullness (%)'
, PS.avg_fragmentation_in_percent AS 'External Fragmentation (%)'
, PS.fragment_count AS 'Fragments'
, PS.avg_fragment_size_in_pages AS 'Avg Fragment Size'
FROM sys.dm_db_index_physical_stats( DB_ID(), OBJECT_ID('dbo.FragTest')
, DEFAULT, DEFAULT
, 'DETAILED') PS
JOIN sys.indexes IX
ON IX.OBJECT_ID = PS.OBJECT_ID AND IX.index_id = PS.index_id
WHERE IX.name = 'PK_FragTest_PKCol';
GO
Listing 5: The fragmentation query
It does not matter that the index is nonclustered; the results would be similar if it were a clustered index.
Randomly Inserting Rows
For our first demo, we insert 50000 rows that have random index key values, using the technique shown in Listing 6.; and then view the resulting fragmentation, shown in Figure 6:
TRUNCATE TABLE dbo.FragTest; GO DECLARE @limit INT; SET @limit = 50000; DECLARE @counter INT; SET @counter = 1; DECLARE @key INT; SET NOCOUNT ON;WHILE @counter <= @limit BEGIN SET @key = CONVERT(INT, (RAND() * 1000000)); BEGIN TRY INSERT dbo.FragTest VALUES (@key, 'AAAA'); SET @counter = @counter + 1; END TRY BEGIN CATCH END CATCH; END; GO
Listing 6 : Random sequence inserting
The fragmentation resulting from random inserts, shown in Figure 4, is what we expected. The output tells us that the average leaf level page is slightly less than 75% full. It also tells us that the index is completely fragmented; that is, every page is its own fragment, meaning that no next-page pointer points the physically following page.

Figure 6: Random insert fragmentation
Inserting Rows in Ascending Sequence
Next, we modify our batch so that it inserts rows of sequentially increasing index key values, as shown in Listing 7.
TRUNCATE TABLE dbo.FragTest; GO DECLARE @limit INT; SET @limit = 50000; DECLARE @counter INT; SET @counter = 1; SET NOCOUNT ON; WHILE @counter <= @limit BEGIN BEGIN TRY INSERT dbo.FragTest VALUES (@counter, 'AAAA'); SET @counter = @counter + 1; END TRY BEGIN CATCH END CATCH; END; GO
Listing 7: Ascending sequence inserting
After inserting the rows, we again run the query shown in Listing 5, and get the results shown in Figure 7, indicating that the pages are densely packed, and that external fragmentation is near zero. Because external fragmentation is near zero, SQL Server can scan the index by reading one extent, or more, per IO; IO that can be done as read-ahead reads.

Figure 7: Ascending sequence insert fragmentation
Inserting Rows in Descending Sequence
Next, we modify our batch so that it inserts rows of sequentially decreasing index key values, as shown in Listing 8.
TRUNCATE TABLE dbo.FragTest; GO DECLARE @limit INT; SET @limit = 50000; DECLARE @counter INT; SET @counter = 1; SET NOCOUNT ON; WHILE @counter <= @limit BEGIN BEGIN TRY INSERT dbo.FragTest VALUES (@limit - @counter, 'AAAA'); SET @counter = @counter + 1; END TRY BEGIN CATCH END CATCH; END; GO
Listing 8: Descending sequence inserting
Again, after inserting the rows, we run the Listing 5 query, and examine the results, shown in Figure 6.

Figure 8: Descending sequence insert fragmentation
We can see that the pages are full, but the file is totally fragmented. This latter fact is slightly misleading, for the pages of the index are contiguous; but the first page in index key sequence is the physically last page in the file. Each next-page pointer points to the physically previous page, thus giving the file its high external fragmentation rating.
Descending sequence inserts are rare, and often the result of requesting data from an outside source in descending sequence by date or by monetary value. Whenever you anticipate a descending sequence insert pattern, be sure to specify DESC when you create the index; as shown in Listing 9.
CREATE INDEX IX_SalesOrderHeader_OrderDate ON Sales.SalesOrderHeader ( OrderDate DESC , SalesOrderID ); GO
Listing 9: Creating a descending sequence index
This turns the index into an ascending sequence insert pattern index, thus eliminating the external fragmentation problems.
Deleting / Updating Rows
Thus the insert sequence of rows; be it random, ascending or descending; impacts fragmentation. But most rows do not remain in a table forever, eventually they are deleted; which also effects fragmentation.
Updates too can impact fragmentation, but only if either:
A column being updated participates in the index’s key.
Or
The update causes a variable width column to increase in size such that the index row can no longer fit on the page.
In either case the update will treated as a delete followed by an insert.
Therefore, at this point we need to look at common combinations of insert / delete patterns and their resulting fragmentations. By knowing these patterns, you can apply your knowledge of your database’s indexes and your application’s data modification activity to anticipate the fragmentation that will occur. If this fragmentation, for any index, is unacceptable; you can apply the information presented later in this Level and in Level 12 – Create Alter Drop to prevent or moderate that fragmentation.
Common Fragmentation Patterns
If a table has multiple indexes, those indexes will have different keys, and therefore different sequences. Typically, one or two of the indexes might exhibit the ascending insert pattern described earlier; the others will normally exhibit the random insert pattern.
Candidates for the ascending insert pattern include indexes whose left most column is:
- A chronological column; such as TransactionDate.
- A column with IDENTITY property.
- A UniqueIdentifier column with a NewSequentialId() default constraint.
When taking inserts and deletes into account, five common fragmentation patterns emerge. Four out of the five usually benefit from index maintenance; which is covered later in this Level and in further detail in Level 12 – Create Alter Delete.
Ascending insert – ascending delete
An index on the transaction date column of a transaction table would match this pattern. It would maintain high page fullness and low external fragmentation. Rows are being added to the page at the high end of the index while they are being deleted from the page at the low end. New pages become full, old pages become empty, and therefore eligible to become new pages again. It is a nice pattern, but only a few indexes in a typical database match this pattern.
Ascending insert – random delete
Indexes on columns with the system assigned, ever increasing, values mentioned above are an example of this pattern. A new page fills quickly, then slowly empties over a long period of time as old rows are randomly removed from it, but no new rows are added to it. The external fragmentation remains low; but the page fullness averages only 50%, starting at full and dropping to empty. Not a common pattern, but indexes that match it may need periodic maintenance.
Random insert – periodic delete
Transaction processing will also produce this pattern; new rows are continually added, but not in index sequence; old rows are periodically removed. The index on the Sales.SalesOrderDetail table’s ProductID column is an example of this. As was mentioned above, the continual adding of randomly inserted rows produces an average page fullness of 75%. The subsequent periodic deletes will reduce the fullness of the page. Then the next cycle of inserts will, over time, raise the fullness back to 75%. External fragmentation remains high and page fullness is unnecessarily low. Since most indexes on a table will have random inserts, not ascending inserts, this is a very common pattern and such indexes may need periodic maintenance.
Random insert – random delete
A lending library’s OnLoan table that has a clustered index on the book’s ISBN number is an example of this. When a book is borrowed, a row is inserted into the table; when the book is returned, the row is removed. Activity is evenly spread across the table; the total number of rows remains fairly constant over time An index like this may need periodic maintenance.
Massive insert – no delete
Better known as bulk copy; a process for importing / exporting large numbers of rows to / from a table. Tables populated by bulk copy operations may benefit from dropping all the table’s indexes, or all the indexes except the clustered index, performing the bulk copy, and then recreating the indexes. Recommendations for this pattern are based on the optimization of the logging process, which is beyond the scope of this Stairway, more than on the optimization of the indexes themselves.
Prevention and Cure for Fragmentation and Page Splitting
(Aka – Periodic Maintenance)
The next Level in this Stairway discusses two index maintenance options; index rebuilding, which eliminates external fragmentation and gives you control over the page fullness of the rebuilt index, and index reorganizing, which reduces external fragmentation and may increase page fullness, in detail. For simplicity in this section, we generically use the phrase “rebuild the index”. Your specific situation will determine if rebuild or reorganize is the appropriate choice.
Our objective in this last section of this level is to give you an understanding of the goal you must have when performing index maintenance. And that goal is: To produce an index that will have the best page fullness, the least amount of external fragmentation, and smallest amount of page splitting for the foreseeable future.
Example #1
For example, suppose you decide that the SalesOrderHeader table must hold one year’s worth of orders. After the table is a year old, on a monthly basis, you will remove and archive all rows that are more than one year old. Thus, your indexes’ content will vacillate between twelve and thirteen months of entries. Most of the table’s indexes have the random insert pattern, with new rows and old rows being distributed evenly across the index.
If you can generate these indexes with a desired maximum size values early in the life of the table; they will maintain a low external fragmentation over a long time with a minimum of page splitting. As each entry arrives at a page, there will room in that page for the entry. As each page becomes nearly full, monthly processing removes one month’s entries; leaving the page with sufficient empty space for another month of inserts.
Random distribution does not mean smooth distribution. In fact, it guarantees that there will be bumps in the number of entries per page. Thus, you might decide that the first time the index is created after rows have been added to the table, each index page should have enough empty space to ensure that it can hold fourteen, rather than thirteen, months of data. The extra disk space is small price to pay for a smoothly functioning index.
You start with an empty table, on which you create the indexes. After one month, your table is 1 / 14th the size that you want it to be. The table’s random-insert-sequence indexes are highly fragmented, each index page is approximately 75% full, and continued growth is causing page splits.
If you now rebuild these indexes with a fill factor of 100 / 14, that is 7%, as shown in Listing 10, you will have indexes that are the desired size, have minimal external fragmentation, and are ready to receive the entries that will soon be added to them.
ALTER INDEX AK_SalesOrderHeader_rowguid ON Sales.SalesOrderHeader REBUILD WITH ( FILLFACTOR = 7 ); GO
Listing 10: Rebuilding an index for future growth
You might argue that, since the index is now spread across far more pages than it was, scanning the index will require more page reads and take more time than it would have had the index not been rebuilt. This is true. However, the performance is exactly what it will be eleven months from now. If that performance is not good enough, it is best to find out now rather than later. Also, when scanning the index, most reads will now be a read-ahead extent reads rather than on-demand single page reads; so index scanning performance might not be as bad as you anticipate.
Example #2
Suppose that you do what was recommended in Example #1, and one year later you decide that the index needs further maintenance. Your index has the random insert – periodic delete pattern. Immediately after the periodic delete, rebuild the index with a FILLFACTOR that will be small enough to accommodate one month of inserts; perhaps 80% – 84 %. This will eliminate external fragmentation and produce pages that are as full as they can be while minimizing page splits for one month. Each month, after the deletes have been done, repeat the process.
Example #3
This example covers the random insert – random delete pattern. Rebuild the index with a FILLFACTOR that will create a few rows worth of empty space in the pages; maybe three or four. Just enough empty space so that a random surge of inserts does not overfill the page and cause a page split.
Example #4
Our last example covers the sequential insert – random delete pattern. Periodically, rebuild the index with a FILLFACTOR of 100%. Rebuilding will eliminate external fragmentation. There will be no page splitting, because rows are inserted into the new pages, not the existing pages. Since existing pages only experience deletes, they should start out as full as possible.
Conclusion
Fragmentation can be either internal or external.
Internal fragmentation refers to empty space left within the index pages.
External fragmentation refers to the deviation of the logical sequence (index key order) of an index’s pages from the physical storage sequence.
External fragmentation can slow the performance of index scans. It has no impact retrieving a small number of rows based on index key.
Internal fragmentation increases the size of the index.
Page splitting is extra overhead and causes external fragmentation. Unnecessary page splitting should be avoided. The best way to avoid page splitting and external fragmentation is to periodically rebuild / reorganize the index to produce an index that will have the best page fullness, the least amount of external fragmentation, and smallest amount of page splitting for the foreseeable future.