

Inspiration
There is often a requirement in database for multiple queries in different connection threads to read/update the same table. This concurrency can lead to blocking and is automatically handled by SQL server to prevent dirty reads.
However there can be a scenario where in each of the queries read/update mutually exclusive sets of rows from the table. Here in this article I wish to show how indexes can be used suitably to reduce blocking scenarios so that multiple queries can simultaneously read/update a table.
Scripts
The sample scripts to create a table in a database for testing are given under.
TABLE CREATION
/****** Object: Table [dbo].[Profit_Act]
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
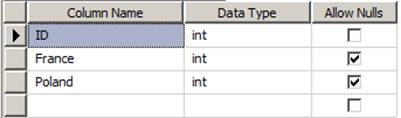
CREATE TABLE [dbo].[Profit_Act](
[ID] [int] IDENTITY(1,1)NOT NULL,
[France] [int] NULL,
[Poland] [int] NULL
) ON [PRIMARY]
GO
DATA INERTION INTO THE ROWS
INSERT INTO [Bibby].[dbo].[Profit_Act]
([France]
,[Poland])
VALUES
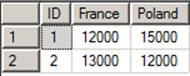
(12000,15000),(13000,12000)
GO
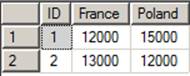
So this is how the data in the table looks.
SQL Server LOCKING
Now we need to test LOCKING in SQL Server. If we fire up two query windows in SQL Server Management studio and begin two read/update transactions (to simulate two simultaneous connection threads) we find that they lock each other
1st Query
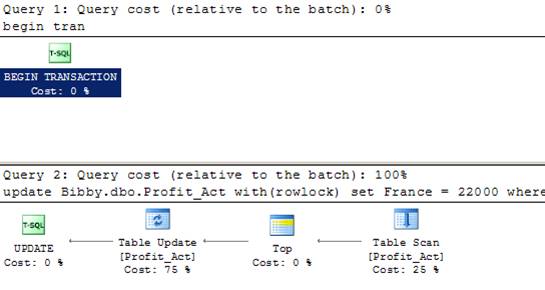
BEGIN TRAN update Bibby.dbo.Profit_Act with(rowlock)//rowlock is the default lock level set France = 22000 where ID=2
2nd Query
BEGIN TRAN update Bibby.dbo.Profit_Act with(rowlock)//rowlock is the default lock level set France = 24000 where ID = 1
We see that the 1st transaction performs a table scan and locks all the rows – even the rows it won’t need for its update functionality. We find this in the execution plan of the first query shown below.
The fact that a table scan is occurring can also be shown by studying the output of the stored procedure sp_lock . It reports information about all the locks in the various resources in a SQL Server instance at that point in time. The command to execute it is
EXEC sp_lock
At this point before delving into what this table output means I would like to explain some locking fundamentals which would help better understand what exactly is happening.
LOCK MODES
The SQL server database engine locks resources/objects from concurrent transactions by using different LOCK Modes. Here I would discuss the most frequently used LOCK Modes by SQL Server.
- Shared (S)
- Update (U)
- Exclusive (X)
- Intent Locks(I*) where * could be S,U or X
The other locks used by other SQL Server are Schema, Bulk Update and Key-range locks. The Microsoft Technet link to better study these locks are http://technet.microsoft.com/en-us/library/ms175519.aspx.
Shared (S) Locks - If you have a look at the Mode column in the table above you will see some rows having the lock mode as S. This lock is issued on a resource when reading data (by using the SELECT) statement. This lock allows concurrent transactions to read a resource (row/key/page/table). But no transaction can modify data in a resource as long as a Shared lock is placed on it.
Exclusive (X) Locks – Exclusive locks are issued on resources when modifying data. An Exclusive lock does not allow concurrent transactions to read or write to a resource. Read operations can only take place if the NOLOCK query hint is given or the transaction isolation level is set to read uncommitted. This might lead to dirty reads and does not allow Shared locks to be issued on the resource. However this query hint may lead to significant query execution time improvement in certain scenarios where dirty reads are acceptable to a small level.
Update (U) Locks – The primary reason for update locks to be present in SQL Server is to prevent a common form of deadlocking.
Let us consider an Update scenario in the absence of an Update lock. When a transaction intends to update a resource, it first reads it thereby placing a Shared lock on it. Then it places an Exclusive(X) lock so that no other transaction can place locks on it. The problem arises when two concurrent transactions try to update a resource. Each places a shared lock on the resource. Now each of these transactions will wait for the other transaction to release it Shared lock mode so that an Exclusive lock can be placed. Thus a deadlock scenario will occur.
In order to prevent such deadlocks the first transaction that tries to update a row immediately tries to place an Update lock on the resource. By rule only one transaction at any time can obtain an Update lock on a resource at any time. The second transaction will wait till the first transaction converts the update lock into an exclusive lock, completes the transaction and then releases the lock.
Intent (I*) Locks – The name intent lock defines the purpose of this lock. An intent lock is placed on resources higher in the hierarchy to denote that one or more of its child resources are locked.
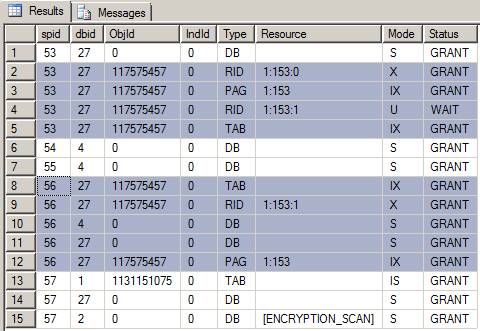
In the above o/p snapshot we see in rows 8,12 that an Intent Exclusive (IX) lock placed on the page and table because one of its rows have been locked with an Exclusive lock.
Intent locks serve two purposes:
- To prevent other transactions from modifying the higher-level resource in a way that would invalidate the lock at the lower level.
- To improve the efficiency of the Database Engine in detecting lock conflicts at the higher level of granularity.
Intent locks improve database performance because now the database engine can only check to see whether there are any intent locks on the table to determine whether another transaction can be allowed to lock the entire table for some purpose. There isn’t a need to check each and every row in the table to determine locking feasibility for another transaction.
Ok. Now with this slightly long background we can now push forward to examine the locking scenario being discussed. Just one more thing
Resource Identification :-
- RID – single row in a table identified by a row identifier (RID).
- KEY – the atomic object in an index
- TAB – an entire table, including all data and indexes
- PAG – a data or index page
Just to recall my table now looks like
The rows 8,9,12 in the sp_lock stored procedure execution output have been brought about by the first transaction T1
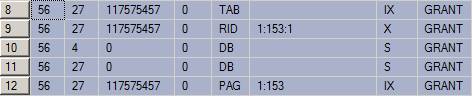
BEGIN TRAN update Bibby.dbo.Profit_Act with(rowlock)//rowlock is the default lock level set France = 22000 where ID=2
and 1:153:1 points to the second row in the Bibby.Profit_Act table.
I have not ended the transaction and have allowed the locks to be kept alive.
Now executing my second transaction T2
BEGIN TRAN update Bibby.dbo.Profit_Act with(rowlock)//rowlock is the default lock level set France = 24000 where ID = 1
leads to the locks shown by the rows 2,3,4,5 in the sp_lock output.

11757457 ObjID is actually the ID for the Bibby.Profit_Act table. 1:153:1 is the first row in the Bibby.Profit_Act table. The interesting thing to note is the X lock has been granted on this first row, but the transaction goes into a waiting state when it tries to lock the second row as well which is 1:153:1 (Note the Status column showing ‘WAIT’ status) for the update lock being requested.
The reason for this is obvious!The first transaction has not ended and released the exclusive lock on the second row thereby locking the update request by the second transaction.
This scenario leads me to reiterate the inspiration for my paper
How can I allow concurrent transactions to update rows in the same resource knowing that they are going to update a mutually exclusive set of rows? Here T1 transaction needs to update a row different from what T2 needs to update but ends up blocking the completion of the T2 transaction.
What else but use INDEXES. Let’s introduce indexes.
INDEXES
Indexes reduce the number of seeks that must occur in a table/page to find a row/set of rows. They are generally seen as a method to reduce execution times for SELECT * queries and rightly too. They are not considered suitable for tables involved in large number of UPDATES. In fact INDEXES are found to be unfavorable in these cases as they increase the time taken to complete UPDATE queries.
But this is not always the case. Delving slightly deep into the execution of an UPDATE statement we find that it too involves executing a SELECT statement first. This is a special and an often seen scenario where queries update mutually exclusive sets of rows. INDEXES here can lead to significant increase in performances of the database engine contrary to popular belief.
Now let us get back to our case which exemplifies this scenario. Let us create a clustered index on the primary key, the ID column which is the column being queried in the where clause of T1 and T2.
DATA INERTION INTO THE ROWS
USE [Bibby]
GO
ALTER TABLE [dbo].[Profit_Act] ADD CONSTRAINT [PK_Profit_Act] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF,STATISTICS_NORECOMPUTE =OFF, SORT_IN_TEMPDB = OFF,IGNORE_DUP_KEY = OFF,ONLINE = OFF,ALLOW_ROW_LOCKS =ON,ALLOW_PAGE_LOCKS =ON)ON [PRIMARY]
GO
The query execution plans of the two Transactions T1 and T2 now show that the index is being used.
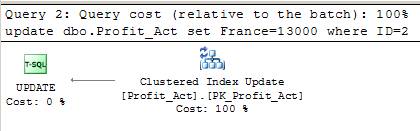
Now let us once again try running our two transactions simultaneously and see whether on blocks the other.
1st Query
BEGIN TRAN update Bibby.dbo.Profit_Act with(rowlock)//rowlock is the default lock level set France = 22000 where ID=2
2nd Query
BEGIN TRAN update Bibby.dbo.Profit_Act with(rowlock)//rowlock is the default lock level set France = 24000 where ID = 1
Halloa! Just as expected the second transaction dint get blocked. The output said

Let us see why this happened. What do we see now in the output of the sp_lock stored procedure?
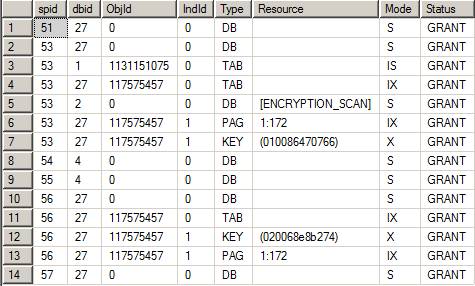
We do not see any RID entries in the Type column and this should be expected. Our transactions are using indexes and we should see KEY entries.
Looking at the above output closely (particularly rows 7 and 12) we see that the Exclusive locks on these rows have been granted (identified by the HEX resource numbers assigned to the keys). This is what points to the two rows of our table. The intent locks just as earlier are present on the page and the table here as well.
We should realize that a table scan has not been performed to identify the independent set of rows which should be updated by the transactions.
Conclusion
Thus we see that having a proper index set up can significantly reduce blocking amongst updating queries and would allow multiple simultaneous transactions to update a table. This methodology can be used extensively in table UPDATING scenarios with proper knowledge of exclusive rows that may be accessed by the various queries
References
Lock Modes
http://technet.microsoft.com/en-us/library/ms175519.aspx
sp_lock
http://msdn.microsoft.com/en-us/library/ms187749.aspx
Understanding SQL Server Locking
http://www.mssqlcity.com/Articles/General/sql2000_locking.htm
Advanced SQL Server Locking
http://www.sql-server-performance.com/articles/per/advanced_sql_locking_p1.aspx


