This is the eighth in a series on setting up a Data Science Laboratory server – the first is located here.
My plan is to set up a system that allows me to install and test various methods to store, process and deliver data. These systems range from simple text manipulation to Relational Databases and distributed file and compute environments. Where possible, I plan to install and configure the platforms and code locally. The outline of the series so far looks like this:
- Setting up the Data Lab
- Text Systems
- Testing the Tools
- Instrumentation
- Interactive Data Tools
- Programming and Scripting Languages
- Relational Database Management Systems
- Key/Value Pair Systems (this article)
- Document Store Databases
- Graph Databases
- Object-Oriented Databases
- Distributed File and Compute Data Handling Systems
I’ll repeat a disclaimer I’ve made in the previous articles – I do this in each one because it informs how you should read the series:
This information is not an endorsement or recommendation to use any particular vendor, software or platform; it is an explanation of the factors that influenced my choices. You can choose any other platform, cloud provider or other software that you like – the only requirement is that it fits your needs. As I always say – use what works for you. You can examine the choices I’ve made here, change the decisions to fit your needs and come up with your own system. The choices here are illustrative only, and not meant to sell you on a software package or vendor.
In this article, I’ll explain my choices for working with Key/Value Pair (KVP) systems. I’ll briefly explain the concepts of a KVP system, and then move on to the methods you can use to use and manage them.
Concepts and Rationale
Understanding how to work with Key/Value Pair systems is essential for the data professional. KVP is a way to represent data, but they can also be persisted into a data storage engine. Most often you’ll see them in programming, or a cache, in almost every area of computing.
This brings up some complications in discussing and learning to use one of these systems – they are so “baked-in” to the idea of programming or data science that it’s difficult to locate material dealing specifically with this topic. I’ll explain the basics of Key/Value Pair systems, and then I’ll show you a few options you have for working with data in that format.
Note that I’ll cover in-memory, persisted, and scalable systems. My hope is that as you read this series you learn that there are lots of ways to store data, from flat-file to fully distributed engines, but that all of them have a place. Part of growing in a discipline is realizing that there is no such thing as one answer that solves all problems – there are a lot of options, and it’s important to know what they are so that you can apply them properly.
Concepts
As I mentioned in the last article, a “data base” (database) is nothing more than a set (possibly even an empty set) of data in persisted storage. This is the first concept that breaks with the highly structured systems I’ve explained in the previous articles.
A Key/Value Pair system stores data (either in-memory, on-disk, or in a distributed fashion) using essentially two “columns”: A Key, and the Value for that Key. The Key is just as it sounds – some numeric or textual value that uniquely identifies some data you want.
The Value, depending on which system you’re using, can be numbers, characters, binary data, or more interestingly, objects. The object could be anything from a Microsoft Word document (not just the binary file, the object itself) or even a program. This capability opens up worlds of possibilities.
At the simplest end of the spectrum, consider a text file with the following structure:
- Customer1: “Buck Woody, 123 Here Street, Awesomeville, FL 123456”
- Customer2: “Christina Woody, 234 There Street, AmazingTown, WA 234557”
In this example, I’ve implied a structure. There are the same number of attributes in the Values I’ve created. As you’ll soon see, a KVP opens up mixed structures, even in the same bag of data.
Using anything from the Windows FIND command to sed, grep and awk in Cygwin (see my article on the Text-Based Tools for examples) you can search for a Key and return the line containing the Value for that Key. This simplistic use of a text search is quite limited – the information must be available in text only, and the data has to be read from disk completely into memory. Sorting and working with the data is also difficult.
That isn’t to say that this method of working with Key-Value Pair data isn’t useful. In fact, “INI” files that controlled older versions of Windows operating systems and many of the text-files that control Unix-style programs work this way, and quite effectively. Again, almost any method of working with data is valid in the proper context.
To understand when to work with Key/Value Pair data, my friend Jeremiah Peschka posted a great response to a question on the “StackExchange” web site – I contacted him to allow me to post that response here in its entirety, since it encapsulates the concepts in the examples I’ll show in a moment:
“Others have explained this, but I’m going to take a stab anyway.
A key/value database stores data by a primary key. This lets us uniquely identify a record in a bucket. Since all values are unique, lookups are incredibly fast: it’s always a simple disk seek.
The value is just any kind of value. The way the data is stored is opaque to the database itself. When you store data in a key/value store, the database doesn’t know or care if it’s XML, JSON, text, or an image. In effect, what we’re doing in a key/value store is moving the responsibility for understanding how data is stored out of the database in to the applications that retrieve our data. Since you only have a single range of keys to worry about per bucket, it’s very easy to spread the keys across many servers and use distributed programming techniques to make it possible for this data to be accessed quickly (every server stores a range of data).
A drawback of this approach to data is that searching is a very difficult task. You need to either read every record in your bucket o’ data or else you need to build secondary indexes yourself.
There are a few reasons you might want to use a key/value database:
- When write performance is your highest priority. Mozilla Test Pilot uses a key/value database to rapidly record data.
- When reads are guaranteed to only occur by PK.
- When you are working with a flat data model.
- When you are working with a rich, complex data model that can’t be modeled in an RDBMS.
There are about as many reasons to use a key/value database as there are to using an RDBMS and there are just as many arguments to justify one over the other. It’s important to take a look at how you’re querying your data and understand how that data access pattern guides how you’re going to be inserting and storing data.
Just remember that a key/value database is just one type of NoSQL database.”
References:
- As a great starting point, I recommend you research the writings of Rick Catell (information here: http://www.cattell.net/rick/index.html). He’ll give you a good grounding in those concepts, and in particular check out this article.
- Windows Azure Table storage is also a Key/Value Pair system, and is quite powerful. There’s a complete article on that use-case here: http://msdn.microsoft.com/en-us/magazine/ff796231.aspx
Rationale and Examples
There is no clear agreement for the definition of a Key/Value Pair database. At one end of the spectrum, almost every programming language in existence has capabilities to store data in memory using a Key/Value Pair paradigm. If you save those data to the hard drive, you’ve effectively created a Key/Value Pair database.
A cache, which is a memory service to hold data, can also hold Key/Value Pair data. Some of the more mature cache systems (such as memcachd) are specifically designed for Key calls to retrieve Values, can be distributed across multiple nodes, and can even be “pinned”, or automatically flushed to disk. Many programs use memcached, as an example, to hold data retrieved from a database system. This allows for fast, scalable, in-memory access to data.
But these two types of Key/Value Pair systems (KVP) don’t have an “engine” component that qualifies it as a true database server. In fact, a pure Key/Value Pair database engine is quite difficult to pin down. From various references, you can find everything from Hadoop to Relational Database Systems that are identified as “Key/Value” systems. And if you refer to most of the databases you listed as a KVP, few keep that single moniker – they range from columnar-store systems to many other designations.
So, based on the platform, learning goals, operating system, and several other constraints, I’ve chosen three systems to examine: Python, PowerShell, and Cassandra. Since these range from memory to persisted storage and even engine-based systems, I’ll give the rationale and show examples in-line for each topic.
Python
Almost every programming language has a construct for Key/Value Pair data manipulation. I’ll focus on Python first since it’s widely used in data science, is well documented, available for almost any platform, and if you’re following along in this series, is already installed. Even though I’m focusing on Python here, the concepts hold for almost every language.
Key/Value Pair structures in Python are called a dict, and there are a few ways to create a datum with a dict type.
The first, and probably most direct, is to use the dictionary literal notation: a variable, an equal-sign, a curly brace, a colon, and quotes that contain the value. You can follow that with a comma and repeat the syntax to add more Keys and Values to the dict variable:
|
1 |
Variable = {Key: "Value", AnotherKey: "AnotherValue"}; |
The important thing to note is that the Values don’t have to hold the same structure. If your data is “ragged” or needs to change structure, that’s completely OK. Here’s an example of a customer key, with a corresponding set of data following. Also, in the same dictionary variable, I’ve create a product identifier with a simple description:
|
1 |
Sales = { "Customer1": "Buck Woody, 123 Here Street, AwesomeVille, FL 34677", "Product123": "Superhero Cape" }; |
This might appear strange if you’re used to working with a spreadsheet or a Relational Database Management System (RDBMS). In the case of an RDBMS, you must declare the schema (columns and data types, along with any constraints) before you can add data. And the columns must be the same for every row of data. In a KVP system, you don’t have those constraints – you simply need a Key and then you can add whatever Value you like.
Note that I’ve got text as the Values in this simple example, but other objects work as well.
While this method works, I prefer to use Python functions to create the dictionaries. You can also use other functions on the Values once you reference the Key. Developers make wide use of many different functions, again, not needing a database engine to run server-side code.
In this example I’ll create a dictionary entry using the dict() function. It has this general syntax – Variable name, an equal-sign, the dict() function with the Key, an equal-sign, and the Value, like this:
|
1 |
Variable = dict(Key=Value...); |
In this example I’ll add an even simpler KVP, just a couple of items and the price:
|
1 |
Prices = dict(SHCape=15, SHMask=20); |
No quotes this time – the Keys don’t need them, and the Values in this case are numbers.
At this point I have a couple of KVP dictionaries defined. I can look at the complete list with the print() function:
|
1 |
print(Sales); |
And I can also perform functions on the list, such as getting a count of the items by combining the print() and len() functions:
|
1 |
print(len(Sales)); |
So far, not too difficult. But how do I search for a specific value? In the SQL language, I would use the SELECT statement, but in Python I use the print() function to show the Value by referencing the dictionary name (Sales, in this case) and enclosing the Key in square brackets:
|
1 |
print(Sales["Customer1"]); |
But… can’t I search on the Values themselves? Well, yes, but not easily. We’ll come to that a little later in the series, where it will appear as a weakness and a strength.
I can also use the get() function in Python to return Values. I like this method better since I can return an alternate Value if what I’m looking for does not exist. This example returns the Value I put in earlier:
|
1 |
print(Prices.get('SHCape', 'Not in stock')); |
But this example’s Key doesn’t exist in my dictionary, so it returns the Value of “Not in Stock“:
|
1 |
print(Prices.get('SHUtilityBelt', 'Not in stock')); |
To enter a new Key/Value Pair, I can reference the dictionary, followed by a new Key in square brackets, the = sign, and then the Values I want. Here’s an example that adds a new KVP:
|
1 |
Sales["Customer2"] = "Christina Woody, 234 There Street, AmazingTown, WA 98052"; |
Now I’ll display all of the entries again:
|
1 |
print(Sales); |
Interestingly, the same syntax for updating a Value is the same as the one for inserting a new Value – with an existing Key. Let’s change Christina’s city:
|
1 |
Sales["Customer2"] = "Christina Woody, 234 There Street, Awesomeville, WA 98052"; |
No, I couldn’t change just one attribute, since those don’t exist in a pure KVP. In a few moments I’ll explain how Cassandra gets around this limitation.
Once again, there’s a function you can use, dict.update(), to update data. In fact, there are several functions and methods you can use to copy values, update them, show the Values, compare Values and more. There’s a quick explanation here: tutorialspoint: Python Dictionary and the official, complete reference is here: Python >> 2.7.5 Documentation: Built-in Types.
One final thing on KVP types, in Python and elsewhere: It’s important not to think of a KVP as a “record” – the analogy will only confuse you later on.
References:
The main reference for the operations you can perform on a dict datatype is here: Python >> 2.7.5 Documentation: Mapping Types – dict¶.
PowerShell
PowerShell can also work with Key/Value Pair data. I include it here because of the ubiquity of the platform on the Windows operating system, and the fact that it can work with any .NET construct. That means you could query a SQL Server or Oracle database, Exchange servers, and SharePoint data and store the results as Key/Value Pairs. That data can then drive a program or serve as another variable.
In PowerShell, KVP’s are called “Hashtables”, a term used in other languages as well. It’s simple to make a Hashtable, you simply include the @ symbol, a curly-brace, then the Key, an = sign, the Value, and then a semi-colon symbol to move to the next KVP:
|
1 |
$variablename = @{"Key" = "Value"; ...} |
I’ll recreate the KVP from the Python examples, this time in PowerShell:
|
1 |
$Sales = @{"Customer1" = "Buck Woody, 123 Here Street, AwesomeVille, FL 34677"; "Product123" = "Superhero Cape"} |
Listing the Hashtable is quite simple – type the name of the variable:
|
1 |
$Sales |
Because variables in PowerShell are actually objects, you can use the “dot” notation to perform functions on them. I’ll add that second Key and Value to the Hashtable using the Add() function:
|
1 |
$Sales.Add( "Customer2", "Christina Woody, 234 There Street, AmazingTown, WA 98052") |
And changing her town to AwesomeVille can use the Set_Item() function:
|
1 |
$Sales.Set_Item( "Customer2", "Christina Woody, 234 There Street, AwesomeVille, WA 98052") |
To return a Value for a Key, you can use the Get_Item() function, like this:
|
1 |
$Sales.Get_Item( "Customer2") |
A Hashtable in PowerShell isn’t a single item – it’s a collection. Sorting and other singleton operators won’t work, but you can use the GetEnumerator() function to pipeline the Hashtable to those:
|
1 |
$Sales.GetEnumerator() | Sort-Object Name |
In the articles that follow, I’ll use PowerShell Hashtables as a primary querying method for some interesting use cases.
References:
The main documentation for PowerShell is here: Windows PowerShell User’s Guide. The functions listed work on a Hashtable like almost any other collection.
Cassandra
The Apache Foundation’s Cassandra database product qualifies – by its own admission – as a Key/Value Pair database. From the documentation at: Cassandra Wiki Front Page, I read the following:
“Cassandra is a highly scalable, eventually consistent, distributed, structured key-value store.”
That being said, Cassandra is also a column-store database – which allows for secondary indexes. That’s a valuable addition for any NoSQL offering, because it allows for more flexible, speedy searches, and those attribute updates I mentioned earlier. In fact, Cassandra is a hybrid of KVP and a column-store database.
System Preparation
For some parts of Cassandra to run, I’ll need Java first. If you’re following along with this series, you probably already have it installed, but if not, this link is the place to start: The Java Download page
The installation process tests to ensure Java is installed, but if you’re not sure, just access this link: Verify Java Version
Which should show a success message like so:

Installation and Configuration
You can now build the packages you need to run Cassandra manually (link here: Cassandra installation). You can also use the DataStax installation from here, which bundles things up nicely: Apache Cassandra DataStax Community Edition
Since I’m new to Cassandra, I chose the guided install route from DataStax:
I selected Windows 2008 (32-bit) and the MSI Installer. Once I downloaded it, I opened the installer and selected all the default values, even the selection to auto-start the services – I’ll set those to “manual” later.
I received several messages as the system started up:
And then I got this message:
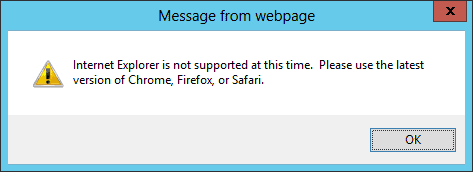
Had I read the documentation properly, I would have noticed that IE is not supported. My choice for an alternate browser is Chrome (Firefox is also supported), so I installed Chrome and accessed the URL for the Ops Center again:
https://localhost:8888/opscenter/index.html
After I examined to ensure the processes are running, I opened the cassandra-cli program to access a command-line for working with the Cassandra server. This is only for testing – normally you’ll use a driver or reference library to work with Cassandra, but I always test my installations to ensure they work before I add complexity.
I won’t take the time here to fully explain the syntax I’m using – but you can find some very good documentation on the Cassandra Query Language (CQL) here: Cassandra Query Language (CQL) v2.0 reference
To test my installation, I’ll just use the reference on getting started with Cassandra. Cassandra Wiki: Getting Started I entered the system, create a “keyspace” (more on that here: Keyspace and table storage configuration ) and then accessed the keyspace:
|
1 2 3 |
create keyspace DEMO with placement_strategy = 'org.apache.cassandra.locator.SimpleStrategy' and strategy_options = {replication_factor:1}; |
And then accessed that keyspace:
|
1 |
use DEMO; |
From there I’m able to create a table, or more accurately, a column family (more on that here: Creating a table):
|
1 2 3 4 |
create column family Users with key_validation_class = 'UTF8Type' and comparator = 'UTF8Type' and default_validation_class = 'UTF8Type'; |
Now I can enter data with the set command:
|
1 2 |
set Users[1234][name] = scott; set Users[1234][password] = tiger; |
And finally a simple read operation:
|
1 |
get Users[1234]; |
And I get the data back that I inserted. These are only the simplest of commands, and a more complete explanation is in the References section below.
Finally, I’ve located the Services from DataStax to set the startup to Manual. For this system, I set everything to manual and then start them up when I need them. I do that with a PowerShell script as I described in the last article.
References:
- If you’d like a quicker overview to share with others, this article works well: An Overview of Cassandra.
- The best documentation I’ve found so far is the DataStax manual: An overview of Cassandra’s structure.
Load comments