The SQL Server Query Optimizer needs to estimate the number of rows that are processed for each physical operator in a query plan. These row estimates are referred to as cardinality estimates and are required in order to then calculate the cost models of the query plan operators. If these cardinality estimates are inaccurate, the Query Optimizer is less likely to choose the most appropriate execution plan for the query, and so the performance of the query’s execution is likely to be slower.
There are a variety of reasons for a poor cardinality estimate, and this article will focus on just one of the more complex reasons, affecting the “gatekeeper row” cardinality estimate.
Gatekeeper Row Scenario
We will illustrate this by using a query executed against the AdventureWorksDW2012 database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT [od].[CalendarYear] , [p].[ProductLine] , SUM([fis].[SalesAmount]) AS [SalesAMT] FROM [dbo].[FactInternetSales] AS [fis] INNER JOIN [dbo].[DimProduct] AS [p] ON [fis].[ProductKey] = [p].[ProductKey] INNER JOIN [dbo].[DimCurrency] AS [c] ON [fis].[CurrencyKey] = [c].[currencykey] INNER JOIN [dbo].[DimDate] AS [od] ON [fis].[OrderDateKey] = [od].[DateKey] WHERE [c].[CurrencyName] = N'United Kingdom Pound' GROUP BY [od].[CalendarYear] , [p].[ProductLine] ORDER BY [od].[CalendarYear] , [p].[ProductLine]; GO |
The query references one fact table and three separate dimension tables. The abridged relationship diagram is below (click for full size):
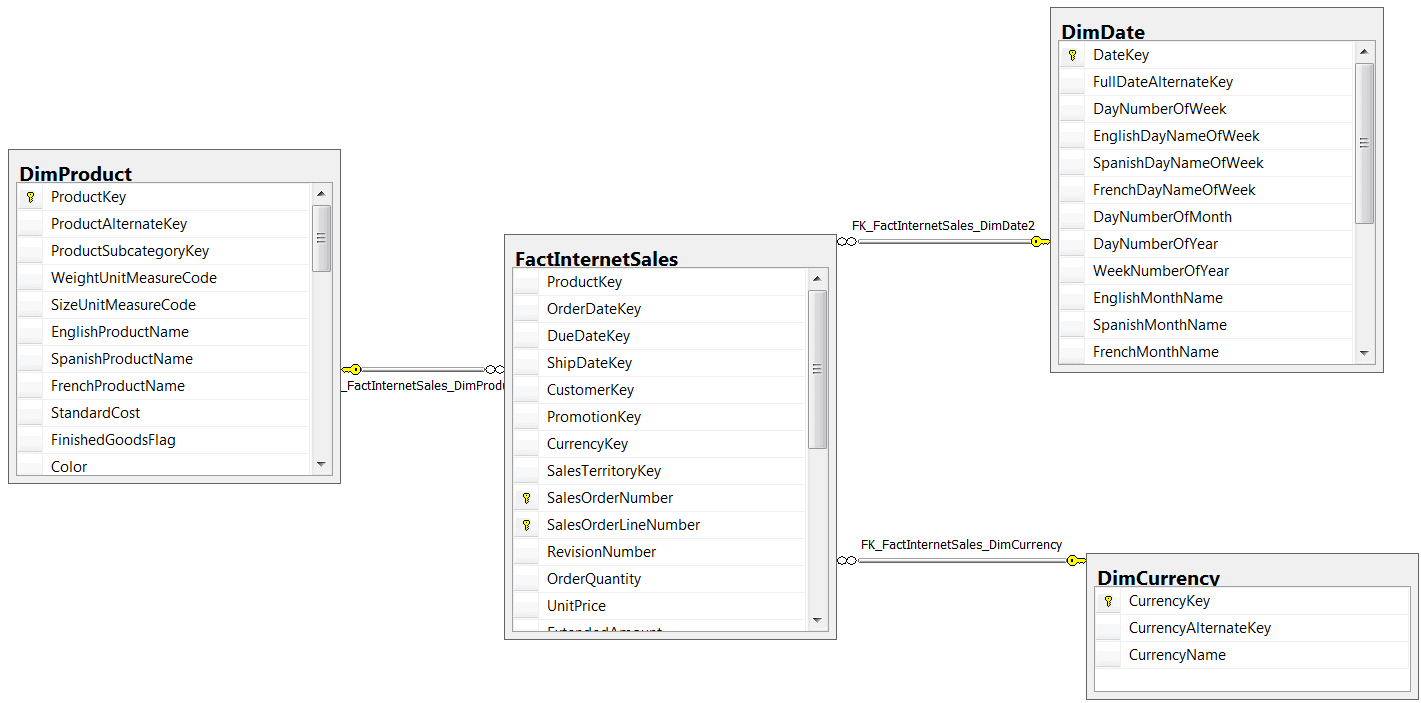
What kind of cardinality estimates do we see and how do they compare to the actual rows? For this article, I was using SQL Server 2012 version 11.0.2316 and I saw the following estimated and actual row counts:
|
Rows |
Estimated Rows |
StmtText |
|
12 |
22.17362 |
|–Sort(ORDER BY:([od].[CalendarYear] ASC, [p].[ProductLine] ASC)) |
|
12 |
22.17362 |
|–Hash Match(Aggregate, HASH:([od].[CalendarYear], |
|
6740 |
7936.583 |
|–Hash Match(Inner Join, |
|
606 |
606 |
|–Clustered Index |
|
6740 |
8466.041 |
|–Hash Match(Inner Join, |
|
2191 |
2191 |
|–Clustered Index |
|
6740 |
10066.33 |
|–Hash Match(Inner Join, |
|
1 |
1 |
|–Clustered Index |
|
60398 |
60398 |
|–Clustered Index |
The clustered index scan of FactInternetSales shows that the estimated rows are equal to actual rows. This represents the total row count from that table, which was 60,398 rows. The estimated and actual row counts are also identical for the clustered index scan of the DimCurrency table, which makes sense given the “United Kingdom Pound” search condition for the CurrencyName column.
The DimCurrency has 105 rows in it. But that doesn’t mean that FactInternetSales has rows for every possible CurrencyKey. In reality, the FactInternetSales has the following distribution of rows by currency, as we can determine by using this query:
|
1 2 3 4 5 6 7 8 |
SELECT [c].[CurrencyName], COUNT(*) AS [RowCount] FROM [dbo].[FactInternetSales] AS [fis] INNER JOIN [dbo].[DimCurrency] AS [c] ON [fis].[CurrencyKey] = [c].[currencykey] GROUP BY [c].[CurrencyName] ORDER BY [c].[CurrencyName]; GO |
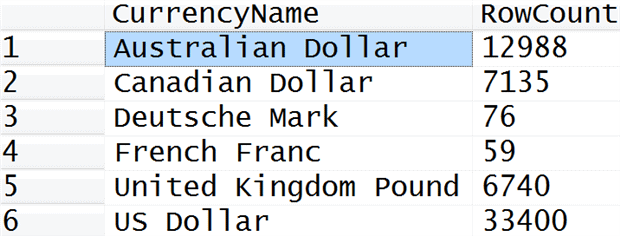
As you can see, most currencies are not represented in FactInternetSales.
Given this, what happens if we change the previous query to reference a currency that has no associated rows? For example, switching to the Pakistan Rupee currency?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT [od].[CalendarYear] , [p].[ProductLine] , SUM([fis].[SalesAmount]) AS [SalesAMT] FROM [dbo].[FactInternetSales] AS [fis] INNER JOIN [dbo].[DimProduct] AS [p] ON [fis].[ProductKey] = [p].[ProductKey] INNER JOIN [dbo].[DimCurrency] AS [c] ON [fis].[CurrencyKey] = [c].[currencykey] INNER JOIN [dbo].[DimDate] AS [od] ON [fis].[OrderDateKey] = [od].[DateKey] WHERE [c].[CurrencyName] = N'Pakistan Rupee' GROUP BY [od].[CalendarYear] , [p].[ProductLine] ORDER BY [od].[CalendarYear] , [p].[ProductLine]; GO |
The cardinality estimates versus actual now appear as follows:
|
Rows |
Estimated Rows |
StmtText |
|
0 |
22.17362 |
|–Sort(ORDER BY:([od].[CalendarYear] ASC, [p].[ProductLine] ASC)) |
|
0 |
22.17362 |
|–Hash Match(Aggregate, HASH:([od].[CalendarYear], |
|
0 |
7936.583 |
|–Hash Match(Inner Join, |
|
606 |
606 |
|–Clustered Index |
|
0 |
8466.041 |
|–Hash Match(Inner Join, |
|
2191 |
2191 |
|–Clustered Index |
|
0 |
10066.33 |
|–Hash Match(Inner Join, |
|
1 |
1 |
|–Clustered Index |
|
60398 |
60398 |
|–Clustered Index |
As with the original query, the clustered index scan of FactInternetSales shows that the estimated rows are equal to the actual rows. This represents the total row count from that table, which was 60,398 rows. The estimated and actual row counts are also identical for the clustered index scan of the DimCurrency table, showing a value of “1” representing the search on Pakistan Rupee in the CurrencyName column.
What about the Hash Match operation between the two tables? Our previous example had 10,066 (estimated) versus 6,740 (actual). But with our new query using a currency that does not exist in the fact table, our estimate is still 10,066 and actual number of rows this time is 0.
So a gatekeeper row, in this context, represents a dimension row that will let several fact table rows through to the parent operators when selected via the presence or absence of a search condition. When the gatekeeper dimension row is not present, the fact table rows are ultimately not passed through to the final result set, but yet the cardinality estimate issue remains.
I can exacerbate the problem with this cardinality estimate by modifying all the rows in the fact table to the same currency, the Yen in our case, with this simple statement (and if you’re trying this out yourself, be sure to back up your AdventureWorksDW2012 database beforehand so you can revert back afterwards):
|
1 2 3 4 |
-- Setting all Fact table rows to the Yen currency UPDATE [dbo].[FactInternetSales] SET [CurrencyKey] = 102; GO |
Once I have done this and we now have only Yen, I see the following estimated rows vs. actual rows if I execute the previous query that references the Pakistan Rupee.
|
Rows |
Estimated Rows |
StmtText |
|
0 |
22.04758 |
|–Stream Aggregate(GROUP BY:([od].[CalendarYear], |
|
0 |
23.5184 |
|–Sort(ORDER BY:([od].[CalendarYear] ASC, [p].[ProductLine] |
|
0 |
23.5184 |
|–Nested Loops(Inner Join, OUTER |
|
12 |
88.19033 |
|–Hash Match(Aggregate, HASH:([fis].[CurrencyKey], |
|
60398 |
47348.81 |
| |–Hash |
|
606 |
606 |
| |–Clustered Index |
|
60398 |
50507.5 |
| |–Hash Match(Inner Join, |
|
2191 |
2191 |
| |–Clustered Index |
|
60398 |
60398 |
| |–Clustered Index |
|
0 |
1 |
|–Clustered Index |
This time the Query Optimizer re-arranged the order in which the tables were joined. This new plan started with a hash join between DimDate and FactInternetSales, followed by a hash join to DimProduct, and then finally a nested loop join to DimCurrency. The estimated row count of the nested loop operation is 24 vs. the actual 0 row count. So we see that we are not filtering out the FactInternetSales rows early in the plan, even though no rows are ultimately returned.
Increasing the Scale of the Problem
Why is all of this important? It is because, with a real relational data warehouse database of any scale, the performance will be noticeable impacted. The problem is that the Query Optimizer isn’t aware that there are zero qualifying rows in the Fact table. The query plan generates unnecessary reads in the leaf level of the execution plan and then passes the pre-filtered rows to the intermediate levels of the plan tree and is not filtered down until later steps. Our current database is small, but the consequences of these cardinality estimate issues become more pronounced with larger tables.
To demonstrate the impact at a larger scale, I’m going to increase the size of the FactInternetSales table to 3,865,472 rows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
-- Increase size of table to 3,865,472 rows INSERT [dbo].[FactInternetSales] ( [ProductKey] , [OrderDateKey] , [DueDateKey] , [ShipDateKey] , [CustomerKey] , [PromotionKey] , [CurrencyKey] , [SalesTerritoryKey] , [SalesOrderNumber] , [SalesOrderLineNumber] , [RevisionNumber] , [OrderQuantity] , [UnitPrice] , [ExtendedAmount] , [UnitPriceDiscountPct] , [DiscountAmount] , [ProductStandardCost] , [TotalProductCost] , [SalesAmount] , [TaxAmt] , [Freight] , [CarrierTrackingNumber] , [CustomerPONumber] , [OrderDate] , [DueDate] , [ShipDate] ) SELECT [FactInternetSales].[ProductKey] , [FactInternetSales].[OrderDateKey] , [FactInternetSales].[DueDateKey] , [FactInternetSales].[ShipDateKey] , [FactInternetSales].[CustomerKey] , [FactInternetSales].[PromotionKey] , [FactInternetSales].[CurrencyKey] , [FactInternetSales].[SalesTerritoryKey] , LEFT(CAST(NEWID() AS NVARCHAR(36)), 20) , [FactInternetSales].[SalesOrderLineNumber] , [FactInternetSales].[RevisionNumber] , [FactInternetSales].[OrderQuantity] , [FactInternetSales].[UnitPrice] , [FactInternetSales].[ExtendedAmount] , [FactInternetSales].[UnitPriceDiscountPct] , [FactInternetSales].[DiscountAmount] , [FactInternetSales].[ProductStandardCost] , [FactInternetSales].[TotalProductCost] , [FactInternetSales].[SalesAmount] , [FactInternetSales].[TaxAmt] , [FactInternetSales].[Freight] , [FactInternetSales].[CarrierTrackingNumber] , [FactInternetSales].[CustomerPONumber] , [FactInternetSales].[OrderDate] , [FactInternetSales].[DueDate] , [FactInternetSales].[ShipDate] FROM [dbo].[FactInternetSales]; GO 6 -- Executes this INSERT 6 separate times |
I’ve inflated the size based on the modified data which had all rows associated with just one currency key. My gatekeeper dimension row is CurrencyKey = 102. If I reference this specific key, then millions of fact table rows will need to be accessed, whereas any other value of CurrencyKey, assuming equality search conditions, will cause no rows to be returned from the Fact table.
Re-executing the query that referenced the Pakistan Rupee, the following plan is generated (show via SQL Server Plan Explorer – click for full size):

The first observation is that the plan is now executed with parallel operations. This is an artifact of the increase in the number of fact table rows and associated cost.
The second observation is that millions of rows are flowing through the plan tree and only narrowing down until it is roughly 2/3rds through the plan. The associated estimated vs. actual row counts continue to be skewed and the Query Optimizer doesn’t know that all rows in FactInternetSales only have one CurrencyKey value. The DimCurrency table is not evaluated until very late in the plan:
|
Rows |
Estimate Rows |
StmtText |
|
0 |
21.11082 |
|–Stream Aggregate(GROUP BY:([od].[CalendarYear], |
|
0 |
22.51457 |
|–Parallelism(Gather Streams, ORDER BY:([od].[CalendarYear] |
|
0 |
22.51457 |
|–Nested Loops(Inner Join, OUTER |
|
12 |
84.44327 |
|–Sort(ORDER BY:([od].[CalendarYear] ASC, [p].[ProductLine] |
|
12 |
84.44327 |
| |–Hash Match(Aggregate, HASH:([fis].[CurrencyKey], |
|
3865472 |
2900982 |
| |–Parallelism(Repartition Streams, Hash Partitioning, |
|
3865472 |
2900982 |
| |–Hash Match(Inner Join, |
|
606 |
606 |
| |–Bitmap(HASH:([p].[ProductKey]), |
|
606 |
606 |
| | |–Parallelism(Repartition Streams, |
|
606 |
606 |
| | |–Clustered Index |
|
3865472 |
2900982 |
| |–Parallelism(Repartition Streams, Hash Partitioning, |
|
3865472 |
2900982 |
| |–Hash Match(Inner Join, |
|
2191 |
2191 |
| |–Bitmap(HASH:([od].[DateKey]), |
|
2191 |
2191 |
| | |–Parallelism(Repartition Streams, Hash Partitioning, |
|
2191 |
2191 |
| | |–Clustered Index |
|
3865472 |
2900982 |
| |–Parallelism(Repartition Streams, Hash Partitioning, |
|
3865472 |
3865472 |
| |–Clustered Index |
|
0 |
1 |
|–Clustered Index |
Why Care?
So what are the consequences of this? There are a few reasons that stand out for the problem that I’ve illustrated:
- Inflated query execution memory grants
- Reduced concurrency due to inflated query execution memory grants
- Excessive read I/O from reading rows that aren’t actually required
- Buffer pool pressure (potentially) from all the data file pages being read from disk
If you look at the Showplan XML of the previously executed query, there are additional details of the memory grant requirements:
|
1 2 3 4 5 6 7 8 9 |
<MemoryGrantInfo SerialRequiredMemory="3072" SerialDesiredMemory="9464" RequiredMemory="30400" DesiredMemory="36800" RequestedMemory="36800" GrantWaitTime="0" GrantedMemory="36800" MaxUsedMemory="12816"/> |
This runtime memory grant information was introduced in SQL Server 2012. The serial plan memory attributes SerialRequiredMemory and SerialDesiredMemory refer to non-parallel plans. The other attributes refer to the query in its current execution state, which in this case used parallel operations.
The requested and actual memory was 36,800 KB. And what if multiple concurrent requests were attempting to execute queries with similar cardinality estimate issues? At a certain point, you may end up seeing waits for memory grants. Cardinality estimate issues can cause the requested query execution memory grant to be significantly inflated. If concurrency is important, bad cardinality estimates can hamper your overall workload throughput.
Problems with cardinality estimates can also produce excessive read I/O requests. For example, dropping all clean buffers (in a non-production environment, of course) prior to executing the previous query shows that more than 165,061 pages got loaded into the buffer pool – even though no rows were ultimately returned in my query:
|
1 2 3 4 5 6 7 8 |
-- Not for production use DBCC DROPCLEANBUFFERS; GO -- Execute the query here SELECT COUNT(*) AS [BufferCount] FROM sys.[dm_os_buffer_descriptors]; |
Executing SET STATISTICS IO ON also shows the overall I/O impact of the query (abridged results):
|
1 |
Table 'FactInternetSales'. Scan count 9, logical reads 167112, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
And I’m not even mentioning the CPU overhead that is so tightly associated with I/O operations. As you can see, when estimates are off, it impacts query performance, resource utilization, and concurrency.
Solutions
Cardinality estimate issues can occur for a variety of different reasons and so there are a variety of different solutions which include, amongst others:
- updating statistics
- changing statistics-related database settings
- disabling “norecompute” on indexes and statistics
- adding multi-column statistics for correlated columns
The problem with the gatekeeper row cardinality estimate is particularly interesting because the standard solutions aren’t usually helpful.
One way to approach this problem is to help the Query Optimizer understand more explicitly the cardinality of the gatekeeper column in the fact table itself, without relying on the byproduct of the Fact-to-Dimension join operation. For example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- CurrencyKey 75 = Pakistan Rupee SELECT [od].[CalendarYear] , [p].[ProductLine] , SUM([fis].[SalesAmount]) AS [SalesAMT] FROM [dbo].[FactInternetSales] AS [fis] INNER JOIN [dbo].[DimProduct] AS [p] ON [fis].[ProductKey] = [p].[ProductKey] INNER JOIN [dbo].[DimDate] AS [od] ON [fis].[OrderDateKey] = [od].[DateKey] WHERE [fis].[CurrencyKey] = 75 GROUP BY [od].[CalendarYear] , [p].[ProductLine] ORDER BY [od].[CalendarYear] , [p].[ProductLine]; GO |
I removed the INNER JOIN to DimCurrency and instead directly referenced a search condition for the fact table CurrencyKey. Given this direct predicate on the foreign key reference, the query execution plan shape changed significantly (click for larger version):
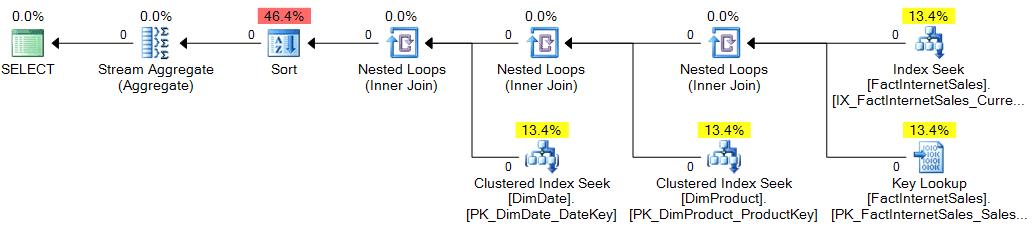
The estimated vs. actual row skew was also eliminated (remember that the estimates feed the cost model, so the plan is directly impacted by good or bad estimates) and large sets of rows were no longer being propagated up the tree:

If you are using a stored procedure to encapsulate the query, you could choose to pass the parameter in for direct use in the fact table predicate:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE PROCEDURE [dbo].[ProductLineSales_by_CalendarYear] @CurrencyKey INT AS SELECT [od].[CalendarYear] , [p].[ProductLine] , SUM([fis].[SalesAmount]) AS [SalesAMT] FROM [dbo].[FactInternetSales] AS [fis] INNER JOIN [dbo].[DimProduct] AS [p] ON [fis].[ProductKey] = [p].[ProductKey] INNER JOIN [dbo].[DimDate] AS [od] ON [fis].[OrderDateKey] = [od].[DateKey] WHERE [fis].[CurrencyKey] = @CurrencyKey GROUP BY [od].[CalendarYear] , [p].[ProductLine] ORDER BY [od].[CalendarYear] , [p].[ProductLine]; GO |
However, you do need to be extremely careful about parameter sniffing in this case. For example, if I execute the non-gatekeeper row parameter first (initial compilation) followed by a gatekeeper row parameter, the non-gatekeeper plan gets used for consecutive executions, resulting in greatly diminished performance, and tempdb spills on the sort operator:
|
1 2 3 4 5 6 7 |
-- Pakistan Rupee currency EXECUTE [dbo].[ProductLineSales_by_CalendarYear] 75; GO -- Yen currency EXECUTE [dbo].[ProductLineSales_by_CalendarYear] 102; GO |

Also, a sub-query providing the CurrencyKey does not achieve the same results as when I directly provided the literal value. The following query uses the non-optimal plan that had the original cardinality estimate issues:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT [od].[CalendarYear] , [p].[ProductLine] , SUM([fis].[SalesAmount]) AS [SalesAMT] FROM [dbo].[FactInternetSales] AS [fis] INNER JOIN [dbo].[DimProduct] AS [p] ON [fis].[ProductKey] = [p].[ProductKey] INNER JOIN [dbo].[DimDate] AS [od] ON [fis].[OrderDateKey] = [od].[DateKey] WHERE [fis].[CurrencyKey] = (SELECT [CurrencyKey] FROM [dbo].[DimCurrency] WHERE [CurrencyName] = N'Pakistan Rupee') GROUP BY [od].[CalendarYear] , [p].[ProductLine] ORDER BY [od].[CalendarYear] , [p].[ProductLine]; GO |
Another solution to consider is the use of a covering nonclustered index along with an INDEX and/or FORCESEEK hint. By default I’m not a fan of using hints but, when tackling a problem with the gatekeeper row cardinality estimate, it may be one of the few options available to you.
In the following example, I create a covering index on the columns referenced for join conditions and an INCLUDE column for my sales amount:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX IX_FIS_CurrencyKey_ProductKey_DateKey ON [dbo].[FactInternetSales]([CurrencyKey], [ProductKey], [OrderDateKey]) INCLUDE ([SalesAmount]); GO |
Adding this index will not, by itself, solve the problem. In my testing, the Query Optimizer still chose to perform a large scan of the Fact table. But adding the covering index in conjunction with a FORCESEEK hint was effective:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
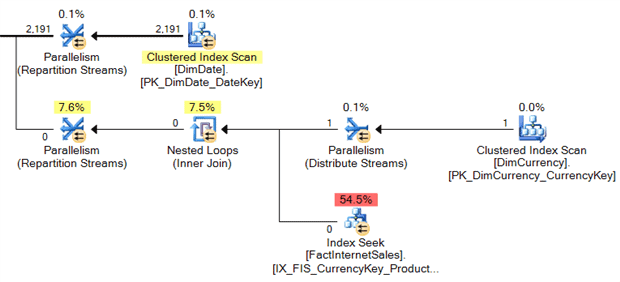
SELECT [od].[CalendarYear] , [p].[ProductLine] , SUM([fis].[SalesAmount]) AS [SalesAMT] FROM [dbo].[FactInternetSales] AS [fis] WITH (FORCESEEK) INNER JOIN [dbo].[DimProduct] AS [p] ON [fis].[ProductKey] = [p].[ProductKey] INNER JOIN [dbo].[DimCurrency] AS [c] ON [fis].[CurrencyKey] = [c].[currencykey] INNER JOIN [dbo].[DimDate] AS [od] ON [fis].[OrderDateKey] = [od].[DateKey] WHERE [c].[CurrencyName] = N'Pakistan Rupee' GROUP BY [od].[CalendarYear] , [p].[ProductLine] ORDER BY [od].[CalendarYear] , [p].[ProductLine]; GO |
The Query Optimizer chose to join the DimCurrency and FactInternetSales tables first and the cardinality estimates were accurate (abridged query plan below):
Another potential solution to consider if you’re running on SQL Server 2012 Enterprise Edition is columnstore indexes. While using columnstore indexing doesn’t fix the cardinality estimate issues, it is able to side-step them in some scenarios due to leveraging columnar storage in combination with batch-execution mode processing:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
-- Drop nonclustered index in order to eliminate QO tempting choices DROP INDEX IX_FIS_CurrencyKey_ProductKey_DateKey ON [dbo].[FactInternetSales]; GO -- Covering all supported data type columns CREATE NONCLUSTERED COLUMNSTORE INDEX [NCI_CSI_FactInternetSales] ON [dbo].[FactInternetSales] ( [ProductKey], [OrderDateKey], [DueDateKey], [ShipDateKey], [CustomerKey], [PromotionKey], [CurrencyKey], [SalesTerritoryKey], [SalesOrderNumber], [SalesOrderLineNumber], [RevisionNumber], [OrderQuantity], [UnitPrice], [ExtendedAmount], [UnitPriceDiscountPct], [DiscountAmount], [ProductStandardCost], [TotalProductCost], [SalesAmount], [TaxAmt], [Freight], [CarrierTrackingNumber], [CustomerPONumber], [OrderDate], [DueDate], [ShipDate] )WITH (DROP_EXISTING = OFF) GO |
If you execute the original, problematic query using the non-gatekeeper row, a plan is selected that now leverages the columnstore index and results in a fast execution (abridged query plan – click to enlarge):
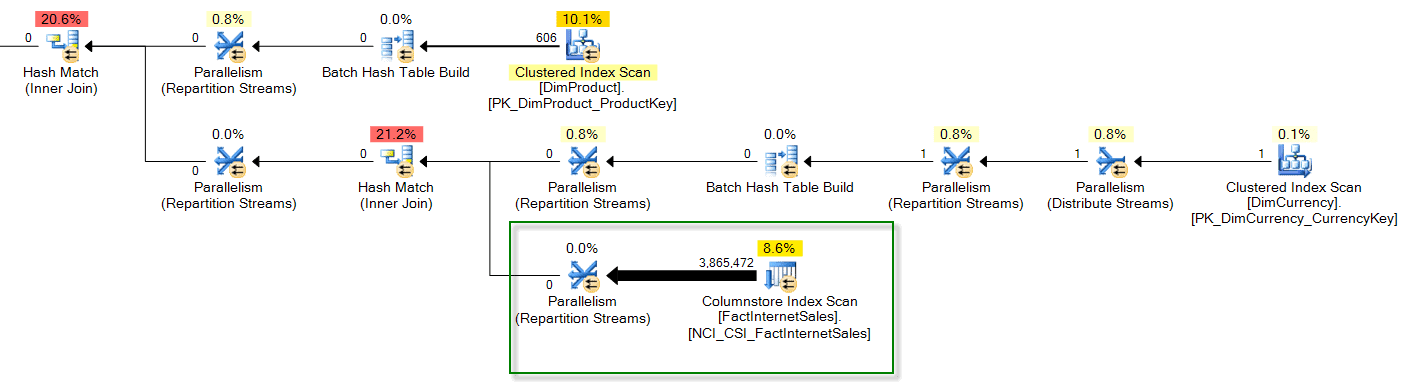
Notice that the 3,865,472 rows associated with the columnstore index scan are quickly narrowed down in the parent operator, even though the cardinality estimate for the scan and parent repartition-stream operator are significantly skewed compared to the actual row count:
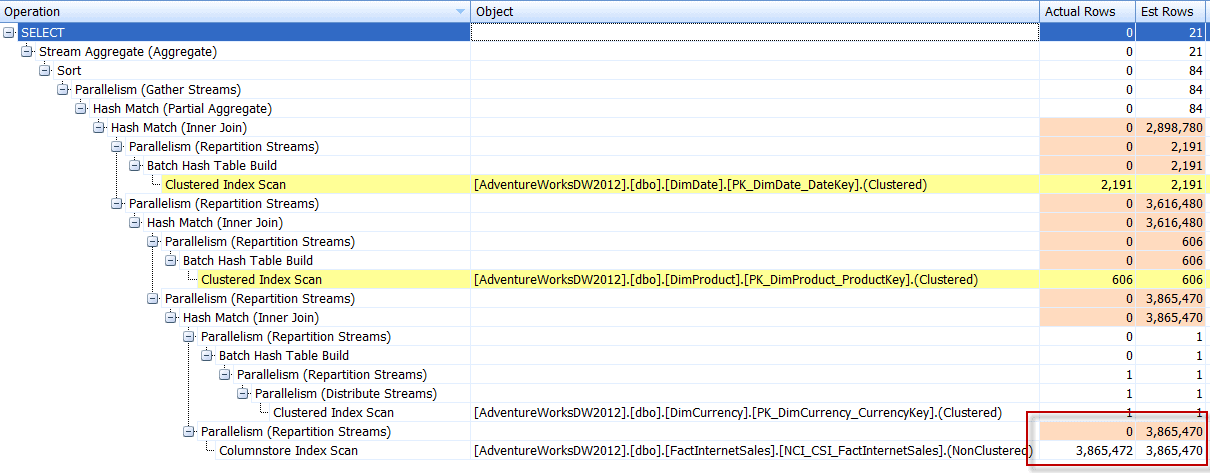
Even though we didn’t eliminate the cardinality estimate issues, the plan had far less I/O impact, and thus far less buffer pool impact. The memory grant requests, however, actually increase in size:
|
1 2 3 4 5 6 7 8 9 |
<MemoryGrantInfo SerialRequiredMemory="7680" SerialDesiredMemory="13264" RequiredMemory="66448" DesiredMemory="72080" RequestedMemory="72080" GrantWaitTime="0" GrantedMemory="72080" MaxUsedMemory="8776"/> |
While columnstore indexing comes with significant potential performance benefits, there are trade-offs, such as making your table read-only for non-partition switch related data modifications. Not all queries can benefit from columnstore indexing, but if your gatekeeper-row issue is associated with a standard, relational data-warehouse query, you may want to consider exploring this option. You may find that a columnstore index solution requires far less refactoring of your queries and associated schema than other potential solutions.
Summary
Gatekeeper-row cardinality estimation issues can be difficult to spot because they are driven by the changing characteristics of your relational data warehouse. Look for actual and estimated row skews across operators in a star-schema query. If that skew is associated with a dimension row that significantly influences the rows that are returned from the fact table, you may need to refactor your queries in order to help the Query Optimizer to properly estimate cardinality. Other potential solutions include the use of a covering nonclustered index with indexing hints, and also the use of a columnstore index which, while not resolving the cardinality estimate issue, may compensate by virtue of the performance optimizations that are inherent to its architecture.

Load comments