

Fair warning, this is a discussion piece. I had a task, I went through several possibilities and I’m going to share each of them and the results of those I tried. I will not be giving any specific examples or code. Feel free to give me your opinion in the comments below.
I was asked to alter a column from CHAR(2) to CHAR(4). You might not think that would be a big deal but it ended up being a big pain. To start with here are a few facts.
- The table has 1.4 billion rows.
- The table takes up 750 GB.
- The database has multiple filegroups each with multiple files. Total size a bit over 2 TB.
- The main drive the database is on is already 2 TB in size (I’m told this is the limit for our drives but I don’t know if that’s a political or technical limit). There was 300 GB free.
- The log when I started was 50 GB with the max size also set to 50 GB.
- The database is in SIMPLE recovery mode so no need to take log backups during the change to manage log size. I only have to worry about the log size of the largest single transaction.
- This is a test environment so I can play a bit, but I’m planning for the production change.
- I can get more disk space by requesting a new disk but I want to avoid the paperwork and complications of moving some of the files to the new location.
My first attempt was just a straight ALTER TABLE ALTER COLUMN. After about an hour I got back a log full error. I then tried a 200 GB log and a 350 GB log. These failed at 3 and 5 hours. While this was going on I checked on #sqlhelp to see if anyone knew any way to minimize the log useage so my command would finish.
The primary suggestions were:
- Add a new column to the end of the table, populate it in batches, then remove the old column.
- Create a new table, populate it, index it, drop the old table, re-name the new table.
Here were my thoughts on the first suggestion, adding a new column.
- This should work because adding the new column is a schema change only so it will be almost instant and take no extra space.
- Once I start putting data into the column it will actually add space to the row, potentially causing page splits.
- I can fill the new column in small/medium sized batches so that each batch goes fairly quickly and doesn’t use too much log space.
- The fatal flaw with this plan (at least for me) is that this is vendor/legacy code. I can’t be certain I won’t break something by moving the column. If everything is properly coded I shouldn’t, but I can almost guarantee that not everything is.
So how about the next suggestion, adding a new table and copying the data over.
- I discounted this almost immediately because this would require at least at some point two copies of my 750 GB table. I’m trying to minimize my space usage .. not increase it.
- There are no problems with the log however. I can use a minimally logged operation or load the new table a bit at a time and avoid overloading the log.
- I need to make sure to script out everything from the original table (indexes, constraints and easiest to forget, permissions).
Well that leaves me right back where I started. Maybe extend my log to another drive temporarily and just let the log grow as large as it needs to then clean up afterwards.
Then I started looking at the table a bit closer. It turns out that ~400 GB of the space used by the table are indexes (no comments please, I didn’t design it). And that one fact was enough to give me my solution.
A variation on the second suggestion. Drop all of the indexes, create my new table, copy data, rename and re-create the indexes.
My initial attempt to copy the data was using an SSIS package (import wizard). It took aprox. 10 hours.
Next I looked at The Data Loading Performance Guide. Unfortunately even using an INSERT INTO SELECT with TF 610 into an empty table I wasn’t able to get it minimally logged. I’m still working on it but ran out of time before the production move.
In the end I did this:
- I changed the column size in the table designer. I did NOT save.
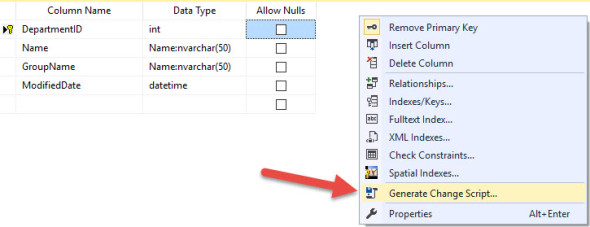
- I generated a script using the Generate Scripts option of the table designer.

Right click in the white space and select Generate Change Script
This gives me a script that drops & re-creates constraints. Creates the new table, does the re-name swap, creates the new indexes, creates new permissions etc.
- Next I modified the script to drop all but the clustered index from the old table and commented out the part that moved the data from the old table to the new. I also modified the new table to include the clustered index.
- I used the first part of the script to create the new table and with the clustered index.
- I used the import/export wizard to copy the data from one table to the other. An INSERT INTO SELECT (minimally logged) would probably have been faster but I couldn’t get that to work.
- I ran the remainder of the script (dropping the old table, renaming the new one, creating constraints, permissions etc.) except for the new indexes.
- Finally I created the indexes in parallel (three wide). There were 7 indexes and they took about 1.5 hours each to create. So all told the indexes took about 4.5 hours to create.
Again this is just meant to be a discussion of what I did and how I got there. Feel free to give your own opinions in the comments.
Filed under: Microsoft SQL Server, Performance, Problem Resolution, SQLServerPedia Syndication Tagged: microsoft sql server, Performance, problem resolution 






![]()
