

I’ve been exploring how natively compiled procedures are portrayed within execution plans. There have been two previous posts on the topic, the first discussing the differences in the first operator, the second discussing the differences everywhere else. Now, I’m really interested in generating bad execution plans. But, the interesting thing, I wasn’t able to, or, rather, I couldn’t see evidence of plans changing based on silly things I did to my queries and data. To start with, here’s a query:
CREATE PROC [dbo].[AddressDetails] @City NVARCHAR(30)
WITH NATIVE_COMPILATION,
SCHEMABINDING,
EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
SELECT a.AddressLine1,
a.City,
a.PostalCode,
sp.Name AS StateProvinceName,
cr.Name AS CountryName
FROM dbo.Address AS a
JOIN dbo.StateProvince AS sp
ON sp.StateProvinceID = a.StateProvinceID
JOIN dbo.CountryRegion AS cr
ON cr.CountryRegionCode = sp.CountryRegionCode
WHERE a.City = @City;
END
GOAnd this is a nearly identical query, but with some stupid stuff put in:
CREATE PROC [dbo].[BadAddressDetails] @City VARCHAR(30)
WITH NATIVE_COMPILATION,
SCHEMABINDING,
EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
SELECT a.AddressLine1,
a.City,
a.PostalCode,
sp.Name AS StateProvinceName,
cr.Name AS CountryName
FROM dbo.Address AS a
JOIN dbo.StateProvince AS sp
ON sp.StateProvinceID = a.StateProvinceID
JOIN dbo.CountryRegion AS cr
ON cr.CountryRegionCode = sp.CountryRegionCode
WHERE a.City = @City;
END
GOI’ve change the primary filter parameter value to a VARCHAR when the data is NVARCHAR. This difference is likely to lead to differences in an execution plan, although not necessarily. If I load my tables up and update my statistics, then create the procedures and run them both with the same parameter values, I should detect any differences, right? Here’s the resulting execution plan:
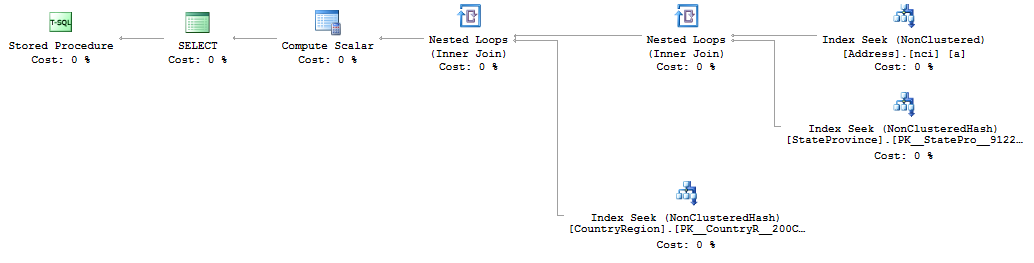
It’s an identical plan for both queries. In fact, the only difference in the plan that I can find is a CAST in the Index Seek operator for the BadAddressDetails procedure, as expected. But, it didn’t prevent the plan… the plan, from showing any other difference. However, execution is something else entirely. And this is where things get a little strange. There are two ways to execute a procedure:
EXEC dbo.AddressDetails @City = 'London'; EXEC dbo.AddressDetails 'London';
Interestingly enough, the first one is considered to be the slow way of passing a parameter. The second one is the preferred mechanism for natively compiled procedures. Now, if I execute these two versions of calling the procedure, I actually see different performance. The first call, the slow one, will run, somewhere in the neighborhood of 342 µs. The other ran in about 255 µs. Granted, we’re only talking about ~100 µs, but we’re also talking a 25% speed increase, and that’s HUGE! But that’s not the weird bit. The weird bit was that when I ran the good and bad queries together, the slow call on the bad query was consistently faster than the slow call on the good query. The fast call reversed that trend. And, speaking of which, the bad query, with the CAST ran in about 356 µs or ~25% slower.
The execution plan really didn’t show any indication that this would be slower, which made me do the next thing I did. I updated my Address table so that all the values were equal to ‘London.’ Then, because statistics are not maintained on in-memory tables automatically, I updated the statistics:
UPDATE STATISTICS dbo.Address WITH FULLSCAN, NORECOMPUTE;
With the statistics up to date, I dropped and recreated the procedure (there is no recompile with natively compiled procedures, something to keep in mind… maybe, more in a second). So now, the selectivity on the index was 1. The most likely outcome, an index scan. Guess what happened? Nothing. The execution plan was the same. I then went nuts, I converted all my tables so that a horrific mishmash of data would be brought back instead of clean data sets and I put data conversions in and… nothing. Index Seeks and Nested Loops joins. Weirdness.
I’m actually unsure why this is happening. I’m going to do more experimenting with it to try to figure out what’s up. But, that lack of recompile, maybe it doesn’t matter if, regardless of data distribution, you’re going to get the same plan anyway. I’m really not positive that looking at the execution plan for natively compiled procedures does much of anything right now. However, these tests were a little bit subtle. I’ll load up more data, get a more complex query and then really mess around with the code to see what happens. I’ll post more of my experiments soon.
I promise not to experiment on you though when I’m teaching my all day query tuning seminars. There are a bunch coming up, so if you’re interested in learning more, here’s where to go. Just a couple of days left before Louisville and I’m not sure if there’s room or not, but it’s happening on the 20th of June. Go here to register. Albany will be on July 25th, but we’re almost full there as well. You can register here. SQL Connections is a pretty cool event that takes place in September in Las Vegas. In addition to regular sessions I’ll be presenting an all-day session on query tuning on the Friday of the event. Go here to register for this great event. In Belgium in October, I’ll be doing an all day session on execution plans at SQL Server Days. Go here to register for this event. Let’s get together and talk.
The post Natively Compiled Procedures and Bad Execution Plans appeared first on Home Of The Scary DBA.
![]()
