

T-SQL Tuesday

For T-SQL Tuesday this month Raul Gonzalez has asked us all to blog about lessons learnt the hard way:
http://www.sqldoubleg.com/2017/07/03/tsql2sday-92-lessons-learned-the-hard-way/
My biggest sins have been executing code against production environments when I thought I was pointing at my local machine:
DELETE FROM dbo.Blah;
DROP DATABASE Blah;
I’ve learned from those experiences – mostly that I prefer it when I don’t have access to production!
As I’ve been doing a few posts about Statistics and Cardinality estimation recently I thought I’d cover instead the subject of Table Variables. This has maybe already been blogged to death, but it’s still one of the most common anti-patterns I see when performance tuning and a lesson I have seen so many people forced learn the hard way.
Table Variables vs Temp Tables
Those experienced with programming SQL will be familiar with both Temp Tables, and Table Variables as ways of storing intermediate resultsets within (for instance) a stored procedure.
Table variables came along with SQL Server 2000 and there seems to have been a wave of belief arriving with them that they were the latest and greatest thing. That Microsoft wanted us to use them from now on and stop using Temp tables. The day of the Temp table was over, long live the Table Variable!
Many developers reworked their code to replace all their temp tables with variables.
Uh-oh…
Initial guidance from Microsoft recommended table variables as the default except “where there is a significant volume of data and there is repeated use of the table”
They did however stress that you should test for any given scenario.
More recently they’ve updated their documentation to suggest “you should be cautious about using a table variable if you expect a larger number of rows (greater than 100).”
https://docs.microsoft.com/en-us/sql/t-sql/data-types/table-transact-sql
I often hear even more cautious advice:
- Only use a variable if there will be less than 30 rows
- Only use a variable where there will only be 1 row
- Never use table variables! (unless you have to)
I tend to go with one of the last two, there any many more examples where a table variable can screw up your performance than there are with temp tables.
There are times though where you still might want to use a table variable. They can be a little easier to work with, and sometime they might offer functionality you need (such as returning results from a table value function).
Just to clear up one misconception, both types of object are stored in TempDB and both of them will be mostly operative in memory rather than writing their data to disk (unless there are memory pressures, or bad estimates cause them to spill to disk). Even this is a bit more complicated than that, but in general they are managed the same way in the background.
What’s the big difference?
The big difference, and the reason you often don’t want to use a table variable is about statistics and cardinality estimation (which we’ve been looking at in the last few posts). In brief recap – statistics are what SQL uses to estimate how many rows (the cardinality) will be generated during part of a query operation. If it gets this estimation about right it can use that to form a good plan of attack for executing the query. If it gets it wrong it can make a dogs dinner of it.
And here’s the thing. Temp tables have statistics generated on them, but Table Variables don’t. As far as SQL’s concerned your table variable has exactly one row in it – regardless of reality.
Caveat: The way Temp tables manage statistics is a little bit weird, so you can get unpredictable result sometimes – but at least they try! See this if you want a really deep dive on the subject:
Page Free Space : Temporary Tables in Stored Procedures
Anyway, let’s look at a quick couple of examples of this and how it can make things go wrong.
Example 1: Getting that estimation badly wrong
First of all just to prove the point. Let’s create a table variable and a temp table and dump a million rows into each so we can look at how SQL manages estimates from them.
Table variable first:
DECLARE @a TABLE(i INT); --Create a million rows WITH Nums(i) AS ( SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) n(i) ) INSERT INTO @a(i) SELECT n1.i FROM Nums n1 CROSS JOIN Nums n2 CROSS JOIN Nums n3 CROSS JOIN Nums n4 CROSS JOIN Nums n5 CROSS JOIN Nums n6; SELECT i FROM @a;
I clicked the button in SSMS to capture the actual execution plan for this so we can see what is going on under the covers. I’m only interested in the final SELECT statement, which produces the pretty basic plan:
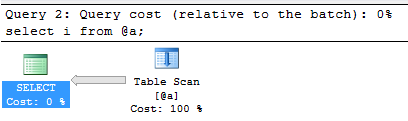
What I’m really interested in though is the properties of the Table Scan, which you can get by right-clicking and selecting Properties – or just hover over to get the Tool Tip you see below:
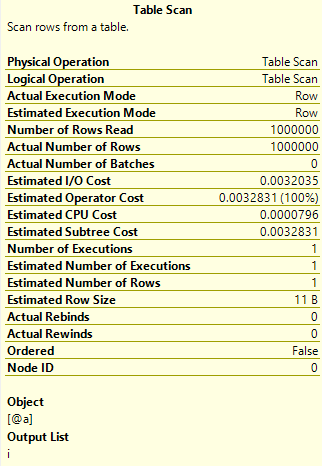
Look at where it says “Number of Rows Read” and “Actual Number of Rows” and you’ll see 1,000,000. Then look down to the Estimated Number of Rows and you’ll see 1. That’s quite a big difference.
Just to prove this is because we’re using a table variable, let’s quickly look at the same example with a temp table:
CREATE TABLE #a(i INT); -- Create a million rows WITH Nums(i) AS ( SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) n(i) ) INSERT INTO #a(i) SELECT n1.i FROM Nums n1 CROSS JOIN Nums n2 CROSS JOIN Nums n3 CROSS JOIN Nums n4 CROSS JOIN Nums n5 CROSS JOIN Nums n6; SELECT i FROM #a; DROP TABLE #a;
Here again’s the plan for the select, you’ll see it’s exactly the same:
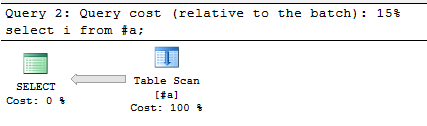
But look at the values in the Tool Tip this time:
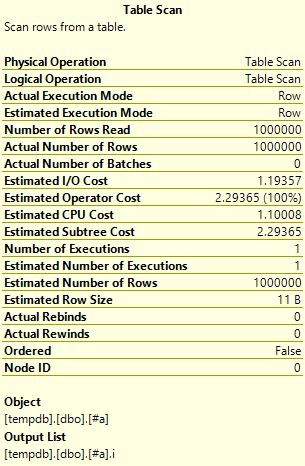
Now you’ll see all the values for number of rows are 1,000,000 – including the estimated number or rows which is very important as that’s the one SQL uses to work out what execution plan to use.
So that example was just to show how badly wrong the estimation is, but it probably didn’t hurt us that much as SQL selected the same plan in both cases. Let’s look at an example where it does bring some pain.
Example 2: Selecting a dodgy execution plan
The following query uses the AdventureWorks2012 database:
DECLARE @BusinessEntityId TABLE (BusinessEntityID INT NOT NULL PRIMARY KEY CLUSTERED); INSERT INTO @BusinessEntityId SELECT BusinessEntityID FROM Person.Person; SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT COUNT(*) FROM @BusinessEntityId b INNER JOIN Person.Person p ON b.BusinessEntityID = p.BusinessEntityID; SET STATISTICS IO OFF; SET STATISTICS TIME OFF;
Now let’s look at the execution plan for that final select:
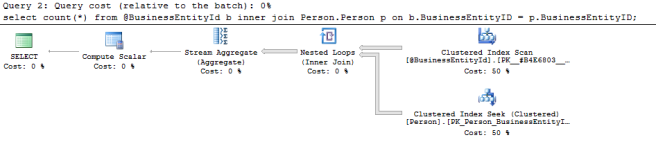
Nothing that’s too obviously controversial. It’s doing a Clustered Index scan on our Table Variable which is fine as we want all the rows that match a value in there. Then it’s doing an index seek on the Person table so it’s going straight to the results we want. Great!
Or Not…
Let’s look at the Tool Tips again, first for the Clustered Index Scan:
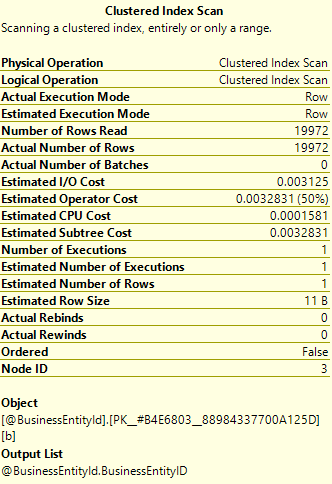
We focus on the same entries of before. Actual number of rows 19,772. Estimated number of Rows 1. Bit of a discrepancy. Is that affecting our plan though? All we can be sure of at this stage is that SQL thinks that’s a pretty good plan if we only had one row in the table variable. But we have a lot more than that.
Let’s look at the Tool Tip for the Clustered Index Seek:
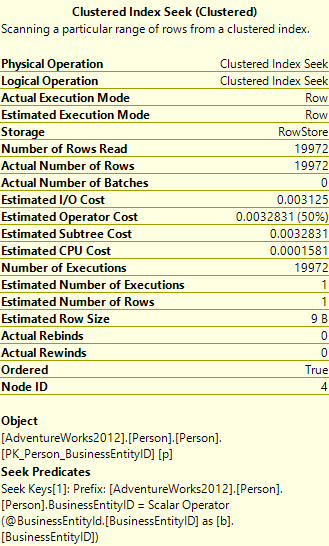
We can look at the same entries as before and we see the same discrepancy. But also look at the Number of Executions – SQL estimates it would have to execute this operator once as it thinks there’s exactly one row in the table variable. In actuality it executed it 19,772 times. That’s 19,772 seeks on the same table. I happen to know that’s the same as the number of records in the table. Surely there’s a better way of doing this.
In general the Nested Loops operator you see in the execution plan is good when the first( top) table is small compared to the second (bottom) table. Maybe it’s not the best choice in this case.
Now let’s look at the same example with a temp table:
CREATE TABLE #BusinessEntityId (BusinessEntityID INT NOT NULL PRIMARY KEY CLUSTERED); INSERT INTO #BusinessEntityId SELECT BusinessEntityID FROM Person.Person; SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT COUNT(*) FROM #BusinessEntityId b INNER JOIN Person.Person p ON b.BusinessEntityID = p.BusinessEntityID; SET STATISTICS IO OFF; SET STATISTICS TIME OFF; DROP TABLE #BusinessEntityId;
Here’s the plan:
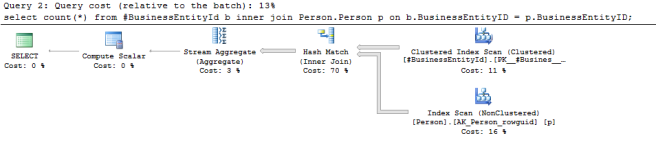
You’ll hopefully see that this plan is different. It’s using something called a Hash Match operator – this creates a hashed value based on each row from the top input (the index scan on our temp table), and then feed into that an index scan from our bottom input – the Person table.
Rather than going into too much the implications of that, let’s jump straight to looking at the Tool Tips.
From the top operator first, the Clustered Index Scan:
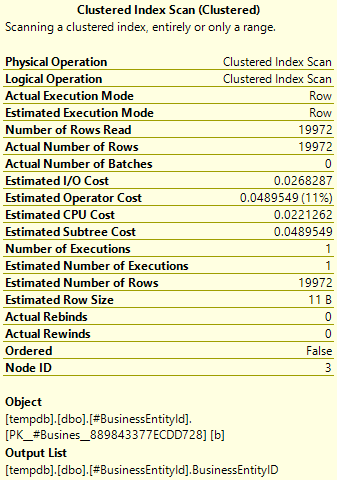
We can see here that the actual and estimated number of rows are both the same. Good so far.
Now to look at the bottom operator, the index scan on the Person table:
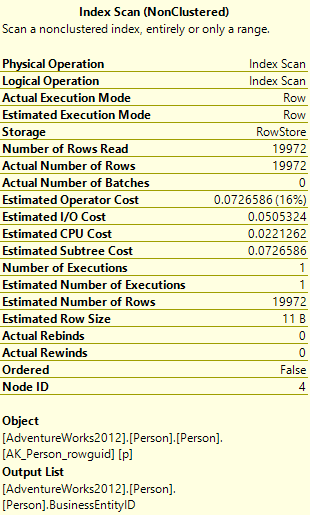
Now we can see that the estimated and actual number of rows are the same again, but also the estimated and actual number of executions are the same – 1 in both cases.
So we have the query with the table variable generating an execution plan that results in nearly 20,000 seeks against an index vs. the query with a temp table generating 1 scan against the same index. In general seeks are quicker than scans, but probably not 20,000 times quicker, even with the effort of the Hashing part of the operation. To quantify the difference we can look at the output from the STATISTICS IO command for each query:
Table variable:
Table ‘Person’. Scan count 0, logical reads 59916, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#B182BEEB’. Scan count 1, logical reads 35, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 39 ms.
Temp table:
Table ‘Workfile’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Person’. Scan count 1, logical reads 67, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#BusinessEntityId___________________________________________________________________________________________________00000000013D’. Scan count 1, logical reads 35, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 13 ms.
The output from the temp table query looks more complicated as it mentions a Workfile and Worktable that don’t get used, but it’s easy enough to see that Temp Table runs 3-4 times quicker, and more significantly generates only about 100 logical reads as opposed to about 60,000 for the table variable query. That’s a VERY big difference.
So like I said at the top, if you’re thinking about using a table variable, think twice, it might not be what you want to do.

![]()
