

Azure Data Lake Analytics (ADLA) is a distributed analytics service built on Apache YARN that allows developers to be productive immediately on big data. This is accomplished by submitting a job to the service where the service will automatically run it in parallel in the cloud and scale to process data of any size. Scaling is achieved by simply moving a slider, being careful to make sure the data and job is large and complex enough to provide parallelism so you don’t overprovision and pay too much. When the job completes, it winds down resources automatically, and you only pay for the processing power used. This makes it easy to get started quickly and be productive with the SQL or .NET skills you already have, whether you’re a DBA, data engineer, data architect, or data scientist. Because the analytics service works over both structured and unstructured data, you can quickly analyze all of your data – social sentiment, web clickstreams, server logs, devices, sensors, and more. There’s no infrastructure setup, configuration, or management.
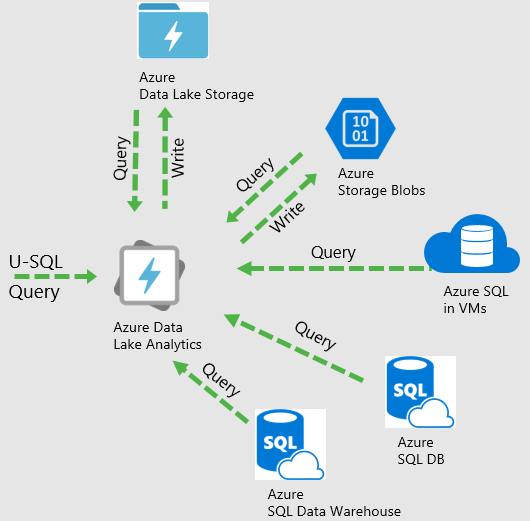
Included with ADLA is a new language called U-SQL, which is a big data language that seamlessly unifies the ease of use of SQL with the expressive power of C#. U-SQL’s scalable distributed query capability enables you to efficiently analyze data in the Azure Data Lake Store and across Azure Blob Storage, SQL Servers in Azure, Azure SQL Database and Azure SQL Data Warehouse. U-SQL is built on the learnings from Microsoft’s internal experience with SCOPE and existing languages such as T-SQL, ANSI SQL, and Hive. See Introducing U-SQL – A Language that makes Big Data Processing Easy and Tutorial: develop U-SQL scripts using Data Lake Tools for Visual Studio. Note that U-SQL differs in some ways from ANSI SQL or T-SQL (see Common SQL Expressions in U-SQL).
Perhaps the best value proposition of U-SQL is that it allows you to query data where it lives instead of having to copy all the data to one location. For external systems, such as Azure SQL DB/DW and SQL Server in a VM, this is achieved using federated queries against those data sources where the query is “pushed down” to the data source and executed on that data source, with only the results being returned.
Some of the main benefits of U-SQL:
- Avoid moving large amounts of data across the network between stores (federated query/logical data warehouse)
- Single view of data irrespective of physical location
- Minimize data proliferation issues caused by maintaining multiple copies
- Single query language for all data
- Each data store maintains its own sovereignty
- Design choices based on the need
- Push SQL expressions with filters and joins to remote SQL sources. There are two approaches:
- SELECT * FROM EXTERNAL MyDataSource EXECUTE @”Select CustName from Customers WHERE ID=1”; Use this approach when you want exact T-SQL semantics and just want to get the result back. Note that we are not federating any subsequent U-SQL against the result of this into the remote data source. Thus, this is called remote queries
- SELECT CustName FROM EXTERNAL MyDataSource LOCATION “dbo.Customers” WHERE ID=1; Use this approach when you want to write all in U-SQL and are fine with the possible slight semantic differences. In that case we will accumulate all U-SQL predicates against that location source and translate them into T-SQL based on REMOTABLE TYPES and the U-SQL to T-SQL translation. That is called federated queries
- Can access JSON in Blob/ADLS (via JSON extractor), text, CSV, TSV, and images (jpeg). Customers can also write their own custom extractors
You may have noticed that U-SQL is similar to PolyBase (see PolyBase use cases clarified). The main difference between the two is that PolyBase extends T-SQL onto unstructured data (files) via a schematized view that allows writing T-SQL against these files, while U-SQL natively operates on unstructured data and virtualizes access to other SQL data sources via a built-in EXTRACT expression that allows you to schematize unstructured data on the fly without having to create a metadata object for it. Also, PolyBase runs interactively while U-SQL runs in batch, meaning you can use PolyBase with reporting tools such as Power BI, but currently cannot with U-SQL. Finally, U-SQL supports more formats (i.e. JSON) and allows you to use inline C# functions, User-Defined Functions (UDF), User- Defined Operators (UDO), and User-Defined Aggregators (UDAGG), which are ways to add user-specific code written in C#.
More info:
U-SQL SELECT Selecting from an External Rowset
Setup Azure Data Lake Analytics federated U-SQL queries to Azure SQL Database
Tutorial: Get started with Azure Data Lake Analytics U-SQL language
Video Bring Big Data to the masses with U-SQL
Video U-SQL – A new language to process big data using C#/SQL

![]()
