

I see a lot of confusion when it comes to Hadoop and its role in a data warehouse solution. Hadoop should not be a replacement for a data warehouse, but rather should augment/complement a data warehouse. Hadoop and a data warehouse will often work together in a single information supply chain: Hadoop excels in handling raw, unstructured and complex data with vast programming flexibility; Data warehouses, on the other hand, manage structured data, integrating subject areas and providing interactive performance through BI tools. As an example in manufacturing, let’s look at using Hadoop and a data warehouse on a Parallel Data Warehouse (PDW):
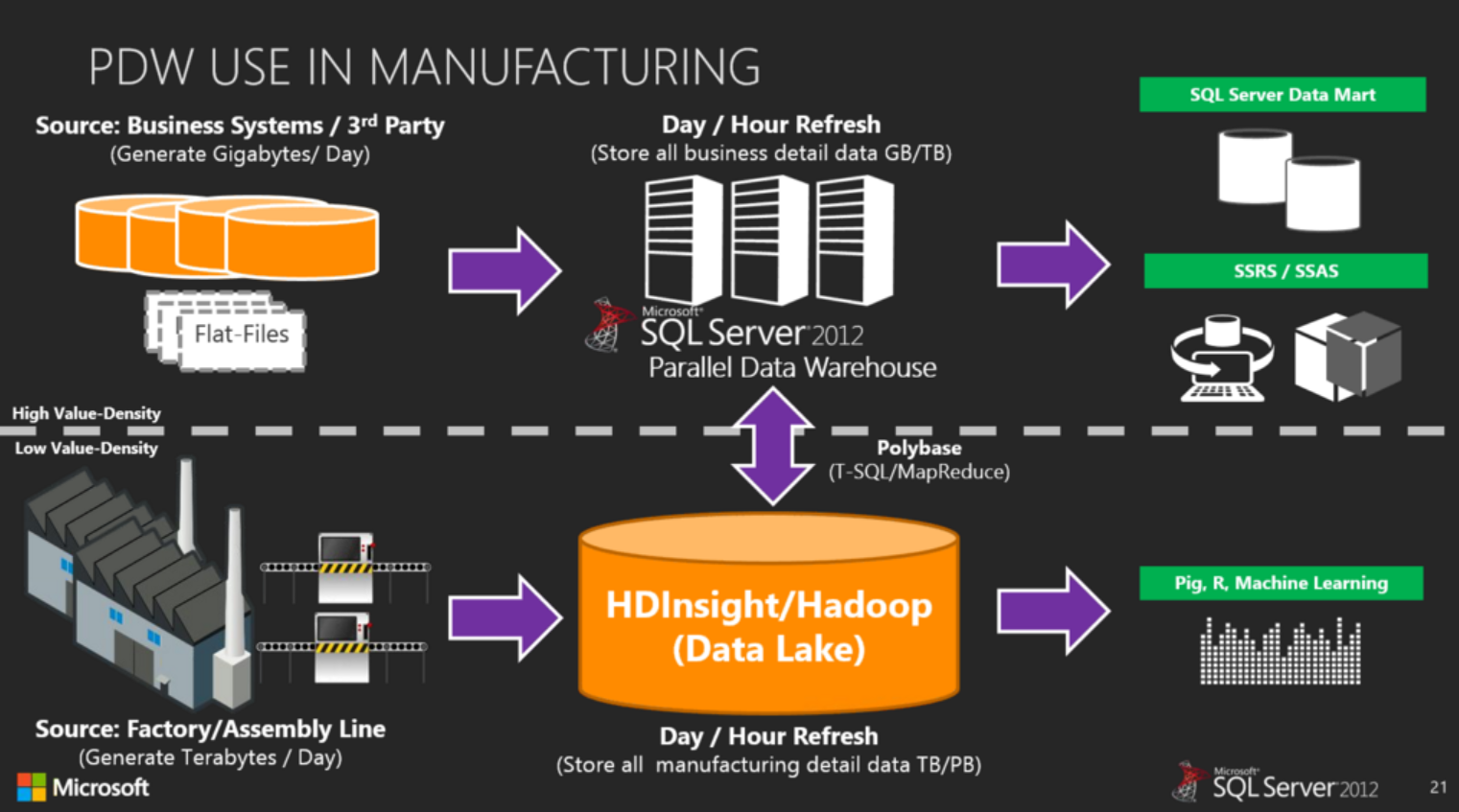
There are three main use cases for Hadoop with a data warehouse, with the above picture an example of use case 3:
- Archiving data warehouse data to Hadoop (move)
Hadoop as cold storage/Long Term Raw Data Archiving:
– So don’t need to buy bigger PDW or SAN or tape
- Exporting relational data to Hadoop (copy)
Hadoop as backup/DR, analysis, cloud use:
– Export conformed dimensions to compare incoming raw data with what is already in PDW
– Can use dimensions against older fact table
– Sending validated relational data to Hadoop
– Hadoop data to WASB and have that used by other tools/products (i.e. Cloud ML Studio)
– Incremental Hadoop load / report
- Importing Hadoop data into data warehouse (copy)
Hadoop as staging area:
– Great for real-time data, social networks, sensor data, log data, automated data, RFID data (ambient data)
– Where you can capture the data and only pass the relevant data to PDW
– Can do processing of the data as it sits in Hadoop (clean it, aggregate it, transform it)
– Some processing is better done on Hadoop instead of SSIS
– Way to keep staging data
– Long-term raw data archiving on cheap storage that is online all the time (instead of tape) – great if need to keep the data for legal reasons
– Others can do analysis on it and later pull it into data warehouse if find something useful
Note there will still be a need for some Hadoop skills: Loading data into Hadoop (unless all done thru Polybase), maintenance, cleaning up files, managing data, etc. But people who need access to data don’t need any Hadoop skills or special connections – they can use all skills they have today.
Here are some of the reasons why it is not a good idea to have only Hadoop as your data warehouse:
- Hadoop is slow for reading queries. HDP 1.0 is a batch processing infrastructure, not interactive/realtime. HDP 2.0 will support interactive queries but is new and still will not perform anywhere near PDW for interactive querying. This is why PolyBase is so important, as it bridges the gap between the two technologies so customers can take advantage of both the unique features of Hadoop and realize the benefits of a EDW. Truth be told users won’t want to wait 20+ seconds for a MapReduce job to start up to execute a Hive query
- Hadoop is not relational, as all the data is in files in HDFS, so there always is a conversion process to convert the data to a relational format
- Hadoop is not a database management system. It does not have functionality such as update/delete of data, referential integrity, statistics, ACID compliance, data security, and the plethora of tools and facilities needed to govern corporate data assets
- Restricted SQL support, such as certain aggregate functions missing
- There is no metadata stored in HDFS, so another tool needs to be used to store that, adding complexity and slowing performance
- Finding expertise in Hadoop is very difficult: The small number of people who understand Hadoop and all its various versions and products versus the large number of people who know SQL
- Super complex, lot’s of integration with multiple technologies to make it work
- Many Hadoop tools/technologies/versions/vendors to choose from, with no standards. See all the various Apache Hadoop technologies here
- Some reporting tools don’t work against Hadoop, as well as some reporting tools require data in OLAP
- May require end-users to learn new reporting tools and Hadoop technologies to query the data
- The new Hadoop solutions (Tez, X, Spark, etc) are still figuring themselves out. Customers should not take the risk of investing in one of these solutions (like MapReduce) that may be obsolete
- It might not save you much in costs: you still have to purchase hardware, support, licenses, training, migration costs. And then there is the possibility of a big company acquiring a Hadoop company and the cheap solution becoming much more expensive
- If you need to combine relational data with Hadoop, you will need to move that relational data to Hadoop since there is no PolyBase-like technology
I also wanted to mention that “unstructured” data is a bit of a misnomer. Just about all data has at least some structure. Better to call it “semi-structured”. I like to think of it as data in a text file is semi-structured until someone adds structure to it, by doing something like importing it into a SQL Server table. Or think of structured data as relational and unstructured as non-relational.
More info:
Using Hadoop to Augment Data Warehouses with Big Data Capabilities
WEBINAR Replay: Hadoop and the Data Warehouse: When to Use Which
Hadoop and the Data Warehouse: When to Use Which
Video Big Data Use Case #5 – Data Warehouse Augmentation
How Hadoop works with a Data Warehouse
Design Tip #165 The Hyper-Granular Active Archive
No, Hadoop Isn’t Going To Replace Your Data Warehouse
A fair benchmark for Impala 2.0 – part 1

![]()
