

While writing stored procedures or SQL scripts of some sort, I very often need to look up something about the tables that I am working with; A list of field names and their data types, which columns make up the primary key, are there foreign keys, is a column nullable, etc. Basically the standard info that you might need to work successfully with a table.
Now we all know that you can obtain everything via SQL Management Studio by right-clicking on the table and going into the table's design view. But it feels very clumsy, and its slow, and was driving me nuts because I was doing it so often.
So using what's in INFORMATION_SCHEMA and some sys tables, I decided to write a stored procedure that I can just execute on the spot, in my currently open query editor window, that will give me everything I need.
Within about 2 to 3 seconds I had the following information about a table (That's 2 to 3 seconds execution time, not writing time):
- The schema it belongs to.
- The list of column names.
- Their data types.
- Whether they are nullable.
- Their default value.
- Which columns made up the primary key.
I finished my first version and was so chuffed with it that I sat there like an idiot just executing it against most of the tables in my DB to see the magic info appear instantly.
Now I'm no DBA, I'm just a programmer, and I'm sure there are tools that can do this, and a whole lot more, in a funkier way, but I don't know about them and this one was just so easily accessible, and I wrote it, which always makes things much more exciting.
When you get down to the actual SQL I wrote, I'm also sure there are better ways of doing some of it, but I just learnt as I went and didn't spend too much time changing things once I had it working.
After some time of using it in my real world, I realized I was still spending way too much of my time, via laborious means, going to look up dependencies, what relationships existed against the table, if a specific column had an index (for performance), and whether there was perhaps an obscure trigger or two on my table (ones that were secretly messing with my data without me knowing about it).
Hence I expanded my SP. It would now also show me:
- Which columns were foreign keys.
- The foreign key schema and table name.
- The name of the column in the foreign key table.
- The name of the foreign key constraint.
- Whether a column had an index on it, and what kind of index.
- And for good measure, the first of other constraints too, such as a unique key/constraint.
- I also added indicators for identity columns and computed columns.
- And optionally a list of the triggers on the table.
I called it TableInfo and here is how you use it:
exec dbo.TableInfo [SchemaName].[, FieldNameFilter][, Extended]
- TableName: The table name of the table you are retrieving info for. This can be either just the table name, or optionally you can prefix it with the schema that the table belongs to. This is useful for when there is more than one table with the same name in different schemas.
- FieldNameFilter (optional): If you have a table with a lot of columns, you can use this to filter the results by column name to quickly get to the info about a specific column or set of similarly named columns. It is compared with the LIKE operator. So you can pass in 'customer%' to return all the columns starting with 'customer'. If you pass in a value without the wildcards, its effectively an equals. Eg. passing in 'CustomerID' will only return results where the column has that exact name..
- Extended (optional): A bit flag, to indicate whether to include extended info. 1 = include. Currently, the only extended info that is returned is a second result set containing info about all the triggers on the table. By default extended info is not returned.
If you add the TableInfo SP to the AdventureWorks database and run it against the Customer table as follows,
exec dbo.TableInfo 'sales.Customer'
then you get the below result.

So very quickly we can see that the Customer table has 6 columns and what their names are, and that these are all columns belonging to the Customer table belonging to the Sales schema. (If we have executed it without the schema prefix, and there was another Customer table on a different schema, we would also have seen the column results for that table).
The returned results:
- We see that CustomerID is the primary key, is of type int and is an identity column. We also see that under IX (for index) it says 'c, unique'. The 'c' stands for clustered, where 'nc' will stand for non-clustered. The 'unique' part is pretty self-explanatory and indicates that this is a unique index, and it is in fact the unique index supporting the primary key. Note that a unique index and a unique key/constraint is not exactly the same thing. If I have my facts right, a unique key implies a unique index, but the converse is not true.
- TerritoryID shows that it has a foreign key, that it is also of type int, that it has a non-clustered index, and it is nullable and that the default value is null. We also see that it has a relationship to the schema.table.column Sales.SalesTerritory.TerritoryID, and that the name of the constraint is FK_Customer_SalesTerritory_TerritoryID. (The index in this case supports the foreign key)
- AccountNumber shows that its a computed column.
- And rowguid and ModifiedDate both have non-null default values.
- If one of the columns had had another constraint such as a unique index, other than a relationship constraint, it would have shown up under Cons.
I used separate columns in the results to show PK and FK because a primary key column can also of course be a foreign key column.
A quick note about the index information in the IX column of the results. I have already explained some of it, but here are all the possibilities:
- c: clustered index
- nc: non-clustered index
- unique: the index is a unique index. If it is omitted it means the index is not unique
- desc: indicates the index is descending. If it is omitted it means the index is ascending
- (disable): speaks for itself
Also note that because a column can have more than one index on it, I had to choose what info to display as the structure of the results does not cater for multiple indexes. In deciding what to display I went with the following:
- If there are one or more clustered indexes, it will show 'c', even if there are also non-clustered ones.
- If there are one or more unique indexes, it will show 'unique', even if there are also non-unique ones.
- If there are one or more enabled indexes, it will not show '(disabled)'. I.e. it will show enabled, even if there are disabled ones.
- If there are one or more descending indexes, it will show 'desc' for descending, even if there are also ascending ones.
In addition, if there is more than one index on a column, it will show the number of indexes in brackets at the start. For example, the IX column might read '(2) c, unique, desc (disable)', which will mean that there are 2 indexes on the column, that at least one is clustered, unique, descending, and disabled. So, if there is a number in the IX column, and it matters to you, you would have to go and lookup more about those indexes via other means. If there's no number, then all is safe and there's only one index.
Another thing that could be built into a future version of this SP is an indicator to link indexes that span multiple columns together.
Now lets say you quickly want to see the info of all columns containing 'ID' in their name. You'd run it as follows:
exec dbo.TableInfo 'sales.Customer', '%ID%', and you'd see the below results.

This is especially useful on mammoth tables, with hundreds of columns, that were designed, or non-designed, by non-DB (or non-any-kind-of) developers.
And lastly, if you also want to see a quick list of the triggers against the table, run it with the Extended option as follows:
exec dbo.TableInfo 'sales.Customer', null, 1
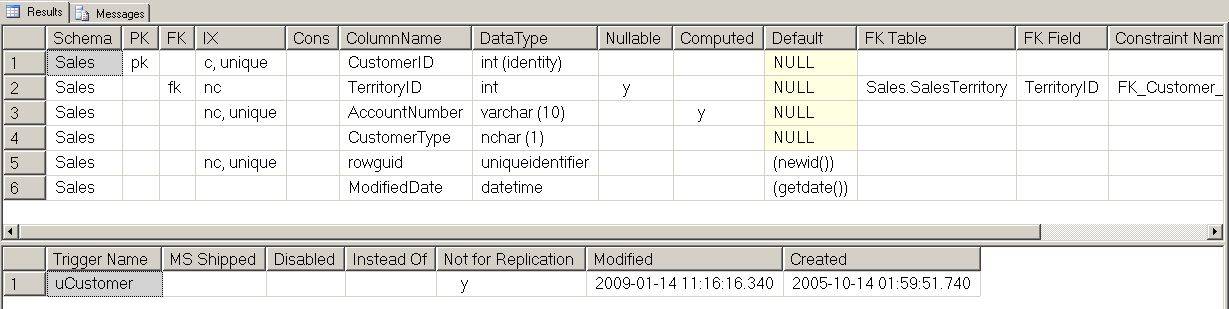
You'll see that this includes a second result set containing any triggers on the table with some info about those triggers. This could save you hours of debugging anomalous changes to your data if there is a sneaky trigger you didn't know about, written by those very same aforementioned non-developers..
Here are those three exec statements again.
exec dbo.TableInfo 'sales.Customer' exec dbo.TableInfo 'sales.Customer', '%ID%' exec dbo.TableInfo 'sales.Customer', null, 1
And finally, the TableInfo stored procedure is in the Resources section below. You should be able to figure out what it does from the comments.
Conclusion
Over the last year, this SP has saved me a huge amount of time and effort. Definitely much more time was saved by it than the time I spent writing it. I hope it does the same for some others out there.
I would love to hear feedback, you like, you don’t like and why, and what else it could do, a better way of doing it, or just that you use it.
Note, I started writing this SP on SQL Server 2005, but I finished it on 2008 and haven't tested the latest version on 2005 again, so no guaranties that it will work.
Update 15 Jan 2014
Latest version has a fix. FK Table colum was displaying the incorrect schema name if the FK table was in a different schema to the main table.
