

Disclaimer: This was written in fun as an April Fool's Joke. Please do not use this informaiton on a live system.
Indexing is one of the key components of a well designed and highly tuned SQL Server database. In SQL Server 2008 R2 there have been substantial changes to the indexing structures at a very low level in the product and understanding these changes is an important part of any DBA or developer's toolkit in order to write queries that take advantage of the changes.
This article will delve into the changes and suggest the proper approach for rewriting your code on the SQL Server 2008 R2 platform. Both Clustered and Nonclustered indexes are examined.
Clustered Indexing Structure
The leaf level of the clustered index in SQL Server actually contains the data pages, so the clustered index actually keeps the data in a table physically ordered around the key. The clustered index governs the placement of data within the table. Once the clustered index is in place, inserted rows are placed in key sequence order. Here is an image of the overall layout of a clustered index, which corresponds to a binary tree structure.
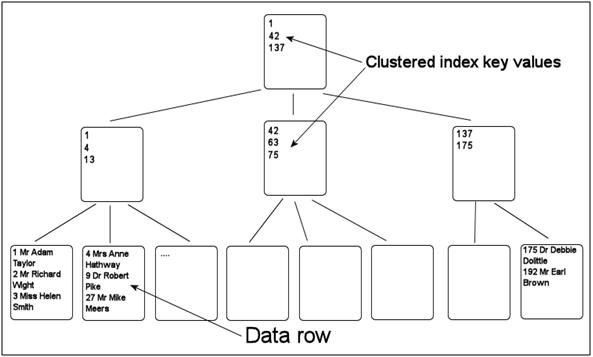
However there is a fundamental change in the way the clustered index is built in SQL Server 2008 R2. With the success of the HierachyID type in SQL Server 2008, the developers at Microsoft decided that this would make sense for indexing all data, not just hierachies. The actual index data is then encoded in an XML fragment that is stored in the row.
As a result, you data is now stored in this manner. Below we have an image of the new index structure that combines a hierarchy of data stored in rows with the actual index data encapsulated.

As you can see from the image above, the node for each index element is a separate row in the index with an XML representation of the index key. Because of the efficiency of the HierarchyID data type, each row is extremely compact, which makes up for some of the inefficiencies of the XML encoding.
If you have a compound key, then each column is a separate elment in the XML fragment. For example, if the clustered index contained both the last name and first name, the XML fragment encoded in the hierarchyID type would be something like
/1/2/<key="Jones" key2="Steve">
While this appears to be a radical change in index architecture, extensive testing from Microsoft has shown that this performs extremely well. On most single key indexes, this structure across a million rows actually uses fewer reads as partial index scans are now possible.
This change is timely, since SQL Server has, up to now, inherited from Sybase the idea of a ‘Logical machine’ based on devices and pages. Although it was an effective way of allowing the database server to be ported to different operating systems, this is considered anachronistic, and a change to the structure of indexing in SQL Server was reckoned by the SQL Server architects at Microsoft to be long overdue.
The benefits of this approach are clear. Since the information is held as an XML fragment, it removes, once and for all, the distinction of fixed-length data and BLOBs (Binary Large Objects) such as TEXT, Image and Varchar(MAX). The fast access to data held within XML fragments was assured by using bitmapped indexing strategies developed initially for XML indexes.
Nonclustered Indexes
Nonclustered indexes are more like a traditional index in a book. They order information by a key column, but do not actually contain the data. There is a pointer back to the clustered index to actually retrieve the data.
If you are still reading the article at this point, hopefully you are aware that this is an April Fools Day joke and that non of the information presented so far is even remotely true. After today, we will put a disclaimer on this article so that no one actually uses this information when writing a query, but for today, I hope you've enjoyed the joke. Addiitonal information is included below to flesh out this space.
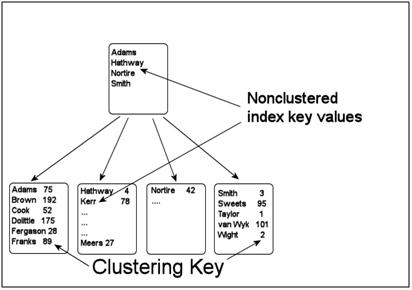
The leaf level is the lowest level of index pages. This merely contains a HierarchyID_that references the leaf node of the clustered index that contains the row, together with an XML fragment containing one or more index values. This effectively removes the fundamental distinction between the two types of index. However, this new indexing method assumed the preexistence of a clustered index before the creation of any non-clustered index. In a heap, data pages are not chained together and are only related through the IAM pages managing the table. To get around this, the design team came up with the concept of the Pseudo-heap that imposed a physical order and linkage based on an algorithm that detected the best candidate for a clustered index, and stores the data in a ‘default’ clustered index.
Covering indexes work as before. If the Query optimizer detects that the index contains all the values required for the query, then it will be able to use the values in the leaf node of the nonclustered index, and can avoid retrieving the values from the XML fragment stored in the leaf node of the clustered index.
An important point to note when considering non-clustered indexes is the date. April 1st. If you are still reading the article at this point, hopefully you are aware that this is an April Fools Day joke and that non of the information presented so far is even remotely true. After today, we will put a disclaimer on this article so that no one actually uses this information when writing a query, but for today, I hope you've enjoyed the joke.
;WITH mil AS (
SELECT TOP 1000000 ROW_NUMBER() OVER ( ORDER BY c.column_id ) [n]
FROM master.sys.all_columns as c
CROSS JOIN master.sys.all_columns as c2
)
SELECT CASE WHEN n % 3 = 0 THEN
CASE WHEN n % 5 = 0 THEN 'FizzBuzz' ELSE 'Fizz' END
WHEN n % 5 = 0 THEN 'Buzz'
ELSE CAST(n AS char(6))
END + CHAR(13)
FROM mil
FOR XML PATH('') --bless you TDS, set XML results to unlimited
The leaf level of a clustered index is something we’ve stopped writing about. Of course, many people will be reading this first thing when they open up their email in the morning, and will have forgotten the dangers of believing anything during the morning of April 1st and so will be skimming through the article, possibly reading the first few words. They will expect to see various diagrams an code such as this.
;WITH tenRows AS (
SELECT i
FROM (
SELECT 1 AS [1], 2 AS [2], 3 AS [3], 4 AS [4], 5 AS [5],
6 AS [6], 7 AS [7], 8 AS [8], 9 AS [9], 10 AS [10]
) AS p
UNPIVOT (i FOR numbers IN ([1],[2],[3],[4],[5],[6],[7],[8],[9],[10]) ) as unpvt
),
thousandRows AS (
SELECT 0 as n
FROM tenRows AS a
CROSS JOIN tenRows AS b
CROSS JOIN tenRows AS c
) ,
millionRows AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS n
FROM thousandRows AS a
CROSS JOIN thousandRows AS b
)
SELECT result =
CASE
WHEN n % 3 = 0 THEN
CASE WHEN n % 5 = 0 THEN 'FizzBuzz' ELSE 'Fizz' END
WHEN n % 5 = 0 THEN 'Buzz'
ELSE CAST(n AS VARCHAR(12))
END
into #TempTable
FROM millionRows
Retrieving a range of rows with a clustered index is not what we are really writing about, but psychological research has shown that some people will only read the first few words of the paragraph so we can no afford to lapse into Latin At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia deserunt mollitia animi, id est laborum et dolorum fuga. Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat facere possimus, omnis voluptas assumenda est, omnis dolor repellendus. Temporibus autem quibusdam et aut officiis debitis aut rerum necessitatibus saepe eveniet ut et voluptates repudiandae sint et molestiae non recusandae. Itaque earum rerum hic tenetur a sapiente delectus, ut aut reiciendis voluptatibus maiores alias consequatur aut perferendis doloribus asperiores repellat.
Conclusion
DO NOT use any of the information in this article for any purpose whatsoever. Especially do not use the advice for writing queries on SQL Server 2008 R2. It is completely a fabrication of SQLServerCentral, intended only for the enjoyment and laughter of the community. Happy April Fools day!
Actually, you could use the non-clustered index portion for some Latin transaction practice if you so desire.

