

The Sins of Old: Time_T
When building a cube or other reporting mechanism, quite often it is nessecary to be able to produce a definitive list of times. One of the classic 'Sins of SQL' is to create a table to house time values, with up to 3,600 rows for a single hour if you go as low as the seconds values in your data. The trouble is that then each fact table joins to your time table along the lines of:
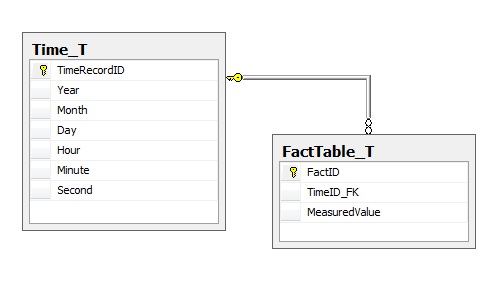
This pattern effectively creates a surrogate identity for time itself, and has some nasty consequences for SQL developers:
- Adding records to the Fact table requires a lookup on the time (or an insert if it's a new time).
- The SQL to query this becomes complex and unwieldy.
- Assuming a you are querying an arbitrary time range of say, 45 minutes in the table, if you work at the seconds resolution your time table will have 2,700 keys that match, and each of these keys needs to then be linked back to the table. This decrease in performance is less if you only go down to the minutes or even hours, but is still orders of magnitudes worse than a direct linear scan on a DATETIME column.
- The saving per row is only 4 bytes if you use an 4-byte INT (versus a DATETIME's 8 bytes), or actually nothing if you use a BIGINT.
Here's an example of the SQL needed to query such a table to produce a simple report:
SELECT
T.*, FactID, MeasuredValue
FROM
Time_T AS T
INNER JOIN FactTable_T AS F ON T.TimeRecordID = F.TimeID_FK
WHERE
T.Year = 2010
AND
T.Month = 4
AND
T.Day BETWEEN 1 AND 2
What we really want is to write something nice and clean like:
SELECT * FROM FactTable_T WHERE FactTime BETWEEN '1 April 2010' AND '2 April 2010'
This is better from both a maintainability standpoint (no complexity added), but is also better for performances since an index against the FactTime column will allow fast seeking/scanning of specific time ranges within the table. SQL Server will seek to a single row in the index and then keep scanning forward until it reaches the end of the time range, executing the query in no time at all.
It's possible in many circumstances to store both the time-table record key and the actual time at the same time in the table if you've got the space, but this violates a few database design principles (duplication of data in particular), and still doesn't make inserting records any easier. Fear not though, for there is another way.
A Dynamic Time-Table Replacement
So if we've established that using a time-table is neither faster, easier to work with in T-SQL, nor good practice - then how does one create time dimensions for use in SQL Server Analysis Services? Using the Common Table Expression feature from SQL Server 2005 and upwards, we can create a helper function such as:
/**
* Function:fn_GetTimestampRange
* Author:Steve Gray / steve.gray@cobaltsoftware.net
* Version:1.0.0.0
* Date:30 April 2010
*
* Parameters:
*@FromDate- Start of time-range
*@ToDate- End of time-range
*@IncludeSeconds- 0 = Minute level, 1 = Second level
**/
CREATE FUNCTION fn_GetTimestampRange(@FromDate DATETIME, @ToDate DATETIME, @IncludeSeconds BIT)
RETURNS TABLE
AS
RETURN (
/* Loop through the days in the range */
WITH DayCTE([Date])
AS
(
SELECT CONVERT(DATETIME, CONVERT(VARCHAR(255), @FromDate, 20))
UNION ALL
SELECT DATEADD(DAY, 1, [Date]) FROM DayCTE WHERE Date < @ToDate
),
/* Obtain a set of numbers 0..59 */
NumberCTE([Number])
AS
(
SELECT 0
UNION ALL
SELECT Number + 1 FROM NumberCTE WHERE Number < 59
)
SELECT
Result.DateKey,
DATEPART(YEAR,Result.DateKey)AS [Year],
DATEPART(QUARTER,Result.DateKey)AS [Quarter],
DATEPART(WEEK,Result.DateKey)AS [Week],
DATEPART(WEEKDAY,Result.DateKey)AS [WeekDayNumber],
DATENAME(WEEKDAY,Result.DateKey)AS [WeekDayName],
DATEPART(DAYOFYEAR,Result.DateKey)AS [DayOfYear],
DATEPART(MONTH,Result.DateKey)AS [Month],
DATEPART(DAY,Result.DateKey)AS [Day],
DATEPART(HOUR,Result.DateKey)AS [Hour],
DATEPART(MINUTE,Result.DateKey)AS [Minute],
DATEPART(SECOND,Result.DateKey)AS [Second]
FROM
(
SELECT
DATEADD(SECOND, COALESCE(SecondCTE.Number, 0),
DATEADD(MINUTE, MinuteCTE.Number,
DATEADD(HOUR, HourCTE.Number, DayCTE.Date))) AS DateKey
FROM
DayCTE
LEFT JOIN NumberCTE HourCTE ON HourCTE.Number
BETWEEN 0 AND 23
AND DayCTE.Date IS NOT NULL
LEFT JOIN NumberCTE MinuteCTE ON MinuteCTE.Number
BETWEEN 0 AND 59
AND HourCTE.Number IS NOT NULL
LEFT JOIN NumberCTE SecondCTE ON SecondCTE.Number
BETWEEN 0 AND 59
AND @IncludeSeconds = 1
AND MinuteCTE.Number IS NOT NULL
WHERE
DATEADD(SECOND, COALESCE(SecondCTE.Number, 0),
DATEADD(MINUTE, MinuteCTE.Number,
DATEADD(HOUR, HourCTE.Number, DayCTE.Date)))
BETWEEN @FromDate AND @ToDate
) RESULT
);
And voila, you can how dynamically generate a list of timestamps between two points in time in T-SQL, such as;
SELECT * FROM dbo.fn_GetTimestampRange('1 January 2010', '1 April 2010',1);
(Note that if you want to produce more than 100 distinct days in a single query, you'll need to append OPTION(MAXRECURSION numberOfDays) to your query, where numberOfDays is the number of days you wish to loop through. This can be hidden away in the stored procedures, and SQL Server allows you to specify a MAXRECURSION of 0, which does not limit the amount of days that can be processed.
Bringing it All Together
Now that you've got rid of the time-table gremlin, the next step is to put your regular timestamp columns back (if you didn't drop them already), and then start building your cube. There are just a few steps required here:
- Create a view of your 'Fact' table with a computed column that times out the milliseconds from the timestamp (and seconds, if you are only doing HH:MM level data).
- In the designer add a 'Named Query' that pulls out the appropriate time-range from the fn_GetTimestampRange function that you need.
- Designate the DateKey column as the primary key of the time view.
- Connect your fact table timestamp column to the date-key on your view.
You should end up with something looking much like this:
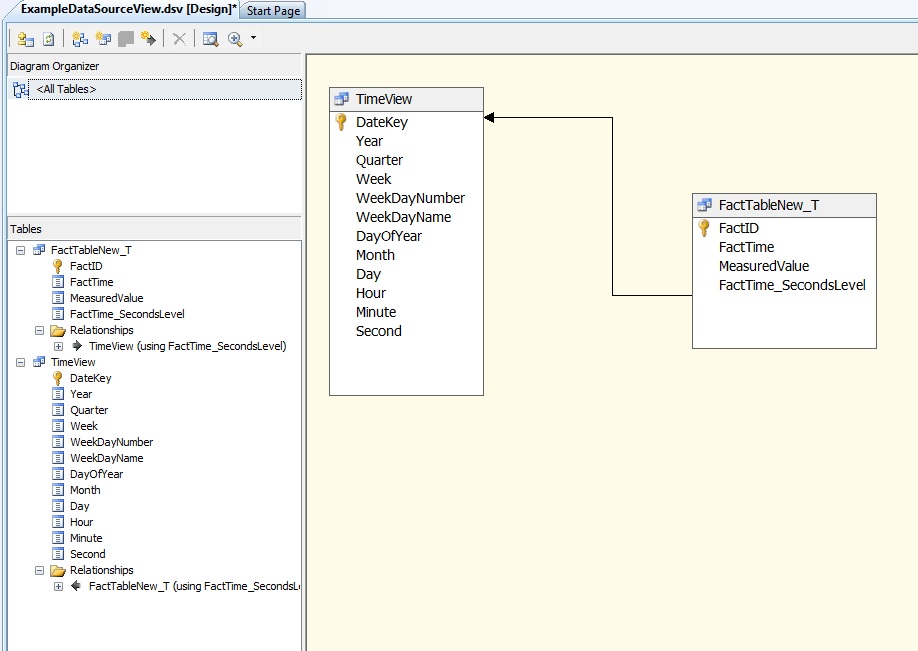
Once you've done this, you can define your date dimension hierarchies (i.e. Year, Quarter, Monty, Day, Hour, Minute, Second) in the designer as usual and start processing your cube. To support incremental loading of the time partition you simply need to pass in the range of time-stamps to the Proactive Caching polling queries, and Analysis Services will take care of the rest for you. It's best to pre-load a few samples worth of time values, or if space-permits pre-allocate several months or years worth of values. This will prevent the need to periodically re-process the time partition at the same time as the fact partition.
Conclusion
Hopefully you'll now be on the cusp of dropping your time-table and numbers tables, or at least scaling back their usage. There's still plenty of room to change and play with this code though - Some useful changes you may wish make to this include:
- Change the week/weekday numbering to reflect your own companies calendar.
- Change to only go as far as hours (it's not the norm to report at the minute/second level in many cases).
Share and enjoy. If you make use of this I'd really love to hear about it.
