

There Must Be 15 Ways To Lose Your Cursors...
Part 2: Just Put It in a Set, Brett
In part 1 of this series, I introduced the problem of explicit cursors and loops in SQL. I made the claim that by SQL Server 2005 and later, cursors were no longer necessary to SQL development and in fact were significantly harmful. Then I explained that developers still use them because they do not know how not to or because they find them easier the real set-based SQL (initially, anyway). I finished with an example of a simple Cursor procedure and asked you to try to convert it to set-based SQL as homework.
In this installment, we will be looking at the simplest cases and how to convert them. This will include a general methodology for doing these conversions and several examples of explicit cursors and loops that we will convert by applying this methodology.
Homework Review
We ended part 1 with the following example of procedural code (note that the keyword STATIC was erroneously left out of the original listing) :
Declare @dummy int
Declare @X int
Set @X = 0
Declare XCursor Cursor STATIC LOCAL FORWARD_ONLY For
Select 1
From master.sys.columns c1
Cross Join master.sys.columns c2
OPEN XCursor
FETCH NEXT FROM XCursor Into @Dummy
WHILE @@Fetch_Status = 0
Begin
Set @X = @X + 1
FETCH NEXT FROM XCursor Into @Dummy
End
Print @X
I asked you to run this procedure to measure its run-time on your SQL Server. On my system, it takes about 130 seconds on average and returns a single row and column with the value 407,044 (this number may vary slightly on different SQL Server 2005 instances). Normally we will want slightly more information than this so we will want to use a standard measurement technique.
Standardized Measurements
For most performance comparisons, we will want three metrics:
- CPU time
- Logical Reads
- Elapsed Time
CPU time is simply the amount of time that a query was using the CPU. Logical Reads are the number of read requests issued by our query, before any caching is taken into account. And, Elapsed time is simply the total amount of time that has passed during the execution of our query.
Normally we could use the SET STATISTICS commands to collect and display this information, however cursors present a special problem for this approach. Because the SET STATISTICS commands cause their statistics to be displayed after the execution of every statement and explicit cursors execute multiple statements in a loop for every row, the statistics displayed will not be totaled for the execution of the entire procedure. Instead, we will get several million lines of statistics output for each individual statement execution with no easy way to total them. Even worse, there is the possibility that this many lines of message output could actually slow down the Cursor procedures giving us an unfairly slow measurement for them.
To remedy this I have created the following measurement "harness" that we will use to enclose every example that we test, to insure fair and standardized results.
/* SQL commands to replace SET STATISTICS for measuring multi-statement procedures. Note: sometimes returns negative numbers, If this happens just run it again. */Set NoCount On Declare @cpu_ int Declare @lreads_ int Declare @eMsec_ int Select @cpu_ = cpu_time , @lreads_ = logical_reads , @eMsec_ = total_elapsed_time From sys.dm_exec_requests Where session_id = @@spid --====== -- Your Test Code Goes Here --====== Select cpu_time-@cpu_ as CpuMs , logical_reads- @lreads_ as LogRds , total_elapsed_time - @eMsec_ as Elapsed From sys.dm_exec_requests Where session_id = @@spid
To use this measurement harness, simply insert the code to measure where it says "Test Code Goes Here".
Testing the Cursor Version
When I execute the Cursor code in this measurement harness, here are the results that I get:
| CPU msec | Logical Reads | Elapsed msec |
|---|---|---|
| 6,468 | 2,207,893 | 6,937 |
The Set-Based Version
Next, I asked you to figure out what it did and to write a set-based version that does the same thing. Since this routine just counts the number of rows that it finds in the "master.sys.columns" table crossed with itself, the set-based version is pretty easy:
Select Count(*)
From master.sys.columns c1
Cross Join master.sys.columns c2
As you can see, not only have we reduced the size of the code by 85%, it also actually tells us what it is returning. And I don't think that anyone could argue that set-based version is not easier to read than the original cursor-based version. As for performance, here are the results on my system:
| CPU msec | Logical Reads | Elapsed msec |
|---|---|---|
| 0 | 44 | 2 |
In this case the set-based version is clearly superior.
What Do I Really Mean By "Cursors and Loops"?
One thing that I should make clear before we go any further is just exactly what do I mean by "Cursors" and "Loops" in SQL? Technically, anything in SQL that serializes a data stream and can keep positional context is a cursor. However, when I say "cursors are bad" I do not mean this more general designation of cursors, such as client-side cursors, internal cursors, implicit cursors, pseudo-cursors, etc. I mean explicit Transact-SQL server-side cursors. These are the kind that are explicitly written in procedures and that use the CURSOR datatype. You may have noticed that I usually capitalize "Cursor" and this is to intentionally indicate these explicit Cursors. In the event that I should ever be talking about the more general concept or types of cursors, then I use the lower case form.
Loops also exist at all levels of SQL Server and any processing of a set by a processor must at some level come down to one or more loops. However, my concern is with explicit loops, particularly the WHILE statement in SQL. Implicit loops and cursors are of no real concern in this for two reasons. First, they are implemented by SQL Server below the statement level and are thus as efficient as anything else in SQL Server. And secondly, their use by SQL Server is technically a procedural implementation of the declarative SQL commands that we have given it, which is entirely what is expected of a declarative programming environment.
Simplest Types of Cursor Routines
Initially we will look at the simplest cases of SQL cursors and Loops. To understand what these cases are and what makes them the simplest cases, consider this stereotypical example of a Cursor routine:
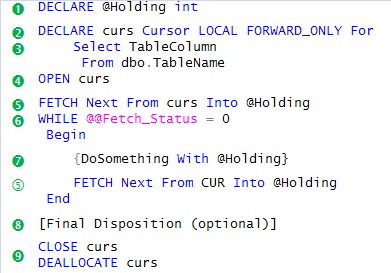
This simplest possible Cursor routine structure consists of the following parts:
- Preparation Statements: These are the statements that must be before the Cursor to prepare for it. They must include at a minimum at one or more holding variables to hold the columns returned by the Cursor.
- Declaration: Formally declares the Cursor variable and any options to be applied to it.
- SELECT Clause: This declares what data is to be returned and processed, one row at a time, by the Cursor. Although technically a part of the Cursor Declaration (2), I have labeled it separately because of its importance.
- OPEN Cursor Statement: Executes the SELECT Clause (3) and positions the Cursor at the beginning of the dataset.
- Fetch Next statement: Retrieves the next row in the dataset and sets the @@FETCH_STATUS variable. Note that the same FETCH statement typically appears twice, once to "prime" the WHILE loop and again at the end just before it loops.
- WHILE statement: This id the mechanism to process each record returned by the Cursor, it will exit when a Fetch Next statement sets the @@FETCH_STATUS to zero (meaning no more rows were found).
- Processing Statements: These are the statements that actually do something with the data returned in the holding variables.
- Final Disposition (optional): Frequently a cursor routine will require some statements collect all of the results of the processing statements and make some final disposition of them.
- Clean Up statements: The CLOSE and DEALLOCATE statements are theoretically independent, but they normally are written together and it is hard to conceive of any reason to separate them.
Virtually all Cursor routines follow this pattern or some variation of it. The determination of whether a Cursor routine qualifies as a "Simple" case rest almost entirely on the contents of Item (7) in this pattern. The simplest Cursor forms have:
- No more than one output table
- Processing statements (step 7) limited to: SET, SELECT, IF, DML's (INSERT, UPDATE and DELETE) and possibly, additional Cursor statements
- No state maintained between records and then reapplied as part of the output (see below)
"State" is information held in variables that are maintained from row to row and accumulate or are processed based on the current row and previous state values. For instance, in our homework problem the variable "@X" used to keep the count of total rows is an example of state, because it is maintained from row to row and it accumulates across the rows. Thus, simple as it is, the homework problem is not in the Simplest Cursor form.
Below is what may be the simplest Cursor routine ever:
Declare @firstname nvarchar(50) Declare @lastname nvarchar(50) Declare Curs Cursor STATIC LOCAL Forward_Only For Select Lastname, Firstname From Sales.vIndividualCustomer Open Curs; FETCH Next From Curs into @lastname, @firstname While @@Fetch_Status = 0 BEGIN PRINT @lastname + ', ' + @firstname FETCH Next From Curs into @lastname, @firstname END Close Curs Deallocate Curs
(NOTE: All code examples have been written to use the AdventureWorks database, unless otherwise stated)
This example is based on actual SQL code written by a developer (who shall remain anonymous) who was exceptionally proud to have figured out this entire routine on his own. However, he needed my help because although this routine did successfully list every customers name when he ran it in Query Analyzer, he could not get it to return any data to his application program. This is because the Print statement does not contribute to the normal result set returned to the client, but that was not the real problem here. Returning a table as a dataset is probably the simplest set-based declarative function there is, and yet somehow this developer had found a way to turn it into procedural code.
This incident was a real watershed moment for me. Somehow this developer had figured all of this out, the Declare, Open, Close and Deallocate Cursor statements, how to declare variables, Print, Fetch, the While statement and even how to specify the Select clause, without realizing that Select could be used outside of the Declare Cursor statement! And in the years since I have seen almost exact duplicates of this same routine in different online forums.
One of the most distinctive things about the simplest Cursor usages, is that it is hard to imagine why a Cursor was used in the first place. And yet, still these instances persist, frequently unchanged for years because many SQL developers, who know enough to realize that such routines should be rewritten, nonetheless are uncertain of how to approach it.
Cursor Conversion Methodology
The basic steps that we will use to convert a Cursor routine are as follows:
- Use the SELECT Clause of the Declare Cursor statement as the basis for our table source. For Selects and Inserts, we may be able to use the SELECT as-is. For Updates and Deletes, we will probably use the From and Where clauses.
- Any Set or Select statements in the While loop will become columns outputs.
- Any Containing IF statement, within the loop but containing everything else, will be added to our Where clause.
- Any IF statements around a single line will become a CASE function in out column outputs
Looking back at our basic Cursor template (above) we can see that the only sections that we retain from it are the SELECT clause (3), the processing statements (7), and sometimes the final Dispostion (8). Typically everything else is simply discarded as useless procedural housekeeping statements.
Now let's apply this methodology to our previous very simple example.
Just Put It In A Set, Brett
Transforming our example from procedural to declarative code is very simple, so simple, in fact that we only need the first step of our methodology to accomplish it. Instead of using the Select clause of a Cursor to enumerate our table into individual rows, we use the same Select as a statement to marshal the table as a set:
Select LastName, Firstname
From Sales.vIndividualCustomer
As it happens, this also fixes the problem of the client application not seeing any of the data.
Comparing the performance once again shows that the Cursor version is significantly slower:
| CPU msec | Logical Reads | Elapsed msec | |
|---|---|---|---|
| Set-based | 188 | 3,904 | 467 |
| Cusror | 500 | 78,711 | 610 |
And again, I don't think that there would be any argument about which was more readable, understandable and maintainable.
Learn To Use Where, Claire
Let's look at a similar though more typical example, also drawn from real life (in fact, all of the examples used in this series will be based on real life examples that, for several very good reasons, I have rewritten to be as generic as possible). This cursor routine was written to return any SalesOrders that have a detail row with the ProductID equal to the SpecialOfferID, because a newly discovered bug in the Order processing application may have erroneously written the ProductID to both fields.
DECLARE @Order as int , @Offer as int , @Product as int DECLARE @suspect Table(OrderID int , OfferID int , ProductID int) DECLARE Curs Cursor FORWARD_ONLY READ_ONLY STATIC LOCAL FOR Select SalesOrderID, SpecialOfferID, ProductID From Sales.SalesOrderDetail Order By SalesOrderID, ProductID OPEN Curs FETCH Next From Curs into @Order, @Offer, @Product WHILE @@FETCH_STATUS = 0 BEGIN IF @Product = @Offer Begin INSERT Into @suspect Values(@Order, @Offer, @Product) End FETCH Next From Curs into @Order, @Offer, @Product END Select * From @suspect; CLOSE Curs DEALLOCATE Curs
We can see several enhancements in this Cursor routine over the previous example. First, the developer has solved the PRINT problem by Inserting the individual records into a table variable instead and then after the loop is done, selecting all of the rows from the table variable. This is an example of a "Final Disposition" statement, which is section (8) from our Cursor template. Final disposition statements do not always appear in Cursor routines and when they do, we will not always need them in the transformed set-based version, as is true in this case.
Secondly, we can see that there is an IF statement in the body of the loop. This is a "Containing" IF statement which simply means that the entire row will be rejected if it does not meet the condition being tested. Finally, there is an Order By clause added to the Select statement.
So how do we convert this using our methodology? First we take the Select statement as the start of our declarative version:
Select SalesOrderID, SpecialOfferID, ProductID
From Sales.SalesOrderDetail
Order By SalesOrderID, ProductID
The Order By doesn't change anything logically here, so we take it along with the rest of the Select clause.
Next, because there is a containing IF statement, we add its logic to the Select statements Where clause:
Select SalesOrderID, SpecialOfferID, ProductID
From Sales.SalesOrderDetail
Where SpecialOfferID = ProductID
Order By SalesOrderID, ProductID
And finally, we can see that we do not need the disposition statement, because in set-based form we never needed the table variable, so this is our set-based version.
Comparing the performance shows the set-based version to be even faster relatively, than the previous conversions.
| CPU msec | Logical Reads | Elapsed msec | |
|---|---|---|---|
| Set-based | 16 | 1,241 | 11 |
| Cursor | 1,984 | 489,601 | 2,820 |
Coming in Part 3
In the next installment of the series, I will look at slightly more complex examples of simple Cursor routines and then move onto Cursor routines that do not quite fit in the template for simple Cursor routines. I will continue to show how each can be converted to declarative or set-based queries. I will also examine some of the reasons that developers give for using cursors in these cases.
Some readers may be eager for more difficult Cursor examples, so in that spirit, I leave you with the following challenge which is a more complicated version of the routine that we just transformed.
DECLARE @Order as int , @Customer as int , @DetailProduct as int , @OrderDetail as int DECLARE @suspect Table(OrderNo int , [LineNo] int , CustomerID int , ProductNo int) DECLARE Curs Cursor STATIC LOCAL READ_ONLY FOR Select SalesOrderID, CustomerID From Sales.SalesOrderHeader Order By SalesOrderID, CustomerID OPEN Curs FETCH Next From Curs into @Order, @Customer WHILE @@FETCH_STATUS = 0 BEGIN DECLARE Curs_Detl Cursor FORWARD_ONLY READ_ONLY STATIC LOCAL FOR Select SalesOrderID, SalesOrderDetailID, ProductID From Sales.SalesOrderDetail Where SalesOrderID = @Order Order By SalesOrderID, SalesOrderDetailID, ProductID OPEN Curs_Detl FETCH Next From Curs_Detl into @Order, @OrderDetail, @DetailProduct WHILE @@FETCH_STATUS = 0 Begin IF @DetailProduct = @Customer Begin INSERT Into @suspect Values(@Order, @OrderDetail, @Customer, @DetailProduct) End FETCH Next From Curs_Detl into @Order, @OrderDetail, @DetailProduct End CLOSE Curs_Detl DEALLOCATE Curs_Detl FETCH Next From Curs into @Order, @Customer
END CLOSE Curs
DEALLOCATE Curs Select * From @suspect;
The rules remain the same as before, first figure out what it is trying to do, then write a set-based version and finally measure the performance of both.
R. Barry Young is a Principal Consultant for Proactive Performance Solutions, Inc., a Microsoft Gold Certified Partner, located in northern Delaware. He has been programming for over 35 years, a computer professional for 30 years, a professional consultant for 25 years, a Systems Performance Analyst for 20 years and a Database Consultant for the last 15 years. He received his B.S. in Theoretical Mathematics specializing in Logic and Set Theory, which he was sure that he would never use.

