

Mistakes are embarrassing , especially when they are repetitions of things you should not have forgotten. Which blog post would you rather publish, one that sees you battle against the odds to solve a problem that flummoxed your colleagues, or one that gave you a generous portion of humble pie? Humble pie is doubly unpalatable as people are not slow to profess that they would not have made such an obvious mistake.
The pain of making mistakes means that we learn more from them than we ever do when things go according to plan. As Stephen King put it “A child doesn’t understand a hammer until he’s mashed his finger at a nail". The trick is to learn from other people's mistakes before you make your own. With that in mind I thought I would share some of my biggest mistakes so that you can avoid them.
How I deleted an entire fact table from a production data warehouse
When batch loading a data warehouse I find it useful to record the batch number against the records loaded into facts and dimensions and also against attempted file loads. This means that if a later problem is identified as being specific to a batch then all records for that batch can easily be removed. I record the timestamp when a file is picked up for processing and the time when it completes.
As the data warehouse is on column store technology the preference is to avoid UPDATE statements so in this particular case I used two tables
- Table One - Record the file processing start
- Table Two - Record the file processing end
The two tables are nearly identical, but as it happened, not nearly identical enough. I performed a DELETE FROM <table> WHERE <field> IN (subquery) only the subquery didn't do what I thought it would do. To simulate what happened I have mocked up an experiment whose results should scare the Bejesuz out of you.
First let us create two tables
IF EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='dbo' AND TABLE_NAME = 'star_wars_film')
BEGIN
DROP TABLE dbo.star_wars_film;
PRINT 'TABLE DROPPED: dbo.star_wars_film'
END
GO
IF EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='dbo' AND TABLE_NAME = 'purge_test')
BEGIN
DROP TABLE dbo.purge_test;
PRINT 'TABLE DROPPED: dbo.purge_test'
END
GO
CREATE TABLE dbo.star_wars_film (
film_id INT NOT NULL,
film_description varchar(50) NOT NULL,
CONSTRAINT pk_star_wars_film PRIMARY KEY CLUSTERED (film_id)
);
CREATE TABLE dbo.purge_test(
id INT NOT NULL,
purge_type INT NOT NULL
CONSTRAINT DF_purge_type DEFAULT 1,
purge_date DATETIME NOT NULL
CONSTRAINT DF_purge_date DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT pk_purge_test PRIMARY KEY CLUSTERED (id)
)
GOINSERT INTO dbo.purge_test(id) values(99);
INSERT INTO dbo.star_wars_film(film_id, film_description)
VALUES
(1,'Star Wars - The phantom menace') ,
(2,'Revenge of the Sith') ,
(3,'Attack of the clones') ,
(4,'A new hope'),
(5,'The empire strikes back'),
(6,'Return of the Jedi') ,
(7,'The force awakens'),
(8,'The last Jedi'),
(-1,'Rogue One');So, not only does dbo.purge_test NOT contain film_id it also DOES NOT CONTAIN an id value that is in our dbo.star_wars_film table.
Now for the DELETE statement that should scare you
-- Before the delete
SELECT * FROM dbo.star_wars_film ORDER BY film_id;
DELETE FROM dbo.star_wars_film
WHERE film_id IN (
SELECT film_id FROM dbo.purge_test WHERE purge_type=1
);
-- After the delete. Expect the same as before but it IS NOT!
SELECT * FROM dbo.star_wars_film ORDER BY film_id;- The absence of film_id should have caused an error
- The only id value in dbo.purge_test is 99 which doesn't match any id value in the dbo.star_wars_film table
SELECT film_id FROM dbo.purge_test WHERE purge_type=1 Msg 207, Level 16, State 1, Line 49 Invalid column name 'film_id'.
This is documented behaviour on MSDN however similar links exist for Oracle, Neteeza, PostGres.
This undesirable behaviour can be eliminated by aliasing the table in the subquery.
-- Change from
DELETE FROM dbo.star_wars_film
WHERE film_id IN (
SELECT film_id FROM dbo.purge_test WHERE purge_type=1
);
-- Change to
DELETE FROM dbo.star_wars_film AS F WHERE F.film_id in (
SELECT P.film_id FROM dbo.purge_test AS P WHERE P.purge_type=1
);Why was no error thrown? Because in the absence of any form of qualification the query recognises that dbo.star_wars_film DOES have a film_id and assumes that the sub-query is a correlated sub-query so can reference fields from the outer-query. In effect the query has been interpreted as the following:-
DELETE FROM dbo.star_wars_film WHERE film_id = film_id;
There are a few lessons to be learned from this:
- Using aliases is always a good idea, even when a query has a single table. I think this may be one of the very few absolutes in a world where "it depends" is the default.
- For any form of data change operation relying on a sub-query test the SELECT sub-query separately
- If any data change scenario can occur more than once then develop a template/script for it and subject it to thorough testing.
Why wasn't it picked up earlier? Put simply, the data available in the environments prior to production lacked the breadth and depth of data and that data was not adequate to reveal the observed scenario.
Generating suitable test data was not a straight forward process but the outcome of this mistake has resulted in two changes
- Time-consuming and difficult it may be but we have now designed a means of generating the minimal data required to flush out such problems.
- We have added an explicit set of tests to our arsenal of automated tests in order to spot similar errors in future.
How my embarrassing oversight caused problems with duplicates
In SQL Server constraints are enforced. You cannot violate a primary key or unique constraint, foreign keys will be honoured unless you explicitly delete or disable them and the same thing with check constraints.
I have been fortunate in that until recently the data I have to had to deal with has either come, in some manner, directly from a system with enforced constraints and been delivered to such a system.
In AWS Redshift constraints are simply metadata that is used to aid the query optimiser. You can violate constraints until your DBA soul cracks and dies. If your constraints do not work then the data that those constraints would protect you against will get into your database.
For loading a data warehouse I normally follow a simple pattern by dividing the warehouse into separate schemas
- Staging schema for landing data from operational systems
- Target schemas depending on the business subject being addressed and/or security concern
- Others not relevant to the embarrasment in question.
The problem I experienced was one where duplicate records in a dimension table caused reporting on facts to be inflated.
The diagram and query below illustrates how a LEFT JOIN can be used for sending records in the source (SRC) table that have not yet been inserted into the destination (DEST) table.

No matter how many times the insert statement is run it will only insert missing records into the destination table.
Now imagine that there is no enforced primary key on either the staging.star_wars_film or production.star_wars_film tables and the originating operational system is somewhat lax in its data validation.
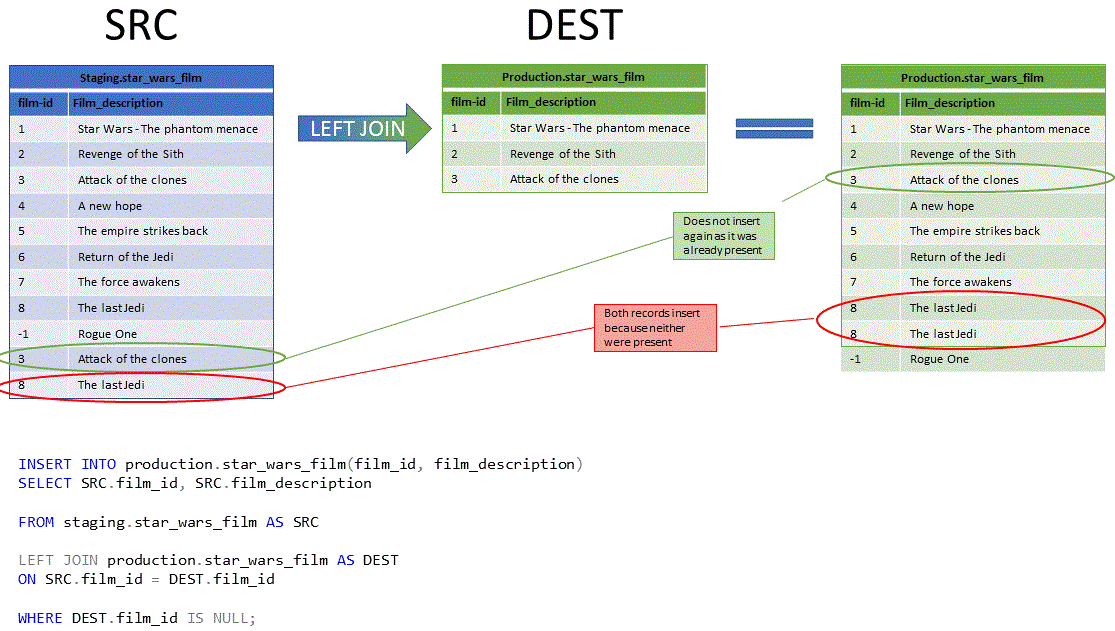
So why didn't I spot this problem much earlier?
In SQL Server (or any other database system with enforced constraints) we would have received errors when trying to load the staging table and the scenario above would never have arisen.
In much of my previous work data is received in an ordered fashion. You would not receive a sale before your received an order. This means that you can take a simple stepped approach as follows:
- Purge the staging table
- Load the staging table with the latest data supply
- Cleans and conform the data
- Use the LEFT JOIN approach to shift the data into the production tables.
The systems I work with today are extremely loosely coupled. The mechanism to send data to back end systems, such as the data warehouse, is a separate queuing mechanism decoupled from the front end operational systems and can deliver data subjects out of order. For some subjects this means that I have to retain staging records so they can be matched up with late arriving data and this makes the risk of double-loading data is a real possibility.
This scenario taught me that it is important to think through scenarios that would allow duplicate data to get into the staging tables.
- Can duplicated data be the result of loading data multiple times?
- Can duplicate data be as a result of the same data being supplied in different files?
- Can duplicate data be supplied in a single file?
In each case you must establish what criteria can be applied to ensure that only one of the duplicates can be copied across into production. Earlier on I mentioned that I always have a batch identifier for each load job. Where duplicates are caused by loading the same file multiple times I might have a rule that selects the record with the lowest batch number.
The other lesson was that I needed to think more carefully about data quality measuring and alerting. Given that AWS Red Shift (and others) do not enforce constraints the need for automated data quality checks becomes more important. As long as BI systems report good and/or credible news it is unlikely that anyone will check the veracity of the data. This means that errors are likely to go undetected for a considerable amount of time.
How I tripped over a similarity and created duplicate data
To my cost I have found that it is not the big differences that cause problems it is the subtle differences where equivalent functions are almost the same but not quite.
In the SQL Server world one of the tricks we have for comparing records containing large strings efficiently is to generate and store a CHECKSUM value for the string. This allows us to index an 4 byte integer instead of up to 900 bytes in the string.
Let us suppose that we want to create a dimension based on the HTTP user agent. It might look something like the one shown below.
| Field | Data type |
|---|---|
| user_agent_key | BIGINT |
| user_agent_checksum | INT |
| batch_load_id | BIGINT |
| http_user_agent | VARCHAR(2048) |
| browser_name | VARCHAR(60) |
| browser_version | VARCHAR(60) |
| os_name | VARCHAR(60) |
| os_version | VARCHAR(60) |
The key, checksum value and user agent are known up front. The browser and operating system information may require later updates.
In SQL Server the 900 byte limit would prevent us indexing the user agent at all so the 4 byte CHECKSUM value allows a dramatic improvement in matching string values when both the checksum and string value are used in the match. As AWS Redshift is a column store there are no indexes as such but the query optimiser can make use of the 4 byte value to aid matching the string.
Now consider the query below:
SELECT CHECKSUM(CONCAT('dave',CHAR(32)))
UNION
SELECT CHECKSUM(CONCAT('dave ',CHAR(32)))
UNION
SELECT CHECKSUM(CONCAT('DAVE ',CHAR(32)))On my SQL Server this produces a single record of value 830370430 showing that the CHECKSUM calculation does not care about trailing spaces or the case.
AWS Red Shift also has a CHECKSUM function. There are three crucial differences between the Red Shift implementation and the SQL Server implementation
- Red Shift CHECKSUM function is that it only works against fields and not literals.
- It is always case sensitive (as is almost everything in Red Shift)
- It includes trailing spaces in its calculation
The first two points were identified during development. The trailing space difference bit us later when further data feeder systems were added which did not trim off trailing spaces prior to sending information down stream.
I relearned a number of things from this particular error: -
- RTFM
- For any function that accepts a text string check what happens with trailing spaces, collations, case, nulls etc
- To communicate the findings out to development teams. In an earlier article I put forward the idea of a data quality crib sheet. I still believe that this has value.
Closing thoughts
I am most embarrassed by the 2nd illustration and I offer no excuses for it.
If you are used to working almost exclusively with one RDBMS then some of the behaviours with other systems can come as a rude shock. This is particularly true if you are looking after a data warehouse downstream of such systems.
There is a subtext to this article that you cannot trust the data that is supplied to you and should build systems that expect the worse. The connundrum this poses is that if the originating systems are infinitely scalable then how can a finitely scalable back end hope to cope with the processing required to validate and cleanse the incoming data? I find that as bad data proceeds down through the stack it gains momentum and mass and becomes increasingly unmanageable. Based on that experience I believe the only sustainable solution is in establishing the SDLC processes to prevent data problems in the first place. You won't prevent every problem but it is essentail to develop and nuture dialogue within and between teams and to work together to establish what is required to achieve suitable data quality.