We'll start with a brief review of the ideal storage architecture for the log file, for maximum log throughput, and then take a deeper look at how log fragmentation can affect the performance of operations that need to read the log, such as log backups, or the crash recovery process.
Finally, we'll consider best practices in managing log sizing and growth, and the correct response to explosive log growth and fragmentation.
Physical Architecture
The correct physical hardware and architecture will help ensure that you get the best possible log throughput, and there are a few "golden rules." Others have covered this before, notably Kimberly Tripp in her much-referenced blog post, 8 Steps to better Transaction Log throughput, (http://www.sqlskills.com/blogs/kimberly/post/8-Steps-to-better-Transaction-Log-throughput.aspx), so we won't go into great detail again here.
Note that in designing the underlying physical architecture for the log file, our primary goal is to optimize log write throughput. SQL Server writes to the log in response to every transaction that adds, removes or modifies data, as well as in response to database maintenance operations such as index rebuilds or reorganization, statistics updates, and more.
You only need one log file
There is no performance gain, in terms of log throughput, from multiple log files. SQL Server does not write log records in parallel to multiple log files. There's one situation when SQL Server will write to all the log files, and that's when it updates the header in each log file. The log header is a mirror of the database header page, and SQL Server writes to it to update various LSNs, such as the last checkpoint, the oldest open transaction, the last log backup, and so on. This sometimes tricks people into thinking that SQL Server is logging to all the log files, when it is only updating the header.
If a database has four log files, SQL Server will write log records to Log File 1, until it is full, then fill Files 2, 3 and 4, and then attempt to wrap back around and start writing to File 1 again. We can see this in action simply by creating a database with several log files (or by adding more files to an existing database). Listing 8.1 creates a Persons database, with a primary data file and two log files, each on a separate drive.
Data and backup file locations
All of the examples in this level assume that data and log files are located in 'D:\SQLData' and all backups in 'D:\SQLBackups', respectively. When running the examples, simply modify these locations as appropriate for your system (and note that in a real system, we wouldn't store data and log files on the same drive!).
Note that we've based the SIZE and FILEGROWTH settings for the data and log files on those for AdventureWorks2008. The code for this example (Listings 8.1 – 8.3) is in the YouOnlyNeed1Log.sql file, in the code download.
USE master
GO
IF DB_ID('Persons') IS NOT NULL
DROP DATABASE Persons;
GO
CREATE DATABASE [Persons] ON PRIMARY
( NAME = N'Persons'
, FILENAME = N'D:\SQLData\Persons.mdf'
, SIZE = 199680KB
, FILEGROWTH = 16384KB
)
LOG ON
( NAME = N'Persons_log'
, FILENAME = N'D:\SQLData\Persons_log.ldf'
, SIZE = 2048KB
, FILEGROWTH = 16384KB
),
( NAME = N'Persons_log2'
, FILENAME = N'C:\SQLData\Persons_log2.ldf'
, SIZE = 2048KB
, FILEGROWTH = 16384KB
)
GO
ALTER DATABASE Persons SET RECOVERY FULL;
USE master
GO
BACKUP DATABASE Persons
TO DISK ='D:\SQLBackups\Persons_full.bak'
WITH INIT;
GOListing 8.1: Create the Persons database with two log files.
Next, Listing 8.2 creates a sample Persons table.
USE Persons
GO
IF EXISTS ( SELECT *
FROM sys.objects
WHERE object_id = OBJECT_ID(N'dbo.Persons')
AND type = N'U' )
DROP TABLE dbo.Persons;
GO
CREATE TABLE dbo.Persons
(
PersonID INT NOT NULL
IDENTITY ,
FName VARCHAR(20) NOT NULL ,
LName VARCHAR(30) NOT NULL ,
Email VARCHAR(7000) NOT NULL
);
GOListing 8.2: Create the Persons table.
Now, we'll add 15,000 rows to the table and run DBCC LOGINFO. Note that in our tests, we filled the Persons table with data from the Person.Contact table in AdventureWorks 2005 database. However, the code download file contains alternative code, which will work with AdventureWorks2008 and AdventureWorks2012.
INSERT INTO dbo.Persons
( FName ,
LName ,
Email
)
SELECT TOP 15000
LEFT(aw1.FirstName, 20) ,
LEFT(aw1.LastName, 30) ,
aw1.EmailAddress
FROM AdventureWorks2005.Person.Contact aw1
CROSS JOIN AdventureWorks2005.Person.Contact aw2;
GO
USE Persons
GO
DBCC LOGINFO;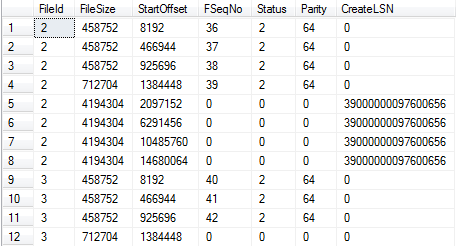
Listing 8.3: Populate Persons and check the VLFs.
SQL Server is sequentially filling the VLFs in the primary log file (FileID 2), followed by the secondary one (FileID 3). It has also auto-grown the primary log file (please refer back to Level 2 for a more detailed example of how SQL Server auto-grows the transaction log)
If we continue to add rows, SQL Server will continue to grow both files as required, and fill the VLFs sequentially, one VLF at a time. Figure 8.1 shows the situation after rerunning Listing 8.3 for 95,000 rows (110K rows added in total). Now we have 12 VLFs for the primary log file and 8 for the secondary log file.
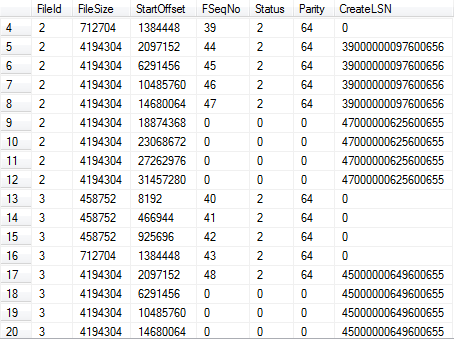
Figure 8.1: Sequential use of two log files.
In this situation, any operation that reads the log will start by reading a block of four VLFs in the primary log (FSeqNo 36-39), followed by four blocks in the secondary log (FSeqNo 40-43), followed four blocks in the primary log, and so on. This is why multiple log files can reduce I/O efficiency, as we'll discuss further in the next section.
The only reason to add an additional log file is in exceptional circumstances where, for example, the disk housing the log file is full (see Level 6) and we need, temporarily, to add an additional log file as the quickest means to get the SQL Server out of read-only mode. However, as soon as it's no longer required the additional file should be removed, as discussed later, in the section, What to Do If Things Go Wrong.
Use a dedicated drive/array for the log file
There are several reasons why it's a good idea to house the data files on separate disks from the log file. Firstly, this architecture offers better chances of recovery in the event of disk failure. For example, if the array housing the data files suffers catastrophic failure, the log file doesn't go down with the ship. We may still be able to perform a tail log backup, and so recover the database to a point very close the time of failure (See Level 5).
Secondly, it's a good idea to separate data file I/O from log file I/O in order to optimize I/O efficiency. SQL Server databases perform both random and sequential I/O operations. Sequential I/O is any form of I/O where SQL Server can read or write blocks without requiring repositioning of the disk head on the drive. SQL Server uses sequential I/O for read-ahead operations, and for all transaction log operations, and it is the fastest I/O type, using conventional disks.
Random I/O is any operation where reading or writing of blocks requires the disk head to change positions on the platter. This incurs seek latency I/O and reduces both throughput (MB/s) and performance (IOPS) relative to sequential I/O. Read operations in general, especially in OLTP systems, are random I/O operations, reading relatively small blocks of pages sequentially as a part of larger random I/O requests.
By separating mainly random from mainly sequential I/O, we avoid contention between the two, and improve overall I/O efficiency. Furthermore, the optimum configuration for log files is not necessarily the same as for the data files. By separating data and log files, we can configure each I/O subsystem as appropriate for that type of I/O activity, for example by choosing the optimal RAID configuration for the disk array (see the next section).
Finally, note that a single log file on a dedicated drive/array allows the disk head to stay more or less steady as SQL Server writes sequentially to the log. However, with multiple log files on a single drive/array, the disk head will need to jump between each log; we don't have sequential writes without disk seeks, and so we reduce the efficiency of sequential I/O.
Ideally, every database will have one log file on a dedicated disk array, though in many systems this remains an ideal rather than a practical reality.
For similar reasons, relating to sequential I/O efficiency, it's also important to defragment the physical disk drives before we create the log file.
Use RAID 10 for log drives, if possible
RAID, an acronym for Redundant Array of Independent Disks, is the technology used to achieve the following objectives:
- Increase levels of I/O performance, measured in Input/Output Operations Per Second (IOPS), which is roughly (
MB/sec/IOsizeinKB)*1024. - Increase levels of I/O throughput, measured in Megabytes Per Second (MB/sec) which is roughly (
IOPS*IOsizeinKB)/1024. - Increase storage capacity available in a single logical device – you can't purchase a single 5 TB disk yet, but you can have a 5 TB disk in Windows by, for example, using RAID to stripe six 1-TB drives in a RAID 5 array.
- Gain data redundancy through storing parity information across multiple disks, or using mirroring of the physical disks in the array.
The choice of RAID level is heavily dependent on the nature of the workload that the disk array must support. For example, as discussed earlier, the difference in the nature of the I/O workloads for data and log files means that different RAID configurations may be applicable in each case.
In terms of I/O throughput and performance, we should strive to optimize the log file array for sequential writes. Most experts acknowledge RAID1+0 as the best option in this regard, though it also happens to be the most expensive in terms of cost per GB of storage space.
Deeper into RAID
A full review the pros and cons of each RAID level is out of scope for this Stairway. For further information, we refer you to Chapter 2 of the book, Troubleshooting SQL Server, by Jonathan Kehayias and Ted Krueger (available as a paid-for paperback or free eBook): http://www.simple-talk.com/books/sql-books/troubleshooting-sql-server-a-guide-for-the-accidental-dba/.
RAID 1+0 is a nested RAID level known as a "striped pair of mirrors." It provides redundancy by first mirroring each disk, using RAID 1, and then striping those mirrored disks with RAID 0, to improve performance. There is a significant monetary cost increase associated with this configuration since only half of the disk space is available for use. However, this configuration offers the best configuration for redundancy since, potentially, it allows for multiple disk failures while still leaving the system operational, and without degrading system performance.
A common and somewhat cheaper alternative is RAID 5, "striping with parity," which stripes data across multiples disks, as per RAID 0, and stores parity data in order to provide protection from single disk failure. RAID 5 requires fewer disks for the same storage capacity, compared to RAID 1+0, and offers excellent read performance. However, the need to maintain parity data incurs a performance penalty for writes. While this is less of a problem for modern storage arrays, it's the reason why many DBAs don't recommend it for the transaction log files, which primarily perform sequential writes and require the lowest possible write latency.
If, as per our previous suggestion, you are able to isolate a single database's log file on a dedicated array, at least for those databases with the heaviest I/O workload, then it may be possible to use the more expensive RAID1+0 for those arrays, and RAID 5, or RAID 1, for lower workload databases.
To give an idea of the I/O performance offers by various RAID levels, following are three possible RAID configurations for a 400 GB database that performs a balanced mix of random read and write operations, along with the resulting theoretical I/O throughput rates, based on a 64K random I/O workload for SQL Server.
- RAID 1 using 2 x 600 GB 15K RPM disks =>185 IOPS at 11.5 MB/sec.
- RAID 5 using 5 x 146 GB 15K RPM disks =>345 IOPS at 22 MB/sec.
- RAID 10 using 14 x 73 GB 15K RPM disks => 1609 IOPS at 101 MB/sec.
Remember, though, that these numbers are theoretical, based only on the potential I/O capacity of the disks in a given configuration. They take no account of other factors that can, and will, have an impact on overall throughput, including RAID controller cache size and configuration, RAID stripe size, disk partition alignment, or NTFS format allocation unit sizes. The only way to be sure that your selected disk configuration will cope gracefully with the workload placed on it by your databases is to perform proper benchmarking of the I/O subsystem, prior to usage.
Benchmarking storage configurations for SQL Server
A number of tools exist for measuring the I/O throughput of a given configuration, the two most common tools being SQLIO (http://www.microsoft.com/download/en/details.aspx?id=20163) and IOmeter (http://www.iometer.org/). In addition, there is SQLIOSim, for testing the reliability and integrity of a disk configuration (http://support.microsoft.com/kb/231619/en-us).
Log Fragmentation and Operations That Read the Log
As discussed in Level 2, internally SQL Server breaks down a transaction log file into a number of sub-files called virtual log files (VLFs). SQL Server determines the number and size of VLFs to allocate to a log file, upon creation, and then will add a predetermined number of VLFs each time the log grows, based on the size of the auto-growth increment, as follows (though for very small growth increments it will sometimes add fewer than four VLFs):
- <64 MB – each auto-growth event will create 4 new VLFs
- 64MB to 1 GB = 8 VLFs
- >1 GB = 16 VLFs
For example, if we create a 64 MB log file and set it to auto-grow in 16 MB increments, then the log file will initially have 8 VLFs, each 8 MB in size, and SQL Server will add 4 VLFs, each 4 MB in size, every time the log grows. If the database attracts many more users than anticipated, but the file settings are left untouched then, by the time the log reaches 10 GB in size, it will have grown about 640 times, and will have over 2,500 VLFs.
Towards the other end of the scale, if we grow a log in 16 GB chunks, then each growth will add 16 VLFs, each 1 GB in size. With large VLFs, we risk tying up large portions of the log that SQL Server cannot truncate, and if some factor further delays truncation, meaning the log has to grow, the growth will be rapid.
The trick is to obtain the right balance. The maximum recommended auto-growth size is about 8 GB (advice offered by Paul Randal in his Log File Internals and Maintenance video, http://technet.microsoft.com/en-us/sqlserver/gg313762.aspx). Conversely, the growth increments must be large enough to avoid an unreasonably large number of VLFs.
There are two main reasons to avoid frequent small auto-grow events. One is that, as discussed in Level 7, log files cannot take advantage of instant file initialization, so each log growth event is relatively expensive, compared to data file growth, in terms of resources. A second is that a fragmented log can impede the performance of operations that read the log.
Many operations will need to read the transaction log, including:
- Full, differential and log backups – though only the latter will need to read substantial portions of the log.
- Crash recovery process – to reconcile the contents of data and log files, undoing the effects of any uncommitted transactions, and redoing the effects of any that were committed and hardened to the log, but not to the data files (see Level 1).
- Transactional replication – the transactional replication log reader reads the log when moving changes from the publisher to the distributor.
- Database mirroring – on the mirror database, the log gets read when transferring latest changes from the primary to the mirror.
- Creating a database snapshot – which required the crash recovery process to run.
DBBCCHECKDB– which creates a database snapshot when it runs.- Change Data Capture – which uses the transactional replication log reader to track data changes.
Ultimately, the question of a "reasonable" number of VLFs in a log file will depend on the size of the log. In general, Microsoft regards more than about 200 VLFs as a possible cause for concern, but in a very big log file (say 500 GB) having only 200 VLFs could also be a problem, with the VLFs being too large and limiting space reuse.
Transaction Log VLFs – too many or too few?
Kimberly Tripp's article discusses this topic in more detail: http://www.sqlskills.com/BLOGS/KIMBERLY/post/Transaction-Log-VLFs-too-many-or-too-few.aspx.
In order to get at least some idea of the size of the impact of a fragmented log on operations that need to read it, we'll run some tests to look at the impact on two processes that read the log extensively, namely log backups and the crash recovery process.
Disclaimer
The tests that follow in no way reflect the reality of busy multi-user databases running on server-grade hardware, with specific RAID configurations and so on. We ran them on an isolated SQL Server 2008 instance, installed on a virtual machine. Your figures are likely to vary, and the observed impact will obviously be lower for faster disks. The idea is simply to offer some insight into potential log fragmentation issues, and some pointers on how to investigate their potential impact.
Note, finally, that Linchi Shea has demonstrated a big effect on the performance of data modifications when comparing a database with 20,000 VLFs to one with 16 VLFs. See: http://sqlblog.com/blogs/linchi_shea/archive/2009/02/09/performance-impact-a-large-number-of-virtual-log-files-part-i.aspx.
Effect on log backups
In order to get some idea of the size of the impact of a fragmented log on a log backup, we'll create PersonsLots database, and deliberately create a small log file (2 MB) and force it to grow in very small increments to create a very fragmented log. We'll load some data, run a big update to generate many log records, and then perform a log backup and see how long it takes. We'll then run a similar test on a database where we've pre-sized the log file correctly. You will find the full code for each test in the code download files PersonsLots_LogBackupTest.sql and Persons_LogBackupTest.sql.
First, we create the PersonsLots database. Its log file is only 2 MB in size and will auto-grow in 2MB increments.
/*
mdf: initial size 195 MB, 16 MB growth
ldf: initial size 2 MB, 2 MB growth
*/USE master
GO
IF DB_ID('PersonsLots') IS NOT NULL
DROP DATABASE PersonsLots;
GO
-- Clear backup history
EXEC msdb.dbo.sp_delete_database_backuphistory @database_name = N'PersonsLots'
GO
CREATE DATABASE [PersonsLots] ON PRIMARY
( NAME = N'PersonsLots'
, FILENAME = N'C:\SQLData\PersonsLots.mdf'
, SIZE = 199680KB
, FILEGROWTH = 16384KB
)
LOG ON
( NAME = N'PersonsLots_log'
, FILENAME = N'D:\SQLData\PersonsLots_log.ldf'
, SIZE = 2048KB
, FILEGROWTH = 2048KB
)
GO
ALTER DATABASE PersonsLots SET RECOVERY FULL;
USE master
GO
BACKUP DATABASE PersonsLots
TO DISK ='D:\SQLBackups\PersonsLots_full.bak'
WITH INIT;
GO
DBCC SQLPERF(LOGSPACE) ;
--2 MB, 15% used
USE Persons
GO
DBCC LOGINFO;
-- 4 VLFsListing 8.4: Create the PersonsLots database.
Now, we're going to grow the log in lots of very small increments, as shown in Listing 8.5, in order to produce a very fragmented log file.
DECLARE @LogGrowth INT = 0;
DECLARE @sSQL NVARCHAR(4000)
WHILE @LogGrowth < 4096
BEGIN
SET @sSQL = 'ALTER DATABASE PersonsLots MODIFY FILE (NAME = PersonsLots_log, SIZE = ' + CAST(4096+2048*@LogGrowth AS VARCHAR(10)) + 'KB );'
EXEC(@sSQL);
SET @LogGrowth = @LogGrowth + 1;
END
USE PersonsLots
GO
DBCC LOGINFO
--16388 VLFs
DBCC SQLPERF (LOGSPACE);
-- 8194 MB, 6.3% fullListing 8.5: Creating a very fragmented log for PersonsLots.
Here we grow the log in 4,096 increments to a total size of 8 GB (4096+2048*4096 KB). The log will grow 4,096 times, adding 4 VLFs each time for a grand total of 4+(4096*4)= 16388 VLFs.
Now rerun Listing 8.2 to recreate the Persons table, but this time in the PersonsLots database, and then adapt Listing 8.3 to populate the table with 1 million rows. Now we're going to update the Persons table to create many log records. Depending on the specs of your machine, you may have time for a cup of coffee while Listing 8.6 runs.
USE PersonsLots
GO
/* this took 6 mins*/DECLARE @cnt INT;
SET @cnt = 1;
WHILE @cnt < 6
BEGIN;
SET @cnt = @cnt + 1;
UPDATE dbo.Persons
SET Email = LEFT(Email + Email, 7000)
END;
DBCC SQLPERF(LOGSPACE) ;
--8194 MB, 67% used
DBCC LOGINFO;
-- 16388 VLFsListing 8.6: A big update on the Persons table.
Finally, we're ready to take a log backup and see how long it takes. We've included the backup statistics in a comment after the backup code.
USE master GO BACKUP LOG PersonsLots TO DISK ='D:\SQLBackups\PersonsLots_log.trn' WITH INIT; /*Processed 666930 pages for database 'PersonsLots', file 'PersonsLots_log' on file 1. BACKUP LOG successfully processed 666930 pages in 123.263 seconds (42.270 MB/sec).*/
Listing 8.7: Log backup of PersonsLots (fragmented log).
For comparison, we'll repeat the same test, but this time we'll carefully size our database log to have a reasonable number of reasonably sized VLFS. In Listing 8.8, we recreate the Persons database, with an initial log size of 2 GB (= 16 VLFs, each 128 MB in size). We then manually grow the log, just three steps to 8 GB in size, comprising 64 VLFs (each roughly 128 MB in size).
USE master
GO
IF DB_ID('Persons') IS NOT NULL
DROP DATABASE Persons;
GO
CREATE DATABASE [Persons] ON PRIMARY
( NAME = N'Persons'
, FILENAME = N'C:\SQLData\Persons.mdf'
, SIZE = 2097152KB
, FILEGROWTH = 1048576KB
)
LOG ON
( NAME = N'Persons_log'
, FILENAME = N'D:\SQLData\Persons_log.ldf'
, SIZE = 2097152KB
, FILEGROWTH = 2097152KB
)
GO
USE Persons
GO
DBCC LOGINFO;
-- 16 VLFs
USE master
GO
ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 4194304KB )
GO
-- 32 VLFs
ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 6291456KB )
GO
-- 48 VLFs
ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 8388608KB )
GO
-- 64 VLFs
ALTER DATABASE Persons SET RECOVERY FULL;
USE master
GO
BACKUP DATABASE Persons
TO DISK ='D:\SQLBackups\Persons_full.bak'
WITH INIT;
GOListing 8.8: Create the Persons database and manually grow the log.
Now rerun Listings 8.2, 8.3 (with 1 million rows) and 8.6 exactly as for the previous test. You should find that, in the absence of any log growth events, Listing 8.6 runs a lot quicker (in half the time, in our tests). Finally, rerun a log backup.
USE master GO BACKUP LOG Persons TO DISK ='D:\SQLBackups\Persons_log.trn' WITH INIT; /*Processed 666505 pages for database 'Persons', file 'Persons_log' on file 1. BACKUP LOG successfully processed 666505 pages in 105.706 seconds (49.259 MB/sec). */
Listing 8.9: Log backup of the Persons database (non-fragmented log).
The effect on log backup time is relatively small, but reproducible, for this sized log, about a 15–20% increase in backup time for a log with 14,292 VLFs compared to one with 64, and of course, this is a relatively small database (albeit with a very heavily fragmented log).
Effect on crash recovery
In these tests, we investigate the effect of log fragmentation on crash recovery, since this process will require SQL Server to read the active log and redo or undo log records as necessary in order to return the database to a consistent state.
Lots of redo
In the first example, we reuse the PersonsLots database. Drop and recreate it, set the recovery model to FULL, take a full backup and then insert 1 million rows, as per previous listings. You can find the full code for the examples in this section in the files, PersonsLots_RedoTest.sql and Persons_RedoTest.sql, as part of the code download for this Stairway.
Now, before we update these rows, we're going to disable automatic checkpoints.
Never disable automatic checkpoints!
We're doing so here purely for the purposes of this test. It is not something that we in any way recommend during normal operation of a SQL Server database. See: http://support.microsoft.com/kb/815436 for more details.
When we commit the subsequent updates, we'll immediately shut down the database so that all of the updates are hardened to the log but not to the data file. Therefore, during crash recovery, SQL Server will need to read all of the related log records and redo all of the operations.
USE PersonsLots
Go
/*Disable Automatic checkpoints*/DBCC TRACEON( 3505 )
/*Turn the flag off once the test is complete!*/--DBCC TRACEOFF (3505)
/* this took 5 mins*/BEGIN TRANSACTION
DECLARE @cnt INT;
SET @cnt = 1;
WHILE @cnt < 6
BEGIN;
SET @cnt = @cnt + 1;
UPDATE dbo.Persons
SET Email = LEFT(Email + Email, 7000)
END;
DBCC SQLPERF(LOGSPACE) ;
--11170 MB, 100% used
USE PersonsLots
GO
DBCC LOGINFO;
-- 22340 VLFsListing 8.10: PersonsLots – disable automatic checkpoints and run update in an explicit transaction.
Now we commit the transaction and shut down.
/*Commit and immediately Shut down*/ COMMIT TRANSACTION; SHUTDOWN WITH NOWAIT
Listing 8.11: Commit the transaction and shut down SQL Server.
After restarting the SQL Server service, try to access PersonsLots, and you'll see a message stating that is in recovery.
USE PersonsLots Go /*Msg 922, Level 14, State 2, Line 1 Database 'PersonsLots' is being recovered. Waiting until recovery is finished.*/
Listing 8.12: PersonsLots is undergoing a recovery operation.
SQL Server has to open the log and read each VLF before it starts recovering the database. So the impact of many VLFs is that it could extend the time between SQL Server restarting the database, and the actual start of the recovery process.
Therefore, once the database is accessible, we can interrogate the error log for time between these two events, as well as the total recovery time.
EXEC sys.xp_readerrorlog 0, 1, 'PersonsLots'
/*
2012-10-03 11:28:14.240 Starting up database 'PersonsLots'.
2012-10-03 11:28:26.710 Recovery of database 'PersonsLots' (6) is 0%
complete (approximately 155 seconds remain).
2012-10-03 11:28:33.000 140 transactions rolled forward in database
'PersonsLots' (6).
2012-10-03 11:28:33.010 Recovery completed for database PersonsLots
(database ID 6) in 6 second(s)
(analysis 2238 ms, redo 4144 ms, undo 12 ms.)
*/Listing 8.13: Interrogate the error log for PersonsLots messages.
There were approximately 12.5 seconds between SQL Server starting up the database, and the start of the recovery process. This is why it's possible to see a database listed as "in recovery," without initially seeing any recovery messages in the error log. The recovery process then took under 7 seconds. Notice that, of the three recovery phases, SQL Server spent most time in redo.
Let's now repeat the same test with the Persons database (pre-sized log file).
USE Persons
Go
/*Disable Automatic checkpoints*/DBCC TRACEON( 3505 )
--DBCC TRACEOFF (3505)
USE Persons
Go
BEGIN TRANSACTION
DECLARE @cnt INT;
SET @cnt = 1;
WHILE @cnt < 6
BEGIN;
SET @cnt = @cnt + 1;
UPDATE dbo.Persons
SET Email = LEFT(Email + Email, 7000)
END;
DBCC SQLPERF(LOGSPACE) ;
-- 12288 MB, 87.2% used
USE Persons
GO
DBCC LOGINFO;
-- 96 VLFs
/*Commit and immediately Shut down*/
COMMIT TRANSACTION;
SHUTDOWN WITH NOWAITListing 8.14: Persons: disable automatic checkpoints, run and commit explicit transaction, shut down SQL Server.
Finally, we interrogate the error log again, for time between these two events, as well as the total recovery time.
EXEC sys.xp_readerrorlog 0, 1, 'Persons'
/*
2012-10-03 11:54:21.410 Starting up database 'Persons'.
2012-10-03 11:54:21.890 Recovery of database 'Persons' (6) is 0%
complete (approximately 108 seconds remain).
2012-10-03 11:54:30.690 1 transactions rolled forward in database
'Persons' (6).
2012-10-03 11:54:30.710 Recovery completed for database Persons
(database ID 6) in 3 second(s)
(analysis 2177 ms, redo 1058 ms, undo 10 ms.)
*/Listing 8.15: Interrogate the error log for Persons messages.
Note that this time there is less than 0.5 seconds between SQL Server starting up the database, and recovery beginning. The recovery process took just over 9 seconds.
Notice that in these tests we haven't created a situation in which all other things are equal, aside from the log fragmentation. For a start, the recovery process for the fragmented log database rolls forward 140 transactions, and in the second test, only rolls forward one.
However, it is clear from the tests that a fragmented log can significantly delay the onset of the actual database recovery process, while SQL Server reads in all of the VLFs.
Lots of undo
As an alternative example, we could execute our long update transaction, run a checkpoint and then shut down SQL Server with the transaction uncommitted, and see how long SQL Server takes to recover the database, first when the log is fragmented and then when it is not. In each case, this will force SQL Server to perform a lot of undo in order to perform recovery, and we'll see the effect, if any, of an internally fragmented log.
We won't show the full code for these tests here as we've presented it all previously, but it's available in the code download files for this Stairway (see PersonsLots_UndoTest.sql and Persons_UndoTest.sql).
/* (1) Recreate PersonsLots, with a fragmented log (Listing 8.4 and 8.5) (2) Create Persons table, Insert 1 million rows (Listings 8.2 and 8.3) */BEGIN TRANSACTION /* run update from listing 8.6*//*Force a checkpoint*/CHECKPOINT; /*In an second session, immediately Shutdown without commiting*/SHUTDOWN WITH NOWAIT
Listing 8.16: The "lots of undo" test on PersonsLots (fragmented log).
Repeat the same test for the Persons database (Listings 8.8, 8.2, 8.3, 8.16). Listing 8.17 shows the results from the error logs for each database.
/*
PersonsLots (fragmented log)
2012-10-03 12:51:35.360 Starting up database 'PersonsLots'.
2012-10-03 12:51:46.920 Recovery of database 'PersonsLots' (17) is 0%
complete (approximately 10863 seconds remain).
2012-10-03 12:57:12.680 1 transactions rolled back in database
'PersonsLots' (17).
2012-10-03 12:57:14.680 Recovery completed for database PersonsLots
(database ID 17) in 326 second(s)
(analysis 30 ms, redo 78083 ms, undo 246689 ms.)
Persons (non-fragmented log)
2012-10-03 13:21:23.250 Starting up database 'Persons'.
2012-10-03 13:21:23.740 Recovery of database 'Persons' (6) is 0%
complete (approximately 10775 seconds remain).
2012-10-03 13:26:03.840 1 transactions rolled back in database
'Persons' (6).
2012-10-03 13:26:03.990 Recovery completed for database Persons
(database ID 6) in 279 second(s)
(analysis 24 ms, redo 57468 ms, undo 221671 ms.)
*/Listing 8.17: Error log database startup and recovery information for PersonsLots and Persons.
For PersonsLots the delay between database startup and the start of recovery is over 11 seconds, whereas for Persons it is about 0.5 seconds.
The overall recovery times are much longer in these undo examples, compared to the previous redo examples. For PersonsLots, the total recovery time was 326 seconds, compared to 279 seconds for Persons, with the non-fragmented log.
Correct Log Sizing
We hope that the previous examples in this level demonstrate clearly that it is a very bad idea to undersize the transaction log and then allow it to grow in small increments. In addition, it is usually a bad idea to accept the auto-growth settings that a database will inherit from model, which is currently to grow in steps of 10% of the current transaction log size, because:
- Initially, when the log file is small, the incremental growth will be small, resulting in the creation of a large number of small VLFs in the log, causing the fragmentation issues discussed earlier.
- When the log file is very large, the growth increments will be correspondingly large. Since the transaction log has to be zeroed out during initialization, large growth events can take time and, if the log can't be grown fast enough, this can result in 9002 (transaction log full) errors and even in the auto-grow timing out and being rolled back.
The way to avoid issues relating to expensive log growth events, and log fragmentation, is simply to set the correct initial size for the log (and data) file, allowing for current requirements, and predicted growth over a set period.
Ideally, having done this, the log would never auto-grow, which isn't to say that we should disable the auto-growth facility. It must be there as a safety mechanism, but we should size the log appropriately so that we are not relying on auto-growth being the mechanism that controls log growth. We can configure the auto-growth settings explicitly to a fixed size that allows the log file to grow quickly, if necessary, while also minimizing the number of VLFs SQL Server adds to the log file for each growth event. As discussed previously, auto-growth events are expensive, due to zero-initialization. In order to minimize the chances of a time-out occurring during auto-growth, it's a good idea to measure how long it takes to grow the transaction log by a variety of set sizes, while the database is operating under normal workload, and based on the current IO subsystem configuration.
So, how do we size the log correctly? There is no easy answer. There is no sound logic behind suggestions such as "the log should be at least 25% of the size of the database." We must simply pick a reasonable size based on the following considerations, and then track log growth.
- Log must be big enough to accommodate largest single transaction, for example the largest index rebuild. This means the log must be bigger than the largest index in the database, to allow for logging requirements to rebuild the index under
FULLrecovery, and must be big enough to accommodate all activity that might occur concurrently while that largest transaction is running. - Log sizing must account for how much log is generated between log backups (e.g. in 30 minutes, or 1 hour).
- Log sizing must account for any processes that may delay truncation such as replication, where the log reader agent job may only run once per hour.
We must also remember to factor in log reservation. The logging subsystem reserves space when logging a transaction to ensure that the log can't run out of space during a rollback. As such, the required log space is actually greater than the total size of log records for the operation.
In short, a rollback operation logs compensation log records, and if a rollback were to run out of log space, SQL Server would have to be mark the database as suspect. This log reservation is not actually "used" log space, it's just a specific amount of space that must remain free, but it can trigger auto-growth events if the log fills to a point where the "used space + reserved space = log size," and it is counted as used space for the purposes of DBCC SQLPERF(LOGSPACE).
Hence, it is possible to see the space used reported by DBCC SQLPERF(LOGSPACE)drop after a transaction commits, even if the database is in FULL recovery model, and no log backup has run. To see this in action, we just need a FULL recovery model database with a table containing about 50K rows. We won't repeat the full code for that here, but it's included in the code download (Persons_LogReservation.sql).
BACKUP LOG Persons TO DISK='D:\SQLBackups\Persons_log.trn' WITH INIT; -- start a transaction BEGIN TRANSACTION DBCC SQLPERF(LOGSPACE) /*LogSize: 34 MB ; Log Space Used: 12%*/-- update the Persons table UPDATE dbo.Persons SET email = ' __ ' DBCC SQLPERF(LOGSPACE) /*LogSize: 34 MB ; Log Space Used: 87%*/COMMIT TRANSACTION DBCC SQLPERF(LOGSPACE) /*LogSize: 34 MB ; Log Space Used: 34%*/
Listing 8.18: Log reservation test.
Note that the log space used has dropped from 87% to 34%, even though this is a FULL recovery model database, and there was no log backup after the transaction committed. SQL Server has not truncated the log in this case, merely released the log reservation space, after the transaction committed.
Having set the initial log size, based on all of these requirements, and set a sensible auto-growth safety net, it's wise to monitor log usage, and set alerts for log auto-growth events, since, if we've done our job properly, they should be rare. Level 9 will discuss log monitoring in more detail.
What to Do If Things Go Wrong
In this final section, we'll consider appropriate action in the face of a bloated and fragmented log file. Perhaps a database only recently fell under our care; we've implemented some monitoring and realized that the log is almost full and that there isn't the capacity on its disk drive to accommodate an urgent index maintenance operation. We try a log backup but, for reasons we need to investigate further (see Level 7), SQL Server will not truncate the log. In order to buy some time, we add a secondary log file, on a separate disk, and the operation proceeds as planned.
We investigate why the log ballooned in size and it turns out to be an application leaving "orphaned transactions" in the database. The issue is fixed, and the next log backup truncates the log, creating plenty of reusable space.
The next question is "what next?" given that we now have a database with multiple log files and a principal log file that is bloated and likely to be highly fragmented.
The first point is that we want to get rid of that secondary log file as soon as possible. As noted previously, there is no performance advantage to having multiple log files and, now that it's no longer required, all it will really do is slow down any restore operations, since SQL Server has to zero-initialize the log during full and differential restore operations.
Run Listing 8.4 to re-create the PersonsLots database, followed by Listings 8.2 and 8.3 to create and populate the Persons table (we provide the complete script, PersonsLots_2logs.sql, in the code download).
Let's assume, at this point, the DBA adds a second 3 GB log file to accommodate database maintenance operations.
USE master GO ALTER DATABASE PersonsLots ADD LOG FILE ( NAME = N'PersonsLots_Log2', FILENAME = N'D:\SQLData\Persons_lots2.ldf' , SIZE = 3146000KB , FILEGROWTH = 314600KB ) GO
Listing 8.19: Adding a 3 GB secondary log file to PersonsLots.
Sometime later, we've fixed the problem that resulted in delayed log truncation, there is now plenty of reusable space in the primary log file and we no longer need this secondary log file, but it still exists. Let's restore the PersonsLots database.
USE master GO RESTORE DATABASE PersonsLots FROM DISK ='D:\SQLBackups\PersonsLots_full.bak' WITH NORECOVERY; RESTORE DATABASE PersonsLots FROM DISK='D:\SQLBackups\PersonsLots.trn' WITH Recovery; /*<output truncated>… Processed 18094 pages for database 'PersonsLots', file 'PersonsLots_log' on file 1. Processed 0 pages for database 'PersonsLots', file 'PersonsLots_Log2' on file 1. RESTORE LOG successfully processed 18094 pages in 62.141 seconds (2.274 MB/sec).*/
Listing 8.20: Restoring PersonsLots (with secondary log file).
The restore took over 60 seconds. If we repeat the exact same steps, but without adding the secondary log file, the comparative restore, in our tests, took about 8 seconds.
In order to remove the secondary log file, we need to wait until it contains no part of the active log. Since our goal is to remove it, it's permissible to shrink this secondary log file to zero (demonstrated shortly), and turn off auto-growth for this file, as this will "encourage" the active log to move swiftly back into the primary log file. It's important to note that this will not move any log records in the secondary log over to the primary log. (Some people expect this behavior because, if we specify the EMPTYFILE parameter when shrinking a data file, SQL Server will move the data to another data file in the same filegroup.)
Once the secondary log file contains no part of the active log, we can simply remove it.
USE PersonsLots GO ALTER DATABASE PersonsLots REMOVE FILE PersonsLots_Log2 GO
Listing 8.21: Removing the secondary log file.
This is one problem solved, but we may still have a bloated and fragmented primary log. While we should never shrink the log as part of our standard maintenance operations, as discussed in Level 7, it is permissible in situations such as this, in the knowledge that we have investigated and resolved the cause of the excessive log growth, and so shrinking the log should be a "one-off" event.
The recommended approach is use DBCC SHRINKFILE (see http://msdn.microsoft.com/en-us/library/ms189493.aspx) to reclaim the space. If we don't specify a target size, or specify 0 (zero) as the target size, we can shrink the log back to its original size (in this case, 2MB) and minimize fragmentation of the log file. If the initial size of the log was large, we wish to shrink the log smaller than this, in which case we specify a specific target_size, such as "1".
USE PersonsLots GO DBCC SHRINKFILE (N'PersonsLots_log' , target_size=0) GO

Listing 8.22: Shrinking the primary log file (partial success).
In the output from this command, we see the current database size (24128*8-KB pages) and minimum possible size after shrinking (256*8-KB pages). This is actually an indication that the shrink did not work fully. SQL Server shrank the log to the point where the last VLF in the file contained part of the active log, and then stopped. Check the messages tab for confirmation.
/*Cannot shrink log file 2 (PersonsLots_log) because the logical log file located at the end of the file is in use. (1 row(s) affected) DBCC execution completed. If DBCC printed error messages, contact your system administrator.*/
Perform a log backup and try again.
USE master GO BACKUP DATABASE PersonsLots TO DISK ='D:\SQLBackups\PersonsLots_full.bak' WITH INIT; GO BACKUP LOG PersonsLots TO DISK = 'D:\SQLBackups\PersonsLots.trn' WITH init USE PersonsLots GO DBCC SHRINKFILE (N'PersonsLots_log' , 0) GO

Listing 8.23: Shrinking the primary log file after log backup.
Having done this, we can now manually grow the log to the required size, as demonstrated previously in Listing 8.8.
Summary
We started with a brief overview of the physical architecture factors that can affect log throughput, such as the need to separate log file I/O onto a dedicated array, and choose the optimal RAID level for this array.
This level then emphasized the need to manage transaction log growth explicitly, rather than let SQL Server auto-growth events "manage" it for us. If we undersize the log, initially, and then let SQL Server auto-grow it in small increments, we'll end up with a fragmented log. Examples in the level demonstrated how this might affect the performance of any SQL Server operations that need to read the log.
Finally, we discussed the factors that determine the correct log size, and correct auto-growth increment for a given database, and we offered advice on how to recover from situation where a database suffers from multiple log files and an oversized and fragmented primary log.
The next level, the final one in this Stairway, will describe the various tools and techniques for monitoring log activity, throughput, and fragmentation.
Further Reading
- Manage the Size of the Transaction Log File
- The Trouble with Transaction Logs
http://thomaslarock.com/2012/08/the-trouble-with-transaction-logs/
- How to shrink the SQL Server log
http://rusanu.com/2012/07/27/how-to-shrink-the-sql-server-log/
- Multiple log files and why they're bad
http://www.sqlskills.com/BLOGS/PAUL/post/Multiple-log-files-and-why-theyre-bad.aspx
Acknowledgements
Many thanks to Jonathan Kehayias, who contributed the RAID section of this level.
