
I’ve intended this stairway to appeal to a range of expertise and knowledge levels about SQL Server. Some of what I describe will seem obvious to you but I aim to add information that will be new to even experienced DBAs or database developers: After all, some of the information surprised me. I will, however, be assuming a reasonable working knowledge of database objects and other types of metadata; in other words, what a view, table, function, procedure, schema, constraint and so on actually is.
In the first level, I explained what information is provided by SQL Server to access the metadata for your database, why it was there, and how you’d use it. I ended up by showing you how to find out the names of all the various database objects in the database. In the second part, I chose the topic of triggers because it is a database object that provides a good example of the sort of questions that come up, and the way that you can explore the metadata to answer those questions.
We will now tackle indexes, not just because they are important, but because they are a good example of a type of metadata, like a column or distribution statistic, that isn’t treated as an object within the metadata.
Indexes are absolutely essential to any relational database table. However, like butter on toast, it is possible to overdo them and thereby create a source of problems in databases. Sometimes you can over-index or under-index a table, or build duplicate indexes. Sometimes it is a matter of choosing a bad fillfactor, setting the ignore_dup_key option wrongly, creating an index that never gets used (but has to be maintained), missing indexes on foreign keys, or having a GUID as part of a primary key. In short, indexes in any busy database systems need regular maintenance and verification, and the catalog views are one of the most obvious way of doing these chores.
What indexes have you got?
So let’s start with a simple report on the indexes in your database, as in the following query.
SELECT convert(CHAR(50),object_schema_name(t.object_ID)+'.'
+object_name(t.object_ID)) AS 'The Table', i.name AS index_name
FROM sys.indexes AS i
INNER JOIN sys.tables t
ON t.object_id=i.object_id
WHERE is_hypothetical = 0 AND i.index_id <> 0;
Here are my results. Yours, of course, will vary.
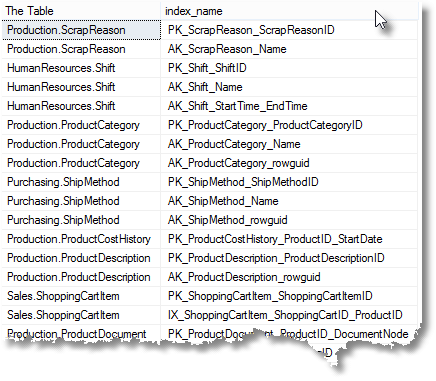
Why do we bother to join to sys.tables? This is because it is a handy way of ensuring that you get only user tables. We choose index_id values greater than zero, because if you don’t create a clustered index for a table there is still an entry here in sys.indexes but it refers to the heap and does not represent an index. Every table will have one row in sys.indexes with an index_id value of either 0 or 1. If the table has a clustered index, there will be a row with and index_id value of 1; if the table is a heap (which is just another way of saying the table has no clustered index), there will be a row with index_id value of 0. In addition, whether the table has a clustered index or not, there will be a row for each nonclustered index with an index_id value greater than 1. We have filtered out hypothetical indexes, , which are created by the Database Engine Tuning Advisor (DTA) merely to test out whether a possible index would be effective. It is a good idea to remove them if they accumulate.
This query, as with many others in this stairway, are of more practical use if you filter on one or more specific tables. You could, for example append this…
AND t.object_id = OBJECT_ID('Production.BillOfMaterials');
How many indexes does each table have, with a list of their names
The previous report isn’t entirely useful as you cannot see at a glance how many indexes each table has, and what they are. This will do the trick
SELECT convert(CHAR(20),object_schema_name(t.object_ID)+'.'
+object_name(t.object_ID)) AS 'The_Table',
sum(CASE WHEN i.object_ID IS NULL THEN 0 ELSE 1 END) AS The_Count,
coalesce(stuff((
SELECT ', '+i2.name
FROM sys.indexes i2
WHERE t.object_ID = i2.object_ID
ORDER BY i2.name
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,2,''),'') AS Index_List
FROM sys.tables AS t
LEFT OUTER JOIN sys.indexes i
ON t.object_id=i.object_id
AND is_hypothetical = 0 AND i.index_id > 0
GROUP BY t.Object_ID;
I’ve tested it on an aging version of the old pubs sample database because it doesn’t have ridiculously long object names.
The_Table The_Count Index_List -------------------- ----------- -------------------------------------------------- dbo.publishers 1 UPKCL_pubind dbo.titles 2 titleind, UPKCL_titleidind dbo.titleauthor 3 auidind, titleidind, UPKCL_taind dbo.stores 1 UPK_storeid dbo.sales 2 titleidind, UPKCL_sales dbo.roysched 1 titleidind dbo.discounts 0 dbo.jobs 1 PK__jobs__6E32B6A51A14E395 dbo.pub_info 1 UPKCL_pubinfo dbo.employee 2 employee_ind, PK_emp_id dbo.authors 2 aunmind, UPKCL_auidind (11 row(s) affected)
Finding tables without a clustered index
There is a lot of interesting things you can find out about indexes. Here, for example, is a quick way of finding tables without clustered indexes (heaps)
-- list all tables by name that have no clustered Index
SELECT object_schema_name(sys.tables.object_id)+'.'
+object_name(sys.tables.object_id) AS 'Heaps'
FROM sys.indexes /* see whether the table is a heap */ INNER JOIN sys.tables ON sys.tables.object_ID=sys.indexes.object_ID
WHERE sys.indexes.type = 0;
How many rows in each index?
By linking with the sys.partitions view, we can find out the approximate number of rows in the index. I’ve included some code at the end that joins with sys.extended_properties just to pull out any comments attached to these indexes.
--list the number of rows for each index/heap SELECT OBJECT_SCHEMA_NAME(t.object_id)+'.'+OBJECT_NAME(t.object_id) as 'Table', coalesce(i.NAME,'(IAM for heap)') as 'Index', Coalesce( (SELECT SUM(s.rows) FROM sys.partitions s WHERE s.object_id = i.object_id AND s.index_id = i.index_ID ), 0) 'Rows',coalesce(ep.Value,'') as comments FROM sys.tables t INNER JOIN sys.indexes i ON i.object_id = t.object_id LEFT OUTER JOIN sys.Extended_Properties ep ON i.Object_Id = ep.Major_Id AND i.Index_Id = Minor_Id AND Class = 7;
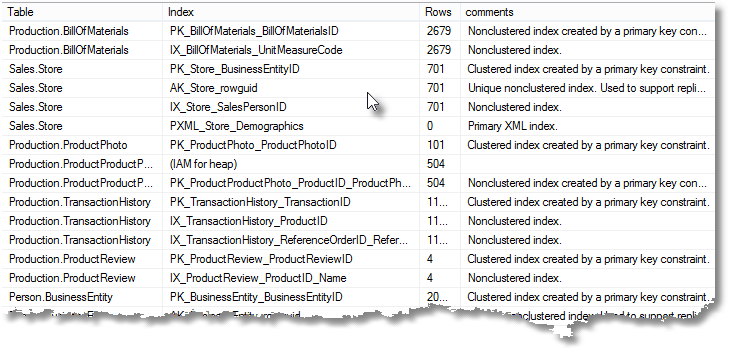
And you can vary this to tell you simply how many rows each table has, based on the rows in the indexes for that table
SELECT OBJECT_SCHEMA_NAME(t.object_id)+'.'+OBJECT_NAME(t.object_id) AS 'Table', sum(rows) AS row_count FROM sys.partitions p INNER JOIN sys.tables t ON p.object_ID=t.object_ID WHERE index_id < 2 GROUP BY t.object_ID,Index_ID;
Are there a lot of indexes in any table?
If you are suspicious about some tables having a lot of indexes you can use this query that tells you the tables with more than four indexes and an index count greater than half the column count. It is an arbitrary way of selecting tables with a lot of indexes and there can be valid reasons for having them.
--tables with more than three indexes
--and an index count greater than half the column count
SELECT object_schema_name(TheIndexes.Object_ID) + '.'+ object_name(TheIndexes.Object_ID) AS TableName,
Columns, Indexes
FROM
(SELECT count(*) AS indexes, t.object_ID
FROM sys.indexes i
INNER JOIN sys.tables t
ON i.object_ID=t.object_ID
GROUP BY t.object_ID) TheIndexes
INNER JOIN
(SELECT count(*) AS columns, t.object_ID
FROM sys.columns c
INNER JOIN sys.tables t
ON c.object_ID=t.object_ID
GROUP BY t.object_ID)TheColumns
ON TheIndexes.object_ID=TheColumns.object_ID
WHERE indexes>columns/2 AND indexes>4;
The final line ‘WHERE indexes>columns/2 AND indexes>4;’ needs to be changed as required to meet your criteria for ‘a lot of indexes’
Indexes updated but not read
It is always worth finding out which indexes haven’t been used since the server was last started, especially if the server has been doing a wide variety of work. There can be a good reason for an index not being used since a restart, as when it is useful only for end-of-month reporting.
--Indexes updated but not read.
SELECT
object_schema_name(i.Object_ID) + '.'+ object_name(i.Object_ID) as Thetable,
i.nameAS 'Index'
FROM sys.indexes i
left outer join sys.dm_db_index_usage_stats s
ON s.object_id = i.object_id
AND s.index_id = i.index_id
AND s.database_id = DB_ID()
WHERE OBJECTPROPERTY(i.object_id, 'IsUserTable') = 1
AND i.index_id > 0 --Exclude heaps.
AND i.is_primary_key = 0 --and Exclude primary keys.
AND i.is_unique = 0--and Exclude unique constraints.
AND coalesce(s.user_lookups + s.user_scans + s.user_seeks,0) = 0 --No user reads.
AND coalesce(s.user_updates,0) > 0; --Index is being updated.
(Note that we’ve used the dynamic management view sys.dm_db_index_usage_stats here which collects the usage information. We’ll discuss this object, and other related ones, in more detail later, but for the time being just admire it.)
How much space are these indexes taking?
I wonder how much space these indexes are taking up. It is worth checking a fat index where a lot of columns are used, or included, in an index as it is possible that the column values aren’t actually specified in any query.
SELECT object_schema_name(i.Object_ID) + '.'+ object_name(i.Object_ID) AS Thetable, coalesce(i.name,'heap IAM')AS 'Index', convert(DECIMAL(9,2),(sum(a.total_pages) * 8.00) / 1024.00)AS 'Index_MB' FROM sys.indexes i INNER JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id WHERE objectproperty(i.object_id, 'IsUserTable') = 1 GROUP BY i.object_id, i.index_id, i.name;
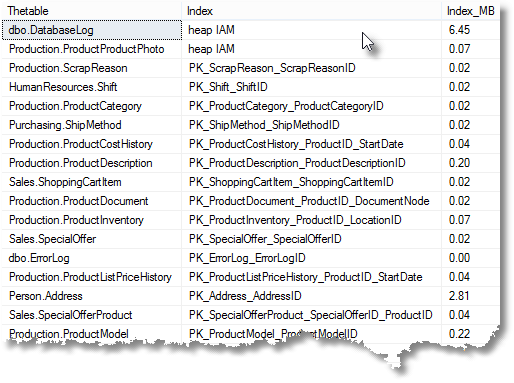
How do I calculate the total index space per table.
Let’s see what the total index space is for each table, along with the number of rows in the table.
SELECT object_schema_name(i.Object_ID) + '.'+ object_name(i.Object_ID) AS Thetable, convert(DECIMAL(9,2),(sum(a.total_pages) * 8.00) / 1024.00)AS 'Index_MB', max(row_count) AS 'Rows', count(*) AS Index_count FROM sys.indexes i INNER JOIN (SELECT object_ID,Index_ID, sum(rows) AS Row_count FROM sys.partitions GROUP BY object_ID,Index_ID)f ON f.object_ID=i.object_ID AND f.index_ID=i.index_ID INNER JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id WHERE objectproperty(i.object_id, 'IsUserTable') = 1 GROUP BY i.object_id;
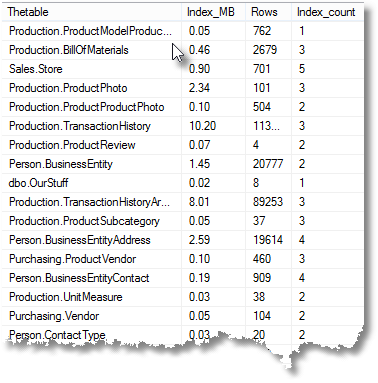
How do I discover the various ways that tables are using indexes?
In order to discover certain properties about your indexes, it is often better to use property functions as a shortcut.
-- list the names of all tables that have no primary key
SELECT object_schema_name(object_id)+'.'+object_name(object_id) as No_Primary_key
FROM sys.tables/* see whether the table has a primary key */ WHERE objectproperty(OBJECT_ID,'TableHasPrimaryKey') = 0;
-- list all tables by name that have no indexes at all
SELECT object_schema_name(object_id)+'.'+object_name(object_id) as No_Indexes
FROM sys.tables /* see whether the table has any index */ WHERE objectproperty(OBJECT_ID,'TableHasIndex') = 0;
-- list all tables by name that have no candidate key (enforced unique set of columns)
SELECT object_schema_name(object_id)+'.'+object_name(object_id) as No_Candidate_Key
FROM sys.tables/* if no unique constraint then it isn't relational */ WHERE objectproperty(OBJECT_ID,'TableHasUniqueCnst') = 0
AND objectproperty(OBJECT_ID,'TableHasPrimaryKey') = 0;
--list all tables with disabled indexes
SELECT distinct
object_schema_name(object_id)+'.'+object_name(object_id) as Has_Disabled_indexes
FROM sys.indexes /* don't leave these lying around */ WHERE is_disabled=1;
What is, and isn’t an object?
You have probably noticed something odd. Although some of the properties of tables, such as their primary keys, are objects in their own right, this isn’t true of columns, statistics or indexes. Let’s just get this clear, because it isn’t entirely intuitive: In sys.objects, you can find the basic standard details about all the common database components, such as tables, views, synonyms, foreign keys, check constraints, key constraints, default constraints, service queues, triggers and procedures. All these components that I’ve listed have additional attributes that have to be made visible through views that inherit the relevant basic attributes, but also include the data columns that are pertinent to the object. It is better to use these special views because they have all the information you need and the system filters just the type of object that you’re interested in, such as a table. Various objects, such as constraints and triggers, have a parent_ID in the sys.objects table that is non-zero, showing that they are child objects.
The following query shows you a simple way of viewing these child objects and relate them to their parents.
--view the names of all parent objects and their child objects.
SELECT parent.name AS Parents_name,
child.name AS Childs_Name,
replace(lower(parent.type_desc),'_',' ') AS Parents_type,
replace(lower(child.type_desc),'_',' ') AS Childs_type
FROM sys.objects child
INNER JOIN sys.objects parent
ON parent.object_ID=child.parent_object_id
WHERE child.parent_object_id<>0
ORDER BY parents_name;
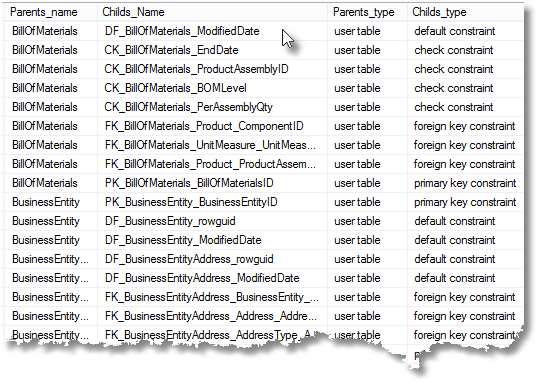
You’ll see that indexes just aren’t objects. In our first query, the object_ID that we returned was the ID of the table on which the index was defined.
The problem here is that the relationships are complex. A constraint can involve several columns and can be enforced by an index too. The index can involve several columns but order is important. Statistics can also involve several columns or could be associated with an index. This means that sys.indexes, sys.stats and sys.columns don’t inherit from sys.objects. The same is true for parameters and types.
How do I simply get to see all the columns, for all the indexes, for every table?
The simplest way of establishing what indexes are on a table and the columns referenced, in order, is to use a query that joins between sys.tables, sys.indexes and sys.index_columns.
--find all the columns for all the indexes for every table
SELECT object_schema_name(t.object_ID)+'.'+t.name AS The_Table, --the name of the table
i.name AS The_Index, -- its index
index_column_id,
col_name(Ic.Object_Id, Ic.Column_Id) AS The_Column --the column
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_ID=i.object_ID
INNER JOIN sys.Index_columns ic
ON i.Object_ID=ic.Object_ID
AND i.index_ID=ic.index_ID
ORDER BY t.name,i.index_id, index_column_id;
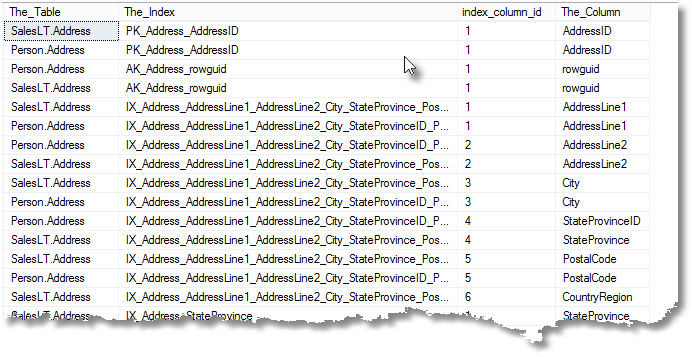
This will be more useful to you once you filter for a particular table. E.g.
WHERE i.object_id = OBJECT_ID('Production.BillOfMaterials');
What columns are in my indexes, and in what order?
We can do better than the previous query and have a line for each table, listing out all the indexes, and for each index, a list of its columns. This is easier for a busy programmer to scan by eye.
--list all tables with indexes, listing each index (comma-delimited), with a
--list of their columns in brackets.
SELECT object_schema_name(t.object_ID)+'.'+t.name AS The_Table, --the name of the table
coalesce(stuff (--get a list of indexes
(SELECT ', '+i.name
+' ( '
+stuff (--get a list of columns
(SELECT ', ' + col_name(Ic.Object_Id, Ic.Column_Id)
FROM sys.Index_columns ic
WHERE ic.Object_ID=i.Object_ID
AND ic.index_ID=i.index_ID
ORDER BY index_column_ID ASC
FOR XML PATH(''), TYPE).value('.', 'varchar(max)'),1,2,'') +' )'
FROM sys.indexes i
WHERE i.object_ID=t.object_ID
FOR XML PATH(''), TYPE).value('.', 'varchar(max)'),1,2,''),'') AS Indexes
FROM sys.tables t;
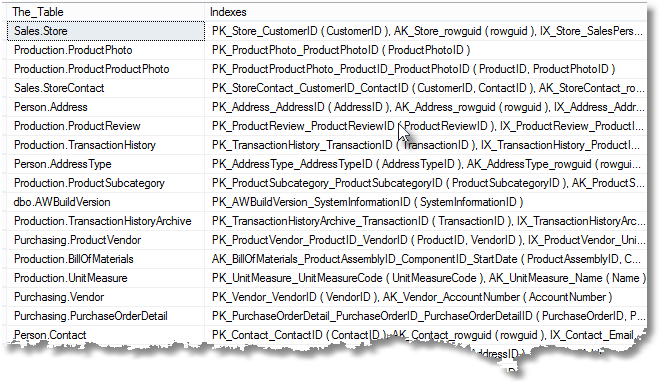
How can I view my XML indexes?
XML indexes are treated as an extension to indexes. I find that the best way of viewing their details is to construct a CREATE statement for them.
SELECT 'CREATE' + case when secondary_type is null then ' PRIMARY' else '' end
+ ' XML INDEX '+coalesce(xi.name,'')+ '
ON ' --what table and column is this XML index on?
+ object_schema_name(ic.Object_ID)+'.'+object_name(ic.Object_ID)
+' ('+col_name(Ic.Object_Id, Ic.Column_Id)+' )
'+ coalesce('USING XML INDEX [' + Using.Name + '] FOR ' + Secondary_Type_DeSc
COLLATE database_default,'')
+'
'+ replace('WITH ( ' +
stuff(
CASE WHEN xi.Is_Padded <> 0 THEN ', PAD_INDEX = ON ' ELSE '' END
+ CASE
WHEN xi.Fill_Factor NOT IN (0, 100)
THEN ', FILLFACTOR =' + convert(VARCHAR(3), xi.Fill_Factor) + ''
ELSE '' END
+ CASE WHEN xi.Ignore_dUp_Key <> 0 THEN ', IGNORE_DUP_KEY = ON' ELSE '' END
+ CASE WHEN xi.Allow_Row_Locks = 0 THEN ', ALLOW_ROW_LOCKS = OFF' ELSE '' END
+ CASE WHEN xi.Allow_Page_Locks = 0 THEN ', ALLOW_PAGE_LOCKS = OFF' ELSE ' ' END
, 1, 1, '')
+ ')', 'WITH ( )', '') --create the list of xml index options
+ coalesce('/* '+convert(varchar(8000),Value)+ '*/','')--and any comment
AS BuildScript
FROM sys.xml_Indexes xi
inner join sys.index_columns ic
ON ic.Index_Id = xi.Index_Id
AND ic.Object_Id = xi.Object_Id
LEFT OUTER JOIN sys.Indexes [USING]
ON [USING].Index_Id = xi.UsIng_xml_Index_Id
AND [USING].Object_Id = xi.Object_Id
LEFT OUTER JOIN sys.Extended_Properties ep
ON ic.Object_Id = ep.Major_Id AND ic.Index_Id = Minor_Id AND Class = 7
WHERE object_schema_name(ic.Object_ID) <>'sys' AND ic.index_id>0;
The results of the query above will show you all the essential XML index details as a build script.
CREATE PRIMARY XML INDEX PXML_ProductModel_CatalogDescription
ON Production.ProductModel (CatalogDescription )
/* Primary XML index.*/
CREATE PRIMARY XML INDEX PXML_ProductModel_Instructions
ON Production.ProductModel (Instructions )
/* Primary XML index.*/
CREATE PRIMARY XML INDEX PXML_Store_Demographics
ON Sales.Store (Demographics )
/* Primary XML index.*/
CREATE PRIMARY XML INDEX PXML_Person_AddContact
ON Person.Person (AdditionalContactInfo )
/* Primary XML index.*/
CREATE PRIMARY XML INDEX PXML_Person_Demographics
ON Person.Person (Demographics )
/* Primary XML index.*/
CREATE XML INDEX XMLPATH_Person_Demographics
ON Person.Person (Demographics )
USING XML INDEX [PXML_Person_Demographics] FOR PATH /* Secondary XML index for path.*/
CREATE XML INDEX XMLPROPERTY_Person_Demographics
ON Person.Person (Demographics )
USING XML INDEX [PXML_Person_Demographics] FOR PROPERTY /* Secondary XML index for property.*/
CREATE XML INDEX XMLVALUE_Person_Demographics
ON Person.Person (Demographics )
Are there other types of index stored in the metadata?
There are two more special kinds of indexes, the spatial indexes (information held in sys.spatial_index_tessellations and sys.spatial_indexes)
and the fulltext indexes (information held in fulltext_index_fragments, fulltext_index_catalog_usages, fulltext_index_columns and fulltext_indexes). These types of indexes are rather more advanced topics for this level. We’ll deal with them later in this stairway.
Exploring Index Statistics
For the time being, let’s just end up our exploration of indexes by dealing with the topic of distribution statistics or ‘stats’. Every index has a statistics object attached to it in order to help the query optimiser come up with a decent query plan. To do this, it needs to estimate the ‘cardinality’ of the data to determine how many rows will be returned for any index value, and it uses these ‘stats’ objects to tell it how the data is distributed.
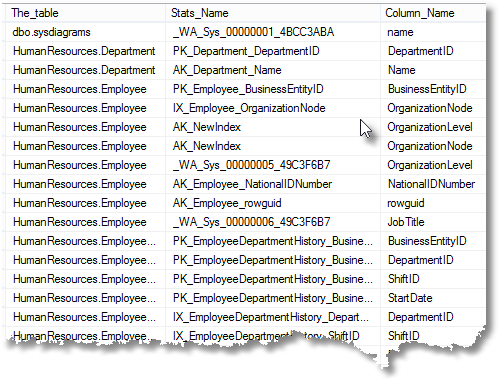
You can see what stats objects are associated with your tables in your database from a query like this:
SELECT object_schema_name(t.Object_ID) + '.'+ t.name AS The_table,
stats.name AS Stats_Name, sys.columns.name AS Column_Name
FROM sys.stats
INNER JOIN sys.stats_columns
ON stats.object_id = stats_columns.object_id
AND stats.stats_id = stats_columns.stats_id
INNER JOIN sys.columns
ON stats_columns.object_id = columns.object_id
AND stats_columns.column_id = columns.column_id
INNER JOIN sys.tables t
ON stats.object_id = t.object_id;
You’ll see that, when they are associated with an index, statistics inherit the name of the index, and use the same columns as that index.
Checking for duplicate statistics
You can quickly see if you have more than one statistic for the same column or set of columns just by comparing the list of column numbers that each statistic is associated with.
SELECT object_schema_name(Object_ID)+'.'+object_name(Object_ID) as tableName,
count(*) as Similar, ColumnList as TheColumn,
max(name)+', '+min(name) as duplicates
FROM
(SELECT Object_ID, name,
stuff (--get a list of columns
(SELECT ', ' + col_name(sc.Object_Id, sc.Column_Id)
FROM sys.stats_columns sc
WHERE sc.Object_ID=s.Object_ID
AND sc.stats_ID=s.stats_ID
ORDER BY stats_column_ID ASC
FOR XML PATH(''), TYPE).value('.', 'varchar(max)'),1,2,'') AS ColumnList
FROM sys.stats s)f
GROUP BY Object_ID,ColumnList
HAVING count(*) >1;

This shows you the tables that have duplicate statistics objects on them, In this case the sales.customer table has two similar statistics objects on the AccountNumber column
Summary
There is a lot of information available on indexes that is useful to the database programmer. Once the number of tables in a database gets large, it is very easy to let a table slip in that has something wrong, such as inadvertently having no clustered index or primary key, or that has duplicatedindexes or unnecessary statistics. Once you are familiar with the basic ways of querying the catalog views, it becomes quicker to run a query to get information than to use the SQL Server Management Studio.
