

Introduction
Special characters are one of those necessary evils. When working with multiple source systems wouldn't it be nice if everyone could agree on what characters were acceptable. In addition many times the errors associated with the problem have nothing to do with identifying the character, but are related to the issue it is causing. These issues manifest as odd characters on a report, off center titles, screens not opening, orders failing to get created and the list goes on. The reality is that even if you have a great deal of control over the data, this stuff always sneaks in.
Over the years I have compiled a small library of queries that I hope you will find as useful as I have. What I do is run them against the data every morning and send out emails to those responsible so they can correct them before the issue starts to manifest.
Setting up our samples
The script below will create a table with 2 columns. The first column is a description of the key component we are looking at in the 2nd column. So the “EXAMPLE_TYPE” can be “SPACE AT END” and “THE_TEXT” has a piece of text with a space at the end (‘Zombieland ‘).
IF (SELECT OBJECT_id(N'TEST_DATA','U')) IS NOT NULL
DROP TABLE TEST_DATA;
GO
CREATE TABLE TEST_DATA (
EXAMPLE_TYPE_DESC NVARCHAR(60)
,THE_TEXT NVARCHAR(60) COLLATE Latin1_General_CS_AS
)
INSERT INTO TEST_DATA
(EXAMPLE_TYPE_DESC,THE_TEXT)
VALUES
('ORIGINAL','Zombieland'),
('SPACE AT END','Zombieland '),
('SPACE AT START', ' Zombieland'),
('SPACE AT START AND END', N' Zombieland '),
('SPECIAL CHARACTERS - CARRAGE RETURN LINE FEED','Zombieland' + CHAR(13) + CHAR(10)),
('SPECIAL CHARACTERS - APOSTROPHE','Zombie''s Land'),
('SPECIAL CHARACTERS - # SYMBOL','35 Zombie Land Apt. #13'),
('SPECIAL CHARACTERS /','This and/or that'),
('SPECIAL CHARACTERS \','This and\or that'),
('SPECIAL CHARACTERS MULTIPLE SPACES','35 Zombie Land Apt 13'),
('ACCENTS','Régie du logement - Gouvernement du Québec'),
('ACCENTS','Ça va');
GOAlso, look at a number of the problems. I created character expressions with spaces at the beginning and end as well as added special characters (“/”,”#”) in the middle. Make a special note of line 10. It has multiple spaces between “Zombie” and “Land”. This particular error/issue will come up later.
One last thing, the collation of the THE_TEXT is Latin1_General_CS_AS. This means the column is case and accent sensitive.
Collation
A full examination of collation is out of the scope of this article. If you need further information here is a good place to start. There is however some basic things you should know. Collation is SQL Server’s way of knowing how to sort and compare data. For example: are stings case insensitive or not (is "ZombieLand" = "zombieland"?) or are a string’s accent sensitive or not (is Ça = Ca). For now that should be enough. I will discuss this in a bit more detail later.
Let’s investigate a couple of methods in which to find out what is happening in these strings.
Using LEN()/DATALENGTH() to find leading and trailing spaces
The LEN() function gives you the number of characters in a character string but it trims the trailing empty spaces. I put that in bold and italics for a reason. It is not mentioned in the Microsoft Technet article and it is not very intuitive. See below.
SELECT
LEN('Zombieland') AS NORMAL
,LEN('Zombieland ') AS EXTRA_SPACES;  |
The DATALENGTH() function tells you the number of bytes used to make a character string. So for ASCII character strings that use 1 byte per character, the LEN and DATALENGTH() should be equal. For UNICODE character strings, which use 2 bytes per character, DATALENGTH() is 2X the LEN(). Let’s look at an example.
SELECT 'Zombieland' AS ORIGINAL
,LEN('Zombieland') AS 'LEN()'
,DATALENGTH('Zombieland') AS 'DATALENGTH()'
,LEN(N'Zombieland') AS 'LEN() UNICODE'
,DATALENGTH(N'Zombieland') AS 'DATALENGTH() UNICODE';  |
As you can see, all things being equal, and with no trailing spaces, LEN() & DATALENGTH() will return the same number for ASCII and UNICODE character expressions. The DATALENGTH is 2X that of the ASCII for the Unicode character string.
Armed with that knowledge, let’s write a query that will locate all of the strings that have a space at the beginning and the end.
SELECT
EXAMPLE_TYPE_DESC
,THE_TEXT
,LEN(LTRIM(THE_TEXT)) AS N'LEN() OF TRIMMED'
,DATALENGTH(THE_TEXT) AS N'DATALENGTH()'
FROM TEST_DATA
WHERE LEN(LTRIM(THE_TEXT)) <> DATALENGTH(THE_TEXT);  |
If you were searching a UNICODE character expression you would replace the DATALENGTH(THE_TEXT); in the where clause with DATALENGTH(THE_TEXT)/2;
Looking over the query you can see that we needed to trim leading spaces with LTRIM() (LEN() trimmed the trailing spaces for us as part of its behavior). Technically what is left is a proper character string. As we stated before, the LEN() and DATALENGHT() (or DATALENGHT()/2 for UNICODE) of a proper character string is the same. If it is not we need to report it.
Complex Pattern Matching with LIKE Operator
Is there a way to find character strings that do not match (or do match) what we consider a valid character string?
Some of you may be familiar with regular expressions. SQL Server does not support regular expressions natively. (There are ways to get that working but that is out of the scope of this article.) If you don’t know what regular expressions are, and want to learn, you can look here. Never the less, the LIKE operator gives us enough syntax to be able to match most of what you will ever need.
Let’s take a moment to go over the 4 basic wild card expressions the LIKE operator provides:
Character | Description | Example |
% | Matches any sting of 0 or more characters | WHERE THE_TEXT LIKE (‘%land%’) would find all of the character strings with the word “land” in them. |
_ | Any single character | WHERE THE_TEXT LIKE (‘_at’) would find all the 3 letter character strings ending in at. Such as hat, sat, fat, cat, 8at, &at or any first character. |
[] | Any single character within a range | WHERE THE_TEXT LIKE (‘[A-Z]%’) would find all the character strings with a capital letter as the first character. Note that this means case sensitivity. |
[^] | Any single character not within the specified range. | WHERE THE_TEXT LIKE (‘^[0-9]%’) would find all the character strings that do not start with a digit. |
We are now going to do something that may seem a bit counter intuitive. We are going to make a list of all the characters that are valid. Why? In my experience there are usually far fewer valid characters than invalid. If you look over the list for ANSII (256 different characters) and UNICODE (110,187 different characters) you will see that is really the way to go. Here is my typical list and this comes out of my experience. Yours may be very different but it this gives you a place to start.
- Any lower case character [a-z]
- Any upper case character [A-Z]
- Any number [0-9]
- Any space “ “ (not multiple spaces-just one)
- Period “.”
- Ampersand “&”
- Open Bracket “(“
- Close Bracket “)”
- Underscore “_”
- Dash “-“
Therefore anything outside of these characters could potentially be an issue.
Let’s start slowly by finding all of the character expressions having a character other than a letter or number. Put another way LIKE '%[^a-zA-Z0-9]%'. Notice that you do not need to separate each group with a comma.
SELECT
EXAMPLE_TYPE_DESC
,THE_TEXT
FROM TEST_DATA
WHERE
THE_TEXT LIKE '%[^a-zA-Z0-9]%'; 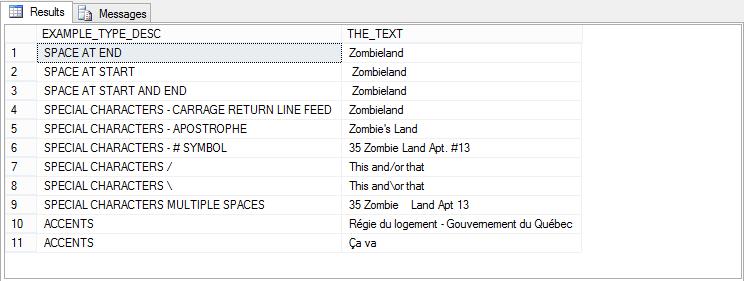
A funny thing happens. We get everything back but one row. This is because with the exception of the top row (“Zombieland”), everything else has a least one character outside of a letter or number.
Let’s extend our expression by using the space “ “ character. After all, it is valid except at the beginning and end of our character expression.
SELECT
EXAMPLE_TYPE_DESC
,THE_TEXT
FROM TEST_DATA
WHERE
THE_TEXT LIKE '%[^a-zA-Z0-9 ]%' |
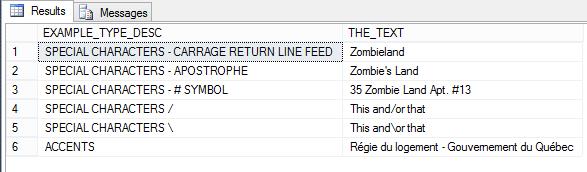
As you can see, you just need to add the characters to the list that you feel are valid and the query will return everything that has at least one character that doesn’t match. Also notice that “Ça va” is missing. If the column is case sensitive, should that not have been captured? Again this is not a course on regular expressions but note: the regular expression does not see the accented characters as special. Meaning (é and e) or (Ä and A) are evaluated as the same, as far as the expression is concerned. Take a look at the query and results below.
SELECT 'IT WORKS'
WHERE 'Ç' COLLATE SQL_Latin1_General_CP1_CI_AS = N'C' COLLATE SQL_Latin1_General_CP1_CI_AS;
SELECT 'IT WORKS'
WHERE 'Ç' COLLATE SQL_Latin1_General_CP1_CI_AI = N'C' COLLATE SQL_Latin1_General_CP1_CI_AI;
SELECT 'IT WORKS'
WHERE 'Ç' COLLATE SQL_Latin1_General_CP1_CI_AS LIKE ('%C%');
SELECT 'IT WORKS'
WHERE 'Ç' COLLATE SQL_Latin1_General_CP1_CI_AS LIKE ('%[A-Za-z]%'); 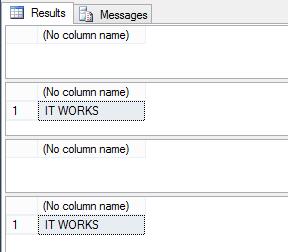
Notice that when the collation is accent insensitive (AI) or we use the regular expressions, it works. This might seem like odd behavior because the column was defined as accent sensitive. This could be good news or bad news depending on what you want. If you work in a country whose language has accents this probably works for you. This is because the accented characters would be seen as valid and that would be most of us. If that is a problem you can add an (OR THE_TEXT LIKE'%[ENTER ACCENTED CHARACTERS HERE]%') to the WHERE clause. Remember if the collation is case sensitive you will have to add the accents for upper and lower case. This all breaks down for binary collation but that is out of the scope of this article.
So putting it all together my starting query usually looks something like this:
SELECT
EXAMPLE_TYPE_DESC
,THE_TEXT
FROM TEST_DATA
WHERE
THE_TEXT LIKE '%[^a-zA-Z0-9.&( )_-]%';  |
But as you may notice we don’t have everything. What about the line with multiple spaces?
The multiple space problem
Remember the last row (10) in our table had multiple spaces between “zombie” and “land”. That by itself is usually not a problem but if you have multiple spaces between words it can be. The simple solution is to add another LIKE to the WHERE clause that checks for two consecutive spaces. This makes sense, because if you search for 2 consecutive spaces, and there are more, say 5, your query will still evaluate to true. This is because 5 spaces has 2 spaces in it.
SELECT
EXAMPLE_TYPE_DESC
,THE_TEXT
FROM TEST_DATA
WHERE
THE_TEXT LIKE '%[^a-zA-Z0-9.&( )_-]%'
OR
THE_TEXT LIKE '% %';| |
Putting it all Together
Now we need to put it all together. Your final version would look like the table below. We use the OR operator because we are searching for any of these expressions to be true. If the reasoning for this is not clear you can read over the Technet article on Operator Precedence here.
SELECT
EXAMPLE_TYPE_DESC
,THE_TEXT
FROM TEST_DATA
WHERE
LEN(LTRIM(THE_TEXT)) <> DATALENGTH(THE_TEXT) --LEN() does not match DATALENGTH()
OR
THE_TEXT LIKE '%[^a-zA-Z0-9.&( )_-]%' --At least one character is invalid
OR
THE_TEXT LIKE '% %'; --There are more than 2 consecutive spaces  |
Conclusion
Special characters can be a tricky problem. This is mostly because what is special in one system is not in another. Using LEN() and DATALENGTH() you can match trimmed character strings to see if they are of equal length. The LIKE operator provides enough pattern matching to be very useful. The point to remember when choosing what patterns to match, is the list of acceptable characters is much smaller than unwanted characters and therefore a more efficient place to start. You can always add more to your pattern later. Collation will also play a roll here so it is important to know how all of your data is collated.
