

Replication: SQL Server 2000– Table of Contents
driving the information age. In many Internet applications, a large number of
users who are geographically dispersed may routinely query and update the same
database. In this environment, the location of the data can have a significant
impact on application response time and availability. A centralized approach
manages only one copy of the database. The centralized approach suffers from
two major drawbacks:
- Performance problems due to high server load or high communication latency for
remote clients.
- Availability problems caused by server downtime or lack of connectivity.
Clients in portions of the network that are temporarily disconnected from the
server cannot be serviced.
locations. Using replication you create copies of the Database and share the
copy with different users so that they can make changes to their local copy of
database and later synchronize the changes to the source database.
- Users working in different geographic locations can work with their local copy
of data thus allowing greater autonomy.
- Database replication can also supplement your disaster-recovery plans by
duplicating the data from a local database server to a remote database server.
If the primary server fails, your applications can switch to the replicated
copy of the data and continue operations.
- You can automatically back up a database by keeping a replica on a different
computer. Unlike traditional backup methods that prevent users from getting
access to a database during backup, replication allows you to continue making
changes online.
- You can replicate a database on additional network servers and reassign users
to balance the loads across those servers. You can also give users who need
constant access to a database their own replica, thereby reducing the total
network traffic.
- Database-replication logs the selected database transactions to a set of
internal replication-management tables, which can then be synchronized to the
source database. Database replication is different from file replication, which
essentially copies files.
and processes in replication architecture. Publishing industry publishes
Magazines/Books; there are Distributors and Agents who carry these publications
to the Subscribers. Subscriber of the magazine obtains copies of the
publication and read the articles of interest to him; this is how SQL Server
Replication model works. Figure 1 depicts the typical Publishing industry flow.
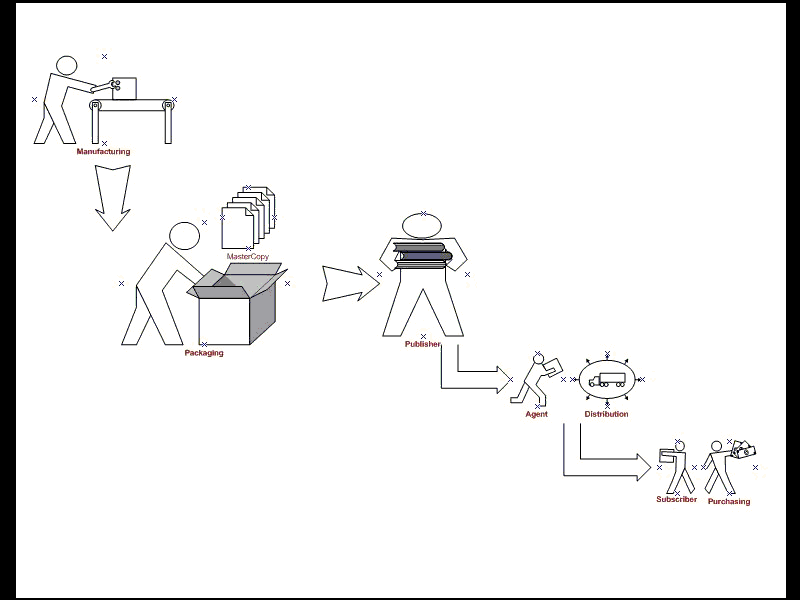
replication model.
- Publisher
- Distributor
- Agent
- Subscriber
- Articles
- Publications
- Subscriptions
servers. In addition to making data available for replication, publisher also
identifies what data has changed at the subscriber during the synchronizing
process. Depending on the type of the replication, changed data is identified
at different instances. We will learn more about Replication types in the
Replication.
varies depending on the type of replication. Two types of Distributors are
identified, remote distributor and Local distributor. Remote distributor is
separate from publisher and is configured as distributor for replication. Local
distributor is a server that is configured as publisher and distributor.
between Publisher and subscriber. There are different types of Agents
supporting different replication types.
Modifications to the data at subscriber can be propagated back to the
publisher; in some cases Subscriber may re-publish the data to the other
subscribers.
filtered), Views, Indexed views, Stored Procedures, User defined functions.
replicated.
Subscription Types:
via PUSH subscription or PULL subscription.
all the changes to the subscriber without subscriber asking for those changes.
of the publisher.
- Snapshot Replication
- Transactional Replication
- Merge Replication
copies and distributes data and database objects exactly as they appear at
current moment in time.
- The changes to data at subscriber are not updated to the subscriber
continuously
- Subscribers are updated with complete modified data and not by individual
transactions
- Propagating the changes to the subscribers takes more time as it is one time
process or scheduled process.
- Data/Db objects are static or does not change frequently
- Replicate Look Up tables that do not change frequently
- Amount data to be replicated is small
- Users often work in disconnected mode, and are not always interested with
latest data.
transactional replication, modifications to the publication at the publisher
are propagated to the subscriber incrementally.
- Publisher and the subscriber are always in synchronization
- Transaction boundaries are preserved, i.e. if there modification to 5 rows of
data, either all the 5 modified rows are propagated to the subscriber or none
- The publisher and the subscriber should be connected always.
- Replicating Database with rollup information, Database with regional, central
sales or inventory database that is updated and replicated to different sites.
- Subscribers always need the latest data for processing
Transactional replication. The initial snapshot applied to the subscribers and
then SQL server tracks changes to the data at publisher and subscriber. The
data is synchronized on scheduled basis or on demand. Since data modifications
are made independently at publisher and subscriber, conflicts are likely to
occur during synchronizing.
- Updates to the data are made independently at more than one server
- Data is merged on scheduled basis or on demand
- Allows users to work online/offline and synchronize the publisher and
subscriber on scheduled basis or on demand.
- Site autonomy is very critical
- Multiple subscribers need to update the data at same time or different time and
propagate the changes to the publisher
implementation of replication. There are different ways by which you can
implement and monitor replication based on different replication types. But in
general replication has following general steps:
- Configuring replication
- Generating and applying initial snapshot
- Modifying replicated data
- Synchronizing and propagating data
- Configure the publisher and distributor. Distributor can be same server or
different server
- Create publications based on data, sub sets of data and database objects
- Determine the type of replication to use, the subscriber database and location
of the snapshot file
- Configure when the synchronization will occur and options that will be used
with publications
- Create push and/or pull subscriptions at either the publisher or the subscriber
and configure your replication schedule and options
snapshot file location. After subscription is created when the snapshot is
applies is based on configured schedule when creating publication or snapshot
can be applied manually
in the snapshot file location
will be able to modify the data after the snapshot has been applied and
propagate the changes back to the publisher or other subscribers.
and publisher. How the data is synchronized is dependent on the type of
replication used.
- Incase of snapshot replication, snapshot file is reapplied at the subscriber
- Incase of transactional replication all data modification through Insert/Update
and Delete and distributed between publisher and subscriber
- Incase of merge replication data modification at various servers are merged,
conflicts if any are detected and resolved.
during replication. These Data types and properties are:
- Identity range management
- Unique identifier and Timestamp data types
- NOT FOR REPLICATION option
Identity range management:
rows are added to the column table. In replication where publication contains
identity columns following configurations can be used to manage Identity
columns
Publisher and 501 to 1000 for the same publication at Subscriber, with
threshold of 80%
and a newly inserted row at subscriber will have identity from 501 to 1000
In this case if the identity value reaches 400 at the Publisher and new inserts
after that will use the new identity range from 1001 to 1500.
will have Identity range from 1501 to 2000
updates at the subscriber and synchronization schedule. Setting threshold to a
lower value will result in many unused Identity values.
explicitly.
- Sp_adjustpublisheridentityrange
- Sp_addmergearticle
FOR REPLCIATION option on Identity column. When an identity column is specified
as NOT FOR REPLCATION, then its range should be provided programmatically. When
this option is set, SQL server retains the original values set by the
replication agent but continues to increment the value of the Identity column
in a normal value, i.e. without resetting the Identity value.
Enterprise Manager. For this example I would consider the standard PUBS
database.
1. Set Up right login for Replication
- To set up replication, you must use a login account that is a member of SQL
Server's Process Administrators (or higher authority) server role. I used “sa”
and it worked.
2. Configuring Server for Publishing, Subscribers and Distributor.
- Under SQL Server enterprise manager navigate to Tools/Replication menu, run
Configure Publishing and Distribution Wizard.
- Select your server as Publisher, Distributor and Subscriber server
- Specify the location where snapshots from publishers that use this distributor
will be stored.
- Configure your server with default settings or apply custom settings, in this
example I would use the default settings.
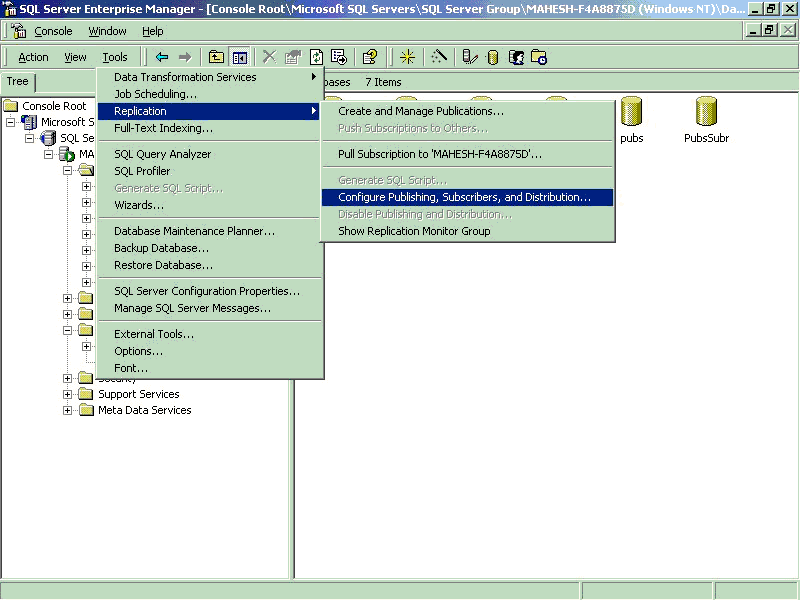
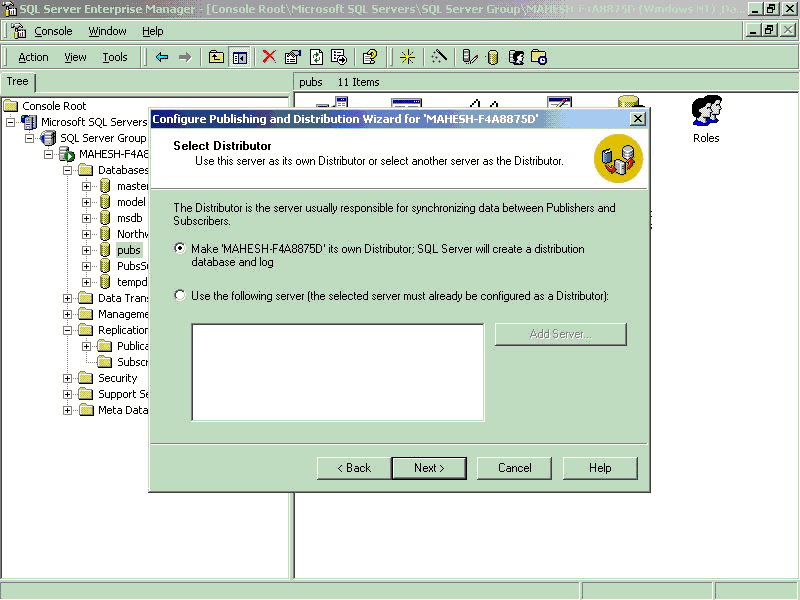
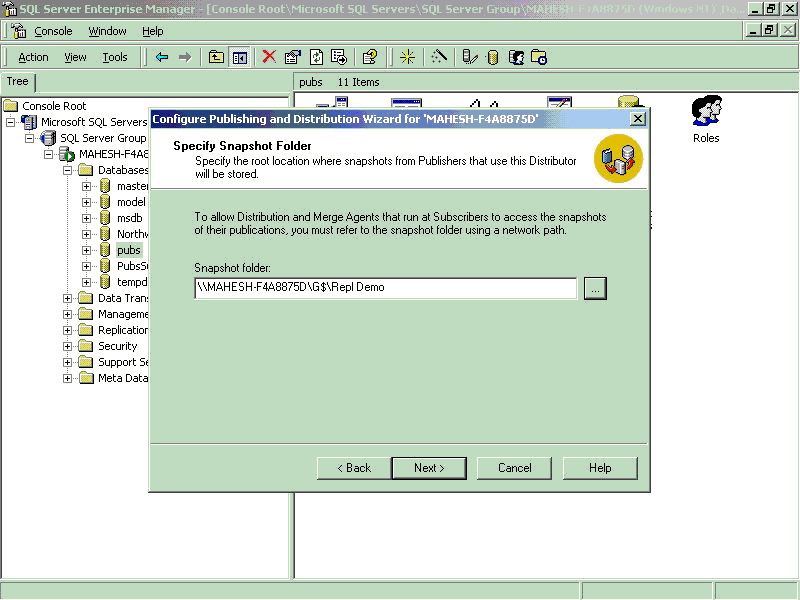
to create Publishers and Subscribers. This process will also create a New
Distribution Database under the selected server.
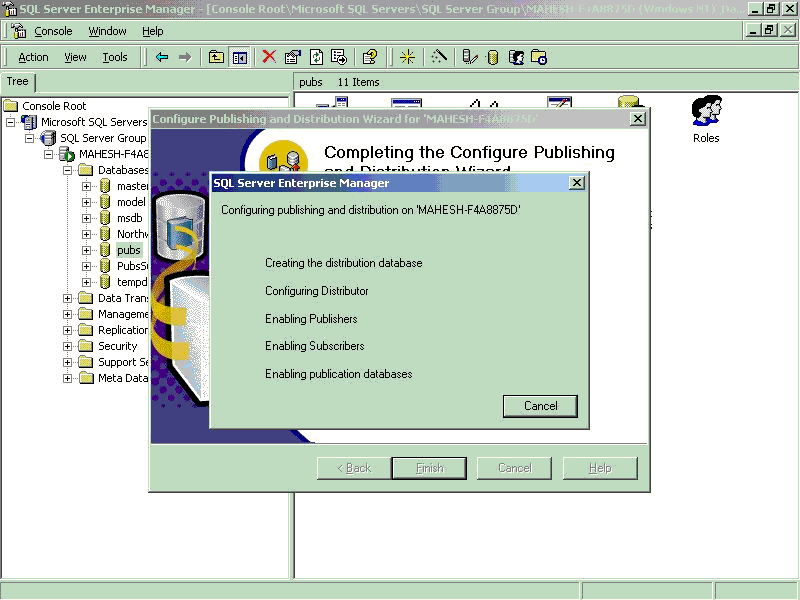
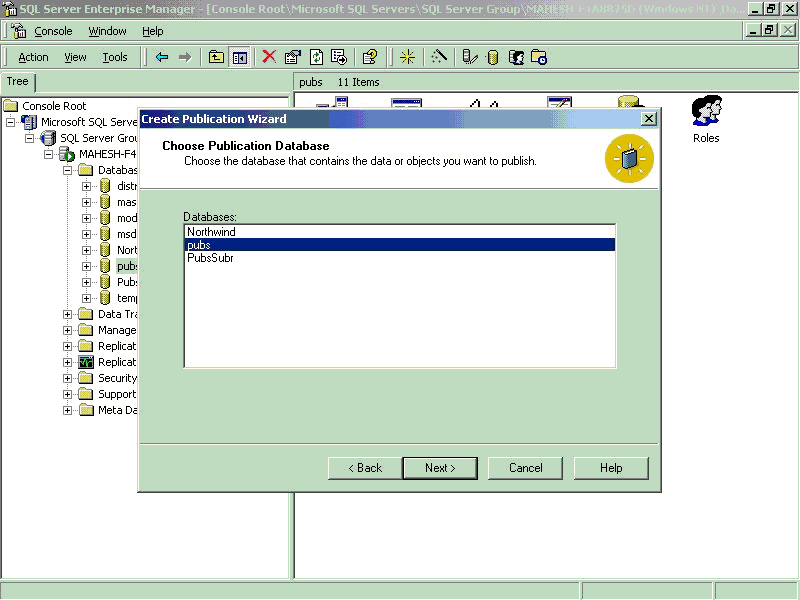
3. Creating Publication
- Right click on PUBS database click on New/Publication…which will run the
Publication wizard.
- Select the PUBS database as Publication Database
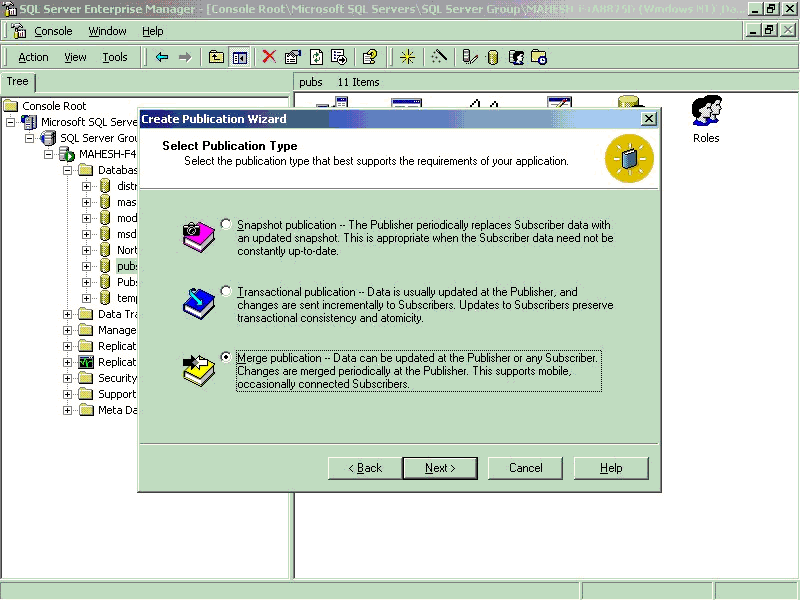
- Chose replication type as Merge replication.
- Specify what types of Subscribers will subscribe to this Publication, In this
example I chose, SQL Server 2000 as Subscriber types
- Chose the ‘Object type’ you want to Publish, I in this example I will chose to
publish all type of objects.
- Go to all the table article properties (Click on the ellipses) and select the
Identity Range tab and Check Automatic identity range manipulation check box
and set Publisher and Subscriber range to desired value, in this example I will
set the Identity range value as 1500. This is tedious process, hence it is
necessary to automate this process, I will use the following system stored
procedures to set the Identity range explicitly.
- Sp_adjustpublisheridentityrange
- Sp_addmergearticle
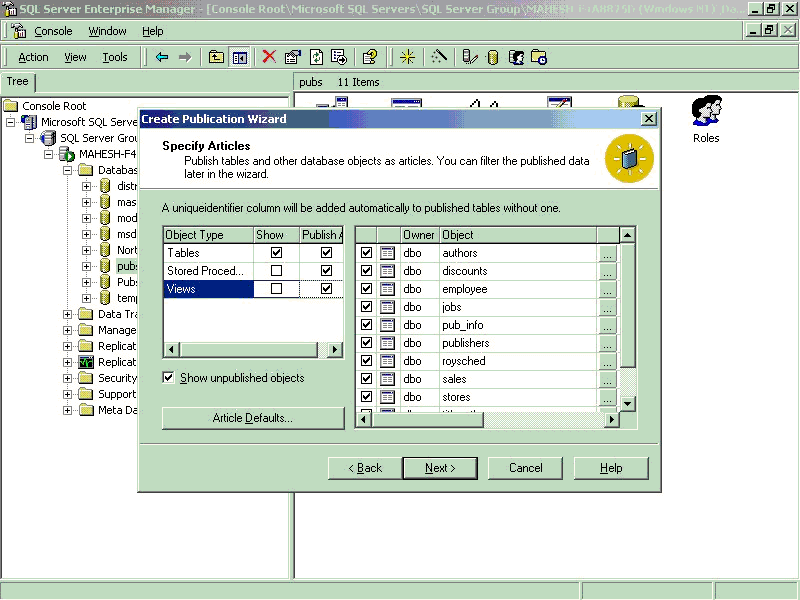
Identity range setting process.
and internally uses ‘SP_addmergearticle’ system stored procedures to set the
Identity range of all the Published Table articles.

- Specify the Publication name.
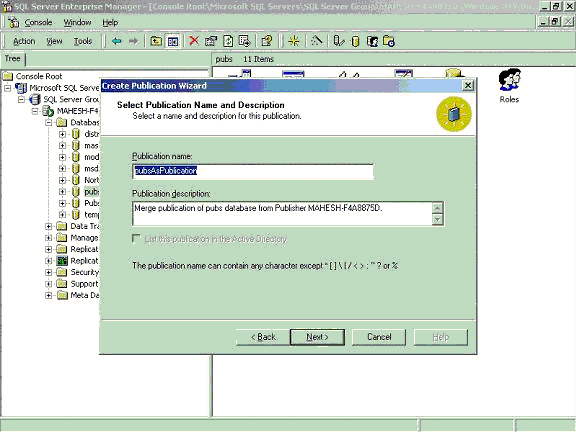
- Accept other settings and create publication.
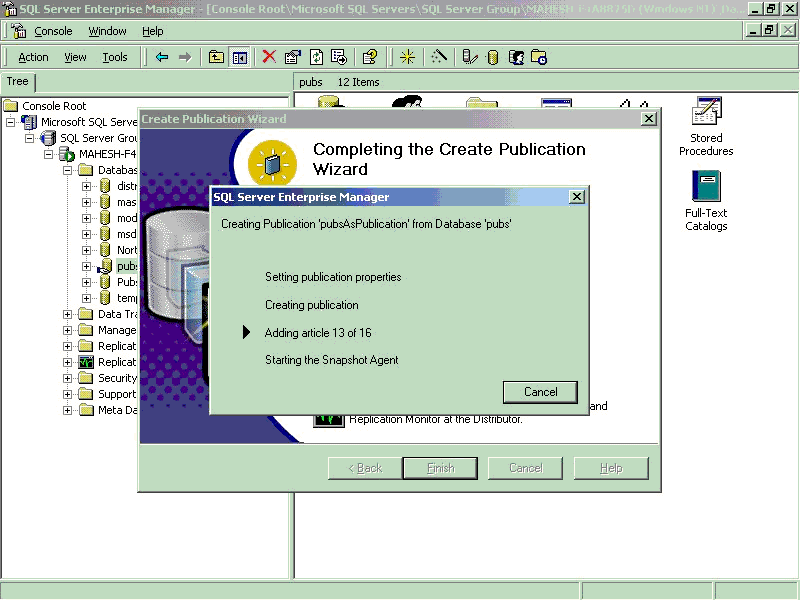
publication properties.
4. Create Snap Shot
- Navigate to /Replication/Publications/properties…
- Select the status Tab
- Click on “Run Agent Now” button this will create the snap shot files
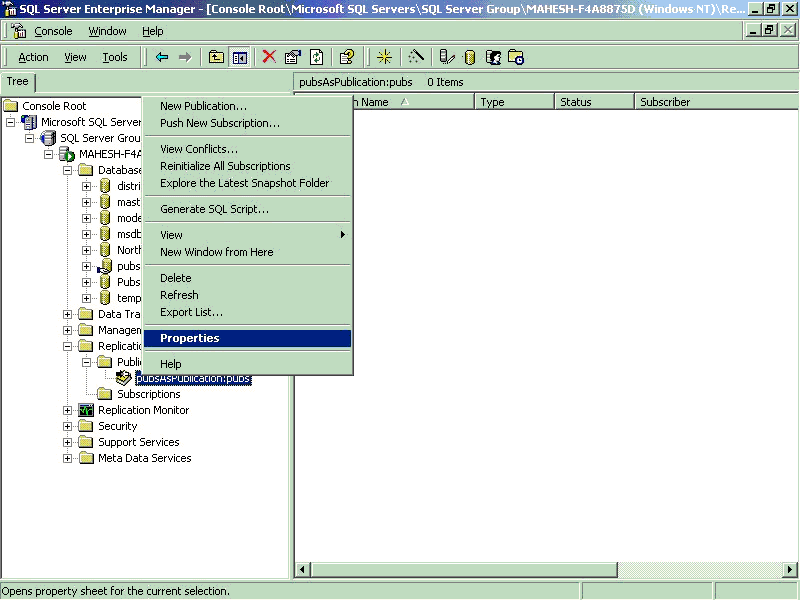
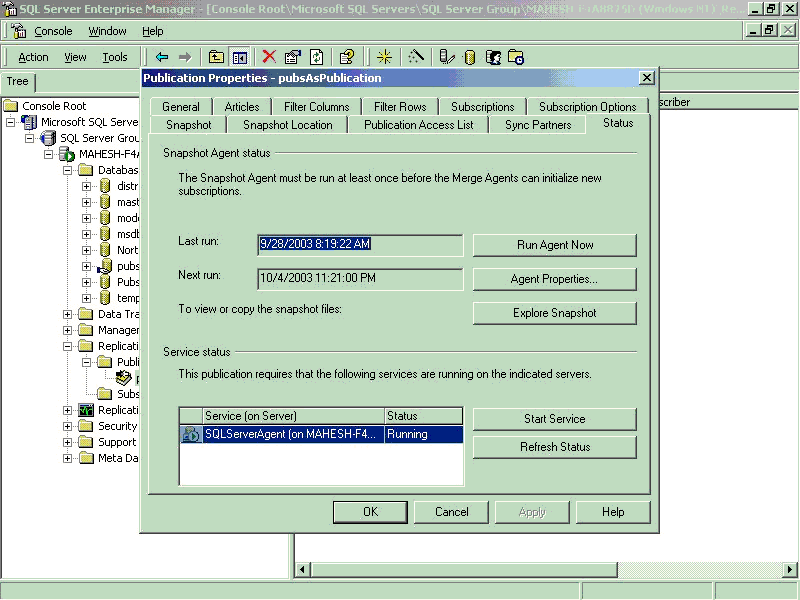
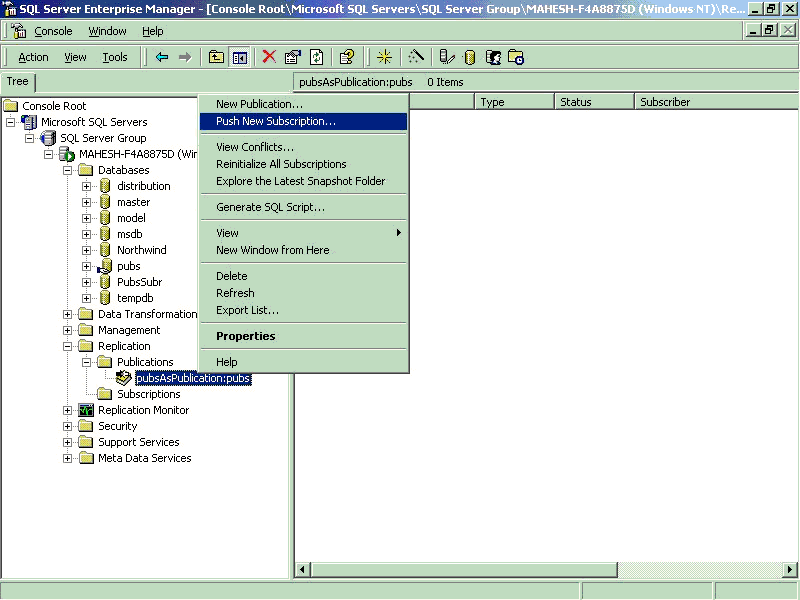
5. Adding Subscribers
- Create a new Database, Just a new SQL Server Database. In this example I have
created a New Database by name PubsSubscriber
- Right click on /Replication/Publications/Pubs:
- Click “Push New Subscription” to run the New Subscription wizard
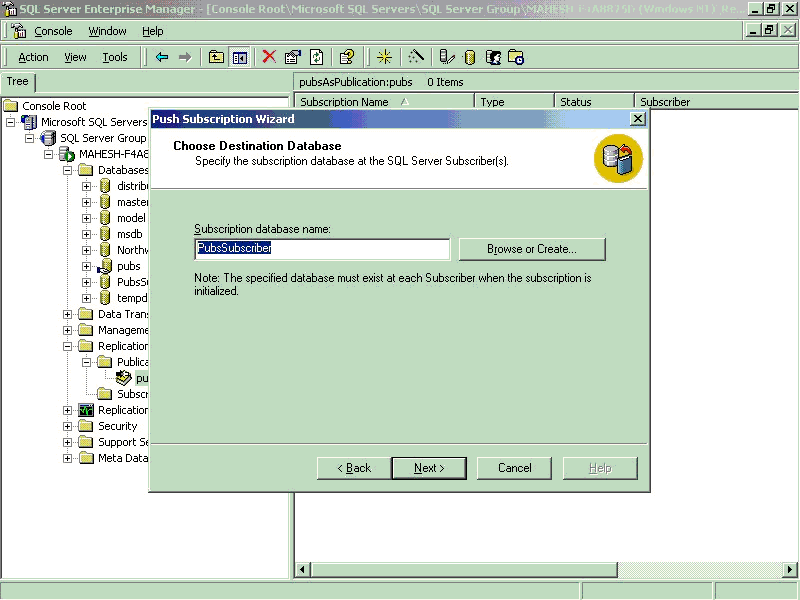
- Choose the newly created database as Subscriber Database
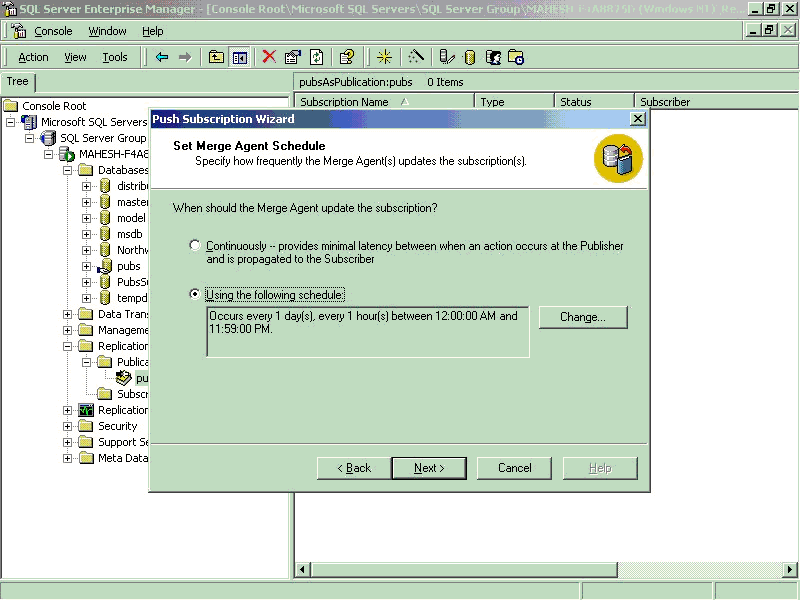
- Set Merge Agent schedule
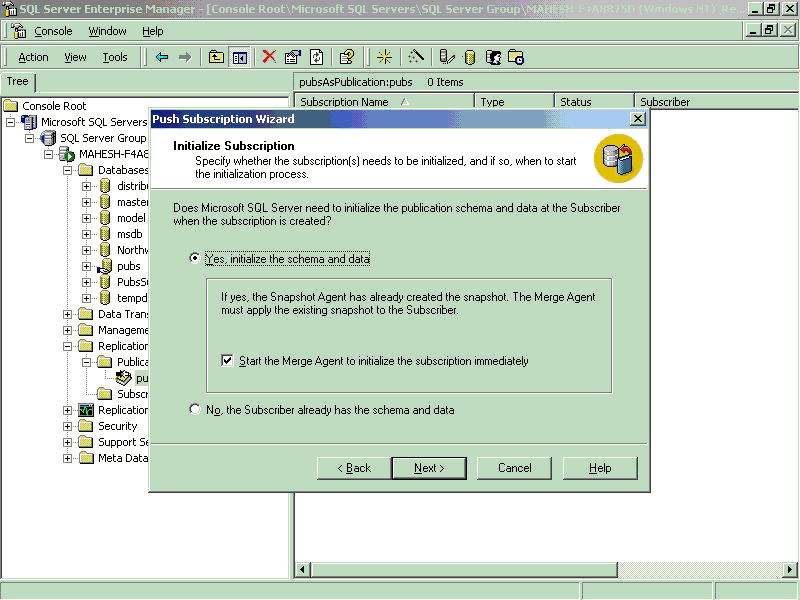
- Choose Initialize both schema and data option and check Start the Merge agent
to initialize the subscription immediately.
initialize both schema and Data.
complete the wizard steps.
handshake between publisher and Subscriber.
their own copy of data, and synchronize the data as per the rules of business.
6. Synchronize
- To synchronize, Right click on the /Replication/Publications/Pubs: And click “Start Synchronization”
achieve this is filtering the data before publishing, in other words, “Give
subscribers what they want to see and play with”.
distributing partitions of data to different Subscribers, you can:
- Minimize the amount of data sent over the network.
- Reduce the amount of storage space required at the Subscriber.
- Customize publications and applications based on individual Subscriber
requirements.
- Reduce conflicts because the different data partitions can be sent to different
Subscribers.
performance
- When running SQL Server replication on a dedicated server, consider setting the
minimum memory amount for SQL Server to use from the default value of 0 to a
value closer to what SQL Server normally uses.
- Don’t publish more data than you need. Try to use Row filter and Column filter
options wherever possible as explained above.
- For best performance, avoid replicating columns in your publications that
include TEXT, NTEXT or IMAGE data types.
- Avoid creating triggers on tables that contain subscribed data
- Applications that are updated frequently are not good candidates for database
replication.
- Distribute the workload into more than one SQL server using replication.
- Plan for the type of replication to be used before the database design, because
the type of replication used will to certain extent guide your database design
source database to one or more destination databases. SQL Server 2000 gives you
the power for replication design, implementation, monitoring, and
administration. This gives you the functionality and flexibility needed for
distributing copy of data and maintaining data consistency among the
distributed. You can automatically distribute data from one SQL Server to many
different SQL Servers through ODBC (Open Database Connectivity) or OLE DB. SQL
Server replication provides update replication capabilities such as Immediate
Updating Subscribers and merges replication. With all the new enhancements to
SQL Server replication, the number of possible applications and business
scenarios is mind-boggling.
Author:
Mahesh M Kodli
Senior Systems Engineer,MCAD Professional
Global Microsoft Unit, Wipro Technologies
Bangalore
