

One of my colleagues noticed an unusually high number of scans against a database where the principal application used the nHibernate ORM framework. The cause was interesting and worth documenting so I decided to write it up as an article for SQLServerCentral.
As ever I fired up my SQLServerCentral database with the intent of reproducing the problem in an anonymous system. Things didn't quite go according to plan as you will see in the article below.
The original problem
The database was performing index scans rather than index seeks and the solution was found on a blog called " Todd's tech nonsense".
Let us imagine you have a simple table called dbo.Contact which is as follows
| Field | Data type | Description |
|---|---|---|
| ContactID | INT | Primary key and identifier for the contact |
| FirstName | VARCHAR(50) | Intended for first names such as Andy, Dave, Steve, Brian etc |
| LastName | VARCHAR(50) | Intended for surnames such as Warren, Poole, Jones, Knight or Kelley |
A composite index exists across LastName and FirstName.
The queries below differ only in the definition of the @LastName parameter
- Query one uses VARCHAR
- Query two uses NVARCHAR
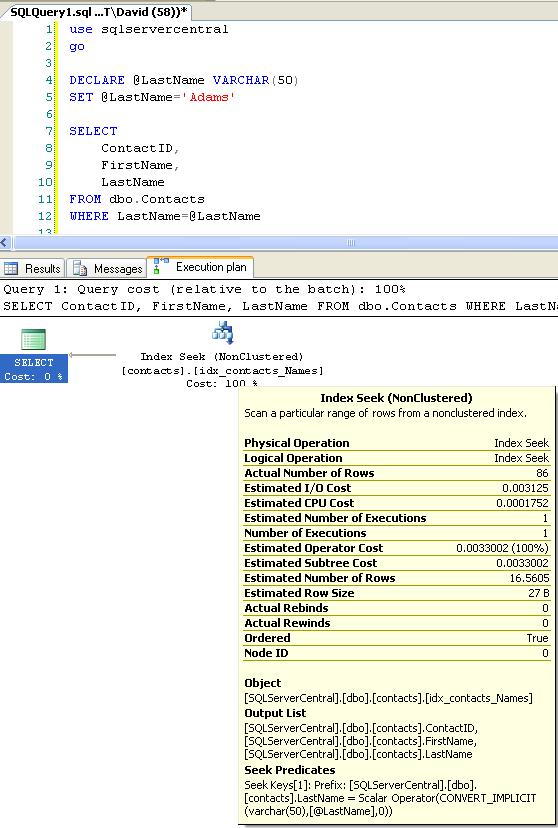
Query One:
Query Two:
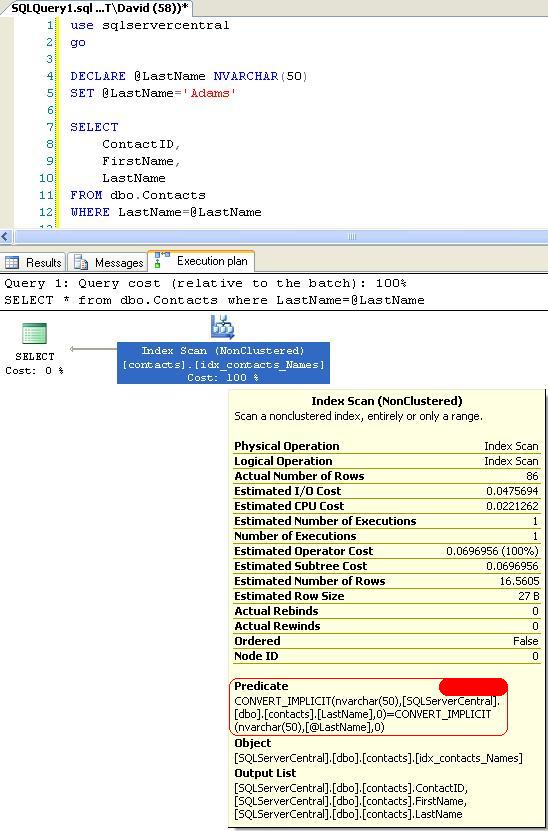
The reason that Query Two scans is that the query optimiser has to use a function on both sides of the predicate which forces row-by-row execution. The optimiser is illustrating precisely why you should always try and compare a values to a field directly rather than a field wrapped in a function.
In the production system the real "contact" table is large and growing as it represents customers, may they live long and prosper hopefully by purchasing from us! The effect of those scans is going to get worse and worse as the table grows so fixing the problem is high on the DBAs priorities.
The fix was as described in Todd's blog however my story doesn't end there.
Reproducing the problem
Anyone who has ever had to resolve a live incident knows that the first step is to reproduce the error in the development and test environments. It was here that my problems started.
I ran the database build scripts on my local box, generated some test data and tried the experiment again fully expecting the same results. As you will see from the execution plan shown below SQL Server refused to play ball.
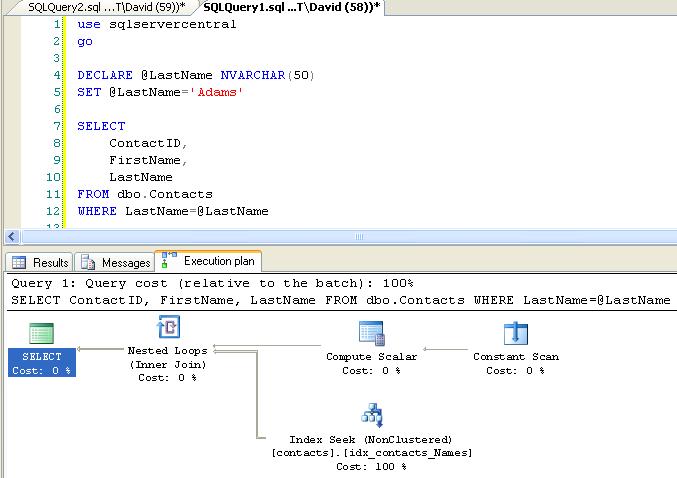
SQL Server had the wit and wisdom to realise that the NVARCHAR could be converted to a VARCHAR using the "Compute Scalar" operator and this would enable it to perform the desired INDEX SEEK.
I know the solution to the original problem but if I don't find out why one instance throws a scan and the other a seek then this is a potential problem that will return to haunt me.
Investigating the differences
Check the indexes and statistics
When an identical query on a separate instance behaves differently then nine times out of ten it has something to do with table statistics. On both the live and test systems the actual fields participating in the index were highly selective and I had generated about 50,000 test records on my development box so I felt relatively confident that the problem had nothing to do with data volumes.
Step One: Drop and recreate the indexes on the offending table and UPDATE STATISTICS WITH FULLSCAN. This had no effect whatsoever.
I had been running the queries using sp_executeSQL as this was what nHibernate used to call the SQL. Thinking that a cached execution plan might be the problem I ran DBCC FREEPROCCACHE. This had no effect whatsoever.
Check the differences between the servers
I remembered that a previous production incident where a service pack had changed the behaviour of the DB server so I decided to check the build level of my test and production boxes by running the following SQL
SELECT
SERVERPROPERTY('ProductVersion') AS ProductVersion,
SERVERPROPERTY('ProductLevel') AS ProductLevel
This did reveal a difference so I rebuilt my test server to match the production box. This had no effect whatsoever.
Check the differences in the data
OK, so we have the same server, defragmented indexes and a fully updated set of statistics. The next step was to put the actual data into the test environment. This is always something that makes the compliance guys jumpy. I used Red-Gate Data Compare to get an exact copy of the production data, rebuilt the indexes and statistics for good measure and tried again. This had no effect whatsoever.
Check the production database in the test environment
Sometimes this step simply isn't possible. If you have a high GB, or TB scale production DB then you are going to be lucky if you have storage, let alone performant storage, to hand.
Fortunately this particular DB was a small 90GB system. I restored the production DB onto the test box and confirmed that I could reproduce the scan behaviour. OK, I'm getting somewhere, it is obviously something to do with the database but what exactly?
Copy data from the production copy database to the test database
My next step was to copy the table from the copy of the production database (where I had managed to reproduce the expected results) to my sample database.
USE TestDB GO SELECT <fieldlist> INTO dbo.Contact FROM ProductionDB.dbo.Contact GO
After adding the primary key and supporting indexes I tried again. This time I got the expected SCAN. This meant that the behaviour had something to do with the source data.
The next thing I tried was to create the dbo.Contact table directly in my database and then copy the data across from the production copy.
USE TestDB GO INSERT INTO dbo.Contact(<fieldlist>) SELECT <fieldlist> FROM ProductionDB.dbo.Contact GO
This time my query reverted back to a seek so whatever it is that cases the difference has something to do with the production database.
Checking the database using sp_helpDB
After some beard scratching in the DBA camp I decided to run sp_helpdb to see if that revealed anything. This revealed that the two databases were actually running different collation sequences
| Database | Index behaviour | Collation Sequence | When used |
|---|---|---|---|
| Test database | SEEK | Latin1_General_CI_AS | Usually used by non-US English locales |
| Production database | SCAN | SQL1_Latin1_General_CP1_CI_AS | Default US-English. |
So I changed the collation on the seeking DB to match the other using
ALTER DATABASE TestDB COLLATE SQL1_LATIN1_GENERAL_CP1_CI_AS
Embarrassingly I had only skimmed SQL BOL and didn't spot the remark that highlighted that this only affected new objects and not the originating objects.
Running sp_help against the offending test and production tables revealed the difference.
NVARCHAR fields but VARCHAR Arguments
It is worth mentioning that if the fields are NVARCHAR and the parameter is a VARCHAR then regardless of collation sequence SQL Server will perform a SEEK. However I would not recommend using NVARCHAR and NCHAR fields unless they are really necessary. Storage capacity is rarely an issue these days but storage performance remains a major headache. Perhaps Steve Wozniak's FusionIO card will evolve into the storage silver bullet and in future we won't have to care about data types except for enforcing data quality. For now consumption for the sake of consumption does not make sense.
Fixing the DB
The big question was why did the development and test servers get to have a different collation sequence from the production servers?
The answer lies in a bug in the cluster installer for SQL2008. As I live in the UK the collation sequence chosen was Latin1_General_CI_AS which is for UK English but the installer ignores it and defaults back to SQL_Latin1_General_CP1_CI_AS which is for US English. Unless you think to check the collation sequence post build it is a very easy thing to miss.
So how to fix the problem? Well, you could run :
ALTER TABLE <your table> ALTER COLUMN <your column> COLLATE LATIN1_GENERAL_CI_AS but in order to do so you would have to drop any objects depending on the VARCHAR fields. Imagine having to do this for every VARCHAR and CHAR field in your database.
It is possible but immensely impractical and will certainly cause down-time while the change takes place. It also raises the spectre of having to change the servers default collation, after all you don't want to fix a DB only to find that the next database is built with the server default collation creating the problem again. This means rebuilding the master DB.
To be honest I think that fixing the servers default collation sequence is something that has to happen but, as with all things, its not particularly high on a very long list of things to do. Even if it was practical I am not comfortable with an application that is deliberately passing a different parameter definition than the values that are actually stored in the database. It is an accident waiting to happen, particularly if an application has to be ported to a company division that has to run a different collation sequence.