

This article will address the necessary steps for efficient data/record processing that includes a record linkage or fuzzy matching step. I have developed a simple SSIS example using AdventureWorks to demonstrate how to implement this concept, but first we are going to define the matching process, well-researched solutions and inherent performance problem.

Any record linkage operation will ultimately require string matching and will require comparing some columns in a complete set of records to all the records in another set – effectively a cross join. This is a very resource intensive process. The trick here is to reduce the number of string comparisons as much as possible. This problem has been researched by many academics.
Over at Henrik Liliendahl Sorensen’s LinkedIn Group for Data Matching, Bill Winkler, principal researcher at the US Census Bureau has shared several reference papers on the reasoning and methodology for record linkage using blocking. They are excellent and I wanted to share them with you:
- Chaudhuri, S., Gamjam, K., Ganti, V., and Motwani, R. (2003), "Robust and Efficient Match for On-Line Data Cleaning," ACM SIGMOD '03, 313-324.
- Baxter, R., Christen, P. and Churches, T. (2003), "A Comparison of Fast Blocking Methods for Record Linkage," Proceedings of the ACM Workshop on Data Cleaning, Record Linkage and Object Identification, Washington, DC, August 2003.
- Winkler, W. E. (2004c), "Approximate String Comparator Search Strategies for Very Large Administrative Lists," Proceedings of the Section on Survey Research Methods, American Statistical Association, CD-ROM.
Here are several papers I have used with some samples of open-source algorithms:
- William W. Cohen; Pradeep Ravikumar; Stephen Fienberg; Kathryn Rivard. A technical paper on string-matching methods which uses SecondString (PDF).
- Mikhail Bilenko and Raymond Mooney, University of Texas at Austin; William Cohen, Pradeep Ravikumar, and Stephen Fienberg, Carnegie Mellon University, "Adaptive Name Matching in Information Integration".
- William W. Cohen Pradeep Ravikumar Stephen E. Fienberg, "A Comparison of String Distance Metrics for Name-Matching Tasks".
How our brains handle matching challenges
Consider this: you are watching a school concert and several dozen children are up on stage. Now, pick out the twins. You would probably start with looking for groups based on hair color, hair length, etc. long before you start comparing faces. This is, in essence, grouping or blocking. If you line the blonds on the left and the brunettes on the right, you now have two blocks.

The next step in identifying the twins is to repeat the process with new groups until you have found the twins. Compare all blonds, then brunettes, and so on. Then, move on to short hair, long hair, and so on. Finally, move on to similar face shapes. This is fuzzy matching.
Hair is blond or brunette, long or short; but faces are a collection of features, and have a pattern forming an image. Our brains instinctively look for faces that are similar, then compare more closely. The obvious point here is to only begin comparing faces once we have narrowed down to just a small group of children.
Let’s examine the steps involved as a logical process.
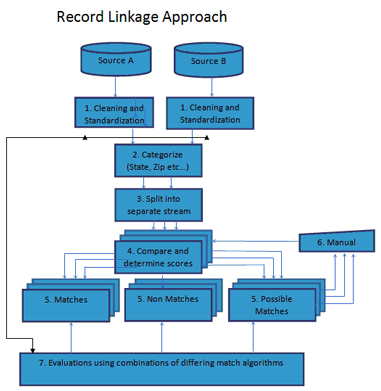
1. Cleansing and Standardization
The objective here is to cleanse and format the required columns. The key here is to get as much consistency and uniformity in each column as possible. For instance in columns like Zip Code or Address you want to have correct values and proper patterns. This is critical to reducing unnecessary processing time during the match process. One way to automate this step is to use data profiling with some pattern matching or REGEX (Regular Expression) cleansing.
2. Categorize or Group records
Once we have cleansed and standardized our input we can then examine how to best split, group or categorize our records into separate sets. An example of this would be to put records for each states (Arkansas, Maine etc.) into a group. In Record Linkage jargon, this is called a Blocking Index.
The thinking here is that we want to use as many columns for equality matches as possible, thereby reducing the records that need fuzzy matching. Obviously if we can match on state, zip, and phone it will leave only the name field as a candidate for a fuzzy match. Grouping sets of records by state or by the first three characters of the phone number means we need to process fewer records during the match. As we discussed earlier, a fuzzy match is in effect a cross join and can quickly result in a very high volume of record and column comparisons.
William Winkler, the Chief Researcher for Census Bureau, has detailed the recommended groups of column types that can be most effective. The best groups or Blocking Indexes vary depending on the columns available. Winkler particularly recommends the top 5:
- ZIP, first three characters of surname.
- First ten digits of phone number.
- First three characters of last name, first three characters of first name.
- ZIP, house number.
- First three characters of ZIP, day-of-birth, month-of-birth.
- First three characters of last name, first three characters of first name, month-of-birth.
- First three characters of surname, first three characters of phone, house number.
- First three characters of surname, first three characters of first name, date-of-birth.
- First three characters of first name, first three characters of ZIP, house number.
- First three characters of last name, first three characters of ZIP, first three characters of phone number.
- First three characters of last name, first three characters of first name (2-way switch), first three characters of ZIP, first three characters of phone number.
3. Split
Split records, based on the criteria in the Blocking Indexes. Create separate data streams to support parallel match processing.
4. Compare
Compare by applying fuzzy matching algorithm to groups of records and determine scores based on the groups selected. We will discuss various algorithms in a future post. The huge problem with the fuzzy matching processing performance is that the matches are similar and not exact. If you get a commercial matching tool and start comparing data sets, I guarantee the tool will frantically try to get you to define as many columns or fields for a match (Blocking Index) as possible, before you do any fuzzy stuff.
5. Split
Split into separate result categories of match, no match and possible matches.
6. Analyze
Analyze results of no matches and possible matches. Matches need to be reviewed for accuracy. this can be done with tools or in some cases manually.
7. Evaluate
Evaluate results manually using matching tools to determine if the best algorithms have been combined. Possible matches need to be evaluated and analyzed. Determine if additional cleansing or different matching algorithms could be utilized more effectively.
SSIS Example of Fuzzy Matching with Blocking Indexes
In the example below I will demonstrate Steps 2-5 using the SSIS Fuzzy Grouping and Conditional Split Components as well as the SSIS Pipeline Architecture for parallel processing. In SSIS the basic process for implementing blocking indexes involves using a Conditional Split to create multiple threads of records and applying the Fuzzy Grouping Transform. For this example we assume a basic customer input with: First Name, Last Name, Address, State, Zip, and Phone.
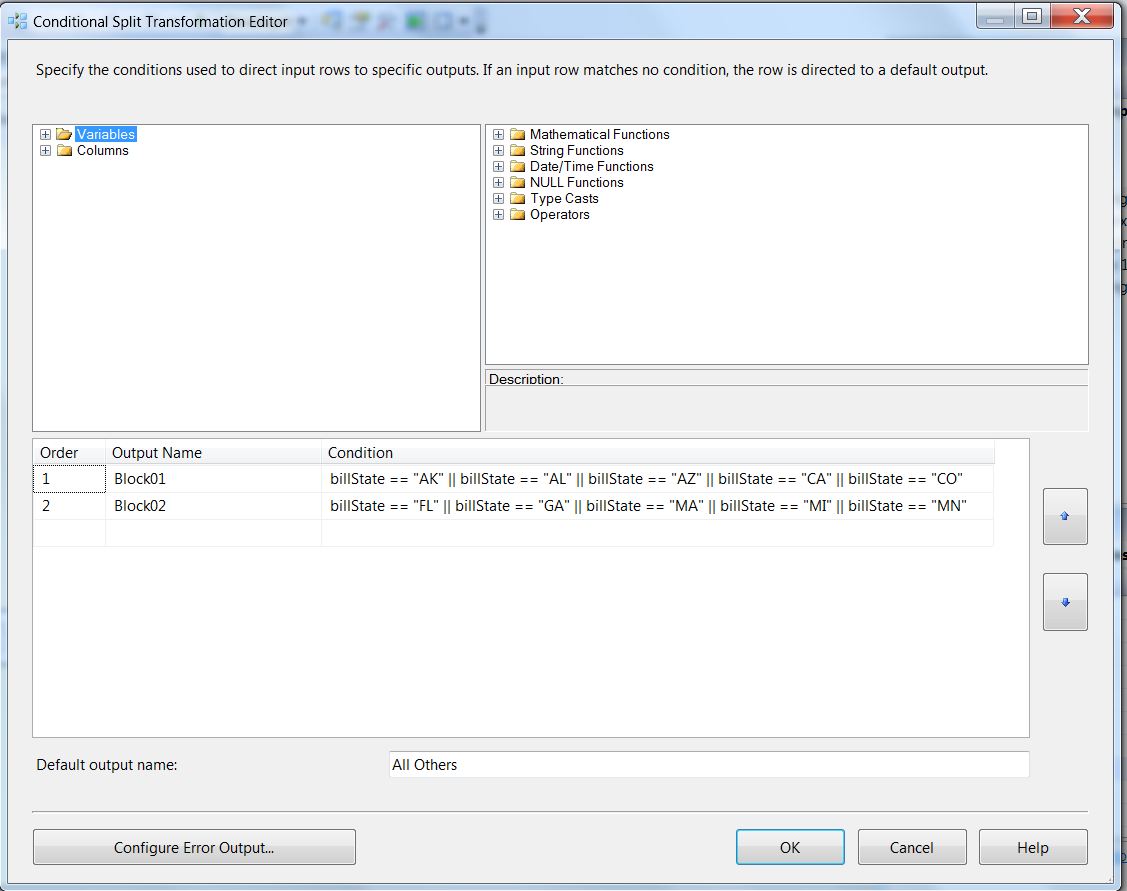
We will split the records based on State in the following manner:
- Block01 = AK, AL, AZ, CA, CO
- Block02 = FL, GA, MI, MA, MN
- Block02 = Everything else.
Putting the theory to the test
I created a package using AdventureWorks that processes and uses Fuzzy Grouping for 10,000 records without using a blocking index and the execution time was 39 minutes.
I then ran the same 10,000 records with a conditional split, creating a blocking index with three parallel threads by blocking on state. Using a blocking index, the execution time was 20 minutes.
In this case the execution time was cut by almost half. When processing larger volumes, the net reduction in time would be much greater.
How to do it
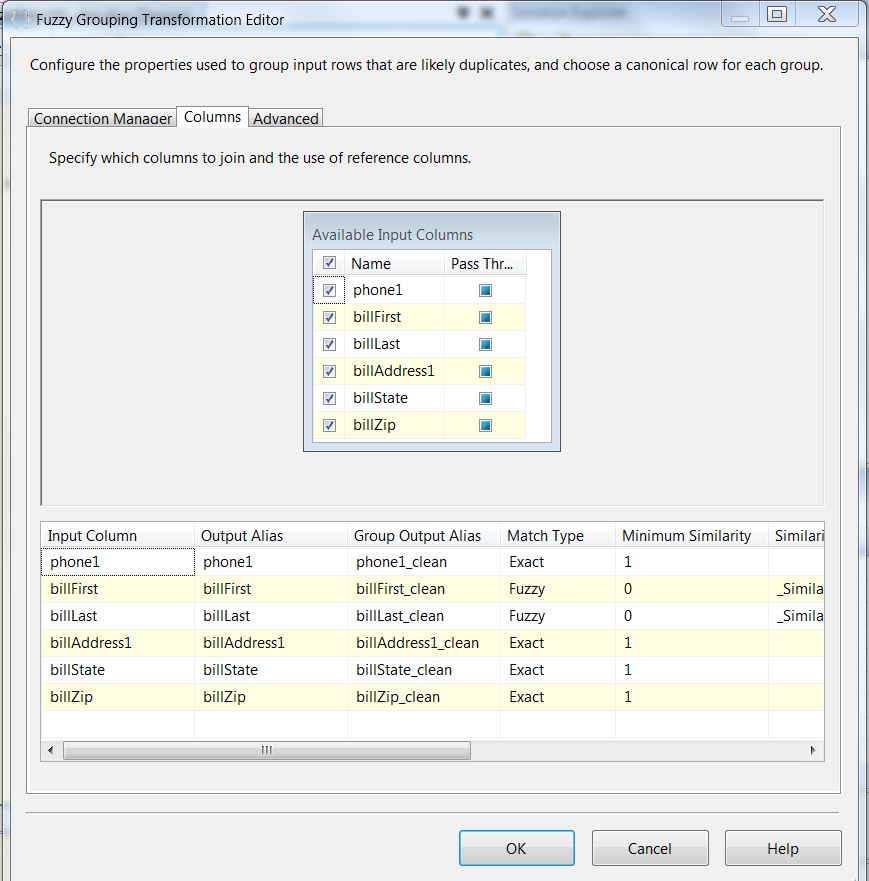
Here is the setup for the Fuzzy Grouping. This transform has a very straightforward configuration. Once you have selected the desired input columns you can then select the Match Type, Fuzzy or Exact. You will note that except for First and Last Names, all columns are set for an exact match. First and Last Name will be set to Fuzzy. This set up will be the same for both tests. For more detailed information on how to set up the Fuzzy Group Transform, take a look here.
Here is the first package without splitting records via a blocking index.
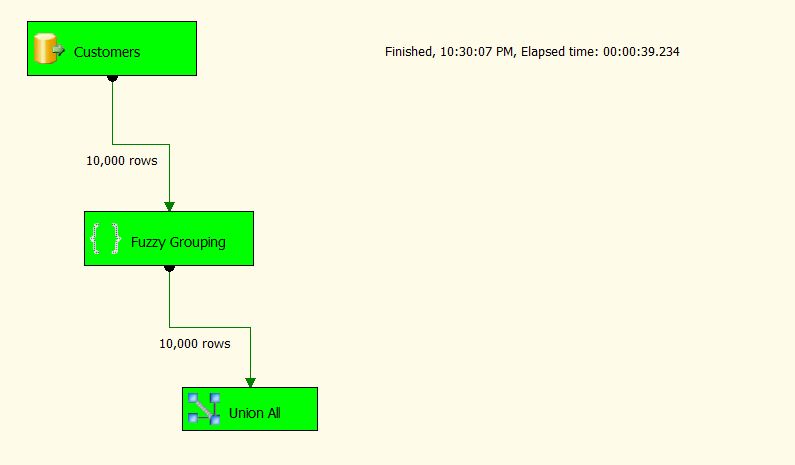
Run this test first. Note the time elapsed in the Execution Status tab.
Now let’s change the packages and implement what we have discussed. We will split the paths, leveraging the parallelism and the pipeline capabilities in SSIS. Revise the package by adding a Conditional Split and multiple Fuzzy Grouping Transforms.
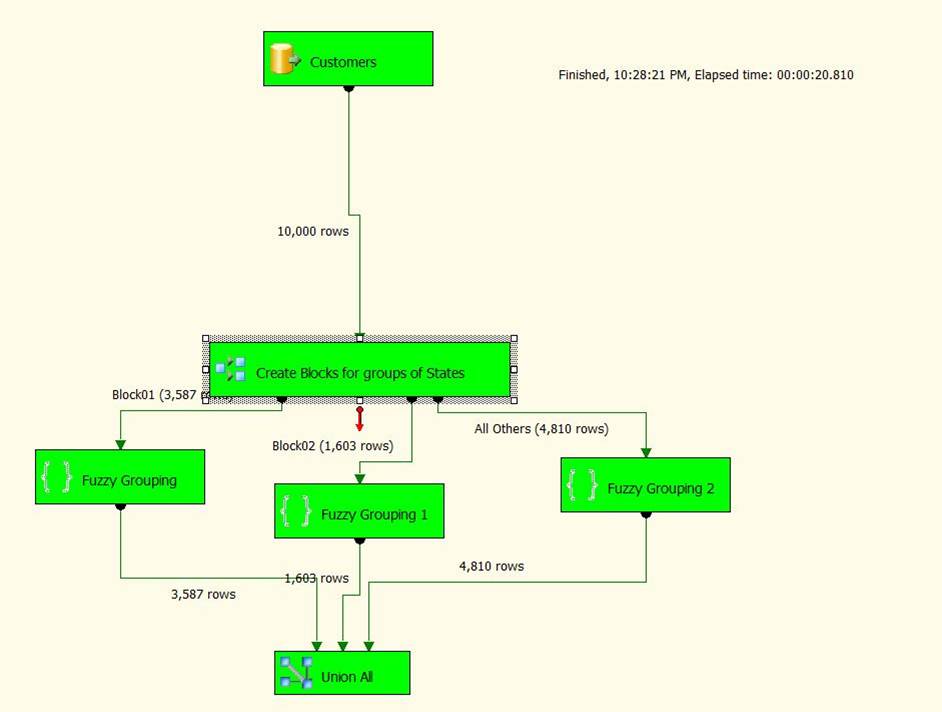
Here is the setup for the Condition Split used to implement the blocking index, where we split our records into three blocks of states. We may still need to check across states, but all their matches will be eliminated.
Once you have configured the Conditional Split you need to connect the separate outputs to the original Union All component. If you are not familiar with the Conditional Split check out Andy Leonard’s excellent post here.
One more important point on package performance: there are two properties that can help improve performance for SSIS DataFlows when properly configured. These are DefaultBufferMaxRows and DefaultBufferSize, which are covered well in SQLRUNNER's blog.
Summary
The major takeaway from this article is that you should apply the same logical thinking to using the SSIS Fuzzy Grouping as you do in your own everyday thinking and matching problems.
Secondly, the capability that enables this technique to succeed is the pipeline architecture in SSIS.
On a final note, here is the definition of the pipeline architecture as defined by Microsoft. I have included this in my other SQL Server Central articles on Fuzzy Matching and I think it is important here to take a few minutes to review this critical capability at the heart of the SSIS architecture:
"At the core of SSIS is the data transformation pipeline. This pipeline has a buffer-oriented architecture that is extremely fast at manipulating row sets of data once they have been loaded into memory. The approach is to perform all data transformation steps of the ETL process in a single operation without staging data, although specific transformation or operational requirements, or indeed hardware may be a hindrance. Nevertheless, for maximum performance, the architecture avoids staging. Even copying the data in memory is avoided as far as possible. This is in contrast to traditional ETL tools, which often requires staging at almost every step of the warehousing and integration process. The ability to manipulate data without staging extends beyond traditional relational and flat file data and beyond traditional ETL transformation capabilities. With SSIS, all types of data (structured, unstructured, XML, etc.) are converted to a tabular (columns and rows) structure before being loaded into its buffers. Any data operation that can be applied to tabular data can be applied to the data at any step in the data-flow pipeline. This means that a single data-flow pipeline can integrate diverse sources of data and perform arbitrarily complex operations on these data without having to stage the data.
It should also be noted though, that if staging is required for business or operational reasons, SSIS has good support for these implementations as well.
This architecture allows SSIS to be used in a variety of data integration scenarios, ranging from traditional DW-oriented ETL to non-traditional information integration technologies."
Ira Warren Whiteside Blog
"Do, or do not. There is no try."
"Karo yaa na karo, koshish jaisa kuch nahi hai."