

This article takes a simple look at loading data in parallel from a single data source, be it a flat file or a database. In the main example this source can be any database table that can be read using an OLEDB or an ADO.NET data source. Yes, the Balanced Data Distributor now exists, and it can do much of this for you easily and automatically as you saw in a previous article. However there could be times when you need the control and fine-tuning that a Do-It-Yourself solution can offer.
In all these examples I am only be creating two parallel destinations. Of course, you can extend this to handle the number best suited to your requirements—and your system. As ever, there are no hard and fast rules as to how many parallel loads to run for optimal performance. You will have to test and tweak for the best results.
Let us start with a source datatable. It can be an SQL Server source, or indeed any data source that SSIS can connect to. The classic sources other than SQL Server are the other main relational databases on the market. I am presuming in this article that you are faced with a single datatable and a single destination table.
As part of the initial SELECT clause, a “process path” identifier is generated. In this case, it is deduced from the ID using the SQL Server modulo operator (%). This guarantees that each source record will be attributed either a 0 or a 1 as a flag to be used by the Conditional Split task. This allows the load to be split into two streams, even for a single destination table. However, you must be using the Bulk Insert API (table or view—fast load) and have to select the Table Lock for parallel inserts setting to be sure this will work.
As this is simply an example of a custom built parallel data load, the sample data is very small. You can find it in the attached sample file (see the References section) in the form of the “Stock.Sql” script that you can run to create a destination table and load a few lines of data. You can use any database you choose as the source.
I am presuming, in this example, that it will be called CarSales_ParallelProcessing. You will also need to create a destination database on your server. I am using a database called CarSales in this article, but you can tweak the example to choose any destination database. The attached sample file also contains the SSIS package that is outlined below. This process will read the data from the source table then split the source into two separate data flows. It uses parallel destination loading to accelerate the load part of the process.
Before beginning you will need a destination table. In the destination database (CarSales) create the following destination table (it is the ParallelTableLoad.sql script in the sample files):
CREATE TABLE dbo.ParallelTableLoad ( [ID] varchar(50) , [Make] varchar(50) , [Marque] varchar(50) , [Model] varchar(50) , [Registration_Date] varchar(50) , [Mileage] varchar(50) );
To load an SQL Server table using parallel loading:
1 - Create a new SSIS package, and name it SingleSourceParallelProcessing. Add two connection managers, both OLEDB. The first will connect to the source database that you will be using to load the data from (CarSales_ParallelProcessing in this example). The second will connect to the destination database (CarSales, here). I will name them CarSales_ParallelProcessing_OLEDB and, CarSales_OLEDB respectively.
2 - Add a Data Flow task onto the Control Flow pane. Name it Parallel Table Import. Double-click to edit.
3 - Add an OLEDB source task that you name Stock. Double-click to edit and set the OLEDB connection manager to CarSales_ParallelProcessing_OLEDB. Set the data access mode as SQL Command, and enter or build the following query (StockToParallel.Sql in the attached sample data):
SELECT ID ,Make ,Marque ,Model ,Registration_Date ,Mileage ,ID % 2 AS ProcessNumber FROM dbo.Stock
4 - Cick OK to confirm.
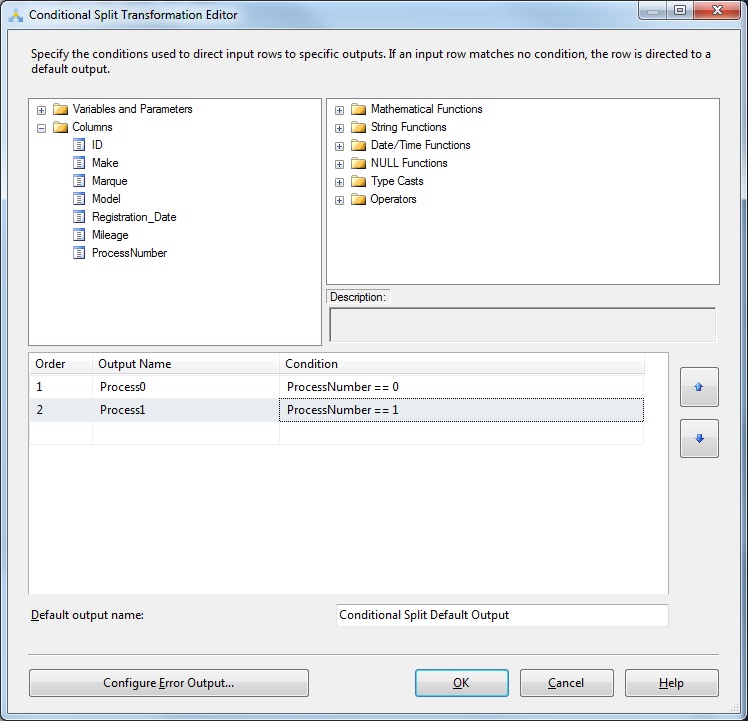
Now add a Conditional Split task onto the Data Flow pane. Name it "Separate out according to process number". Connect the data source task to this new task. Double-click to edit.
5 - Add two outputs named Process0 and Process1. Set the conditions as follows:
- ProcessNumber == 0
- ProcessNumber == 1
6 - This way, the contents of the ProcessNumber column that you created as part of the source SQL will be used to direct the data to an appropriate destination. The dialog box should look like this.
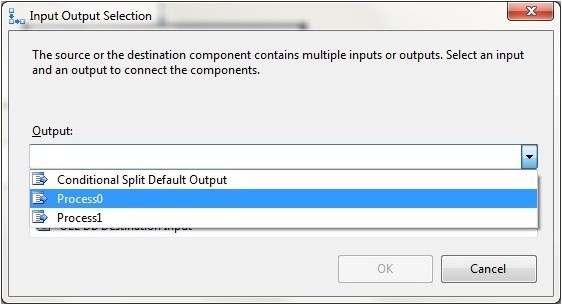
7 - Add two OLEDB destinations to the Data Flow pane. Name them Process0 and Process1.
8 - Connect the Conditional Split task to the Process0 destination. Select Process0 as the output from the Input Output Selection dialog box as shown below.
9 - Double-click the Process0 OLEDB destination task, and configure it as follows:
- OLEDB Connection Manager: CarSales_OLEDB
- Name of Table or View: ParallelTableLoad
- Keep Identity: Checked
- Table Lock: Checked
10 - Click OK to confirm.
11 - Map the source and destination columns in the OLEDB Destination Mappings pane. You should map all fields except ProcessNumber – this was used only so separate out the two parallel flows and is not needed once the process has finished.
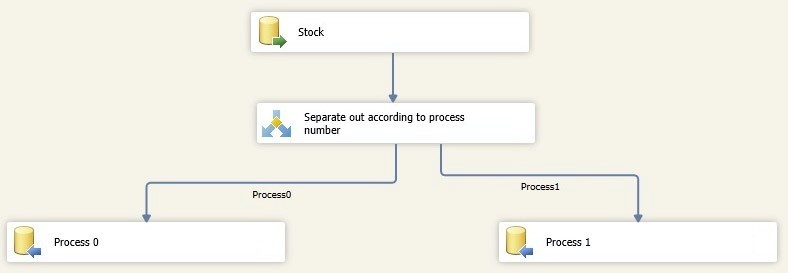
12 - Repeat steps 10 through 13 for the other destination task. You can now run the package, which should look like the one shown below.
Hints, Tips, and Traps
A few items of which you might want to be aware.
- When using SQL to generate the ProcessNumber, it can be a good idea to preview the results before running a vast import.
- To test the package you can always perform a simple load of the ProcessNumber column only, and then count the number of rows for each batch to check that you are getting a reasonably balanced distribution.
- There may be times when you need to calculate the ProcessNumber field without having a nice, simple unique ID field as a starting point, as was the case in this example. So, try using code like the following as part of the SELECT statement:
,ABS(CAST(HashBytes('SHA1', CAST(Make AS VARCHAR(20))+ Marque) AS INT)) % 2 AS ProcessNumber
- This code will create a hash from one or more fields, which is then used to derive the ProcessNumber field.
- There are similar ways for generating the process number from the pass-through SQL, which you can use if you are connecting to a database other than SQL Server. This will depend on the flavor of the SQL used by the database, however, and so I can only refer you to the documentation for the particular database that you are using.
Flat File Sources an Parallel Processing
The “Do-It-Yourself” approach can be adapted to flat files, too. However you will have to generate the process identifier that can be used to identify the load paths a little differently. Suppose that you have a Flat File source task instead of the OLEDB source in the example above. You then need to do the following:
1 - Add a Script component to the Data Flow pane, and set it as a transformation command type. Connect the Flat File source task Stock to this Script task, which I suggest naming Generate Hash.
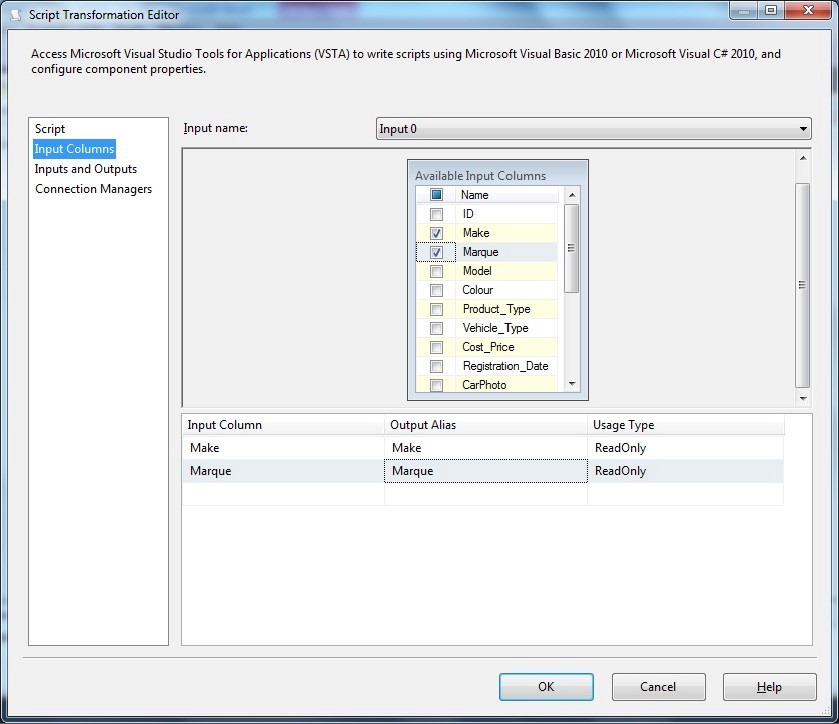
2 - Edit the Script component, select input Columns on the left pane, and select: Make Marque Or the columns that you wish to use to generate a hash key. The dialog box should look like the image below.
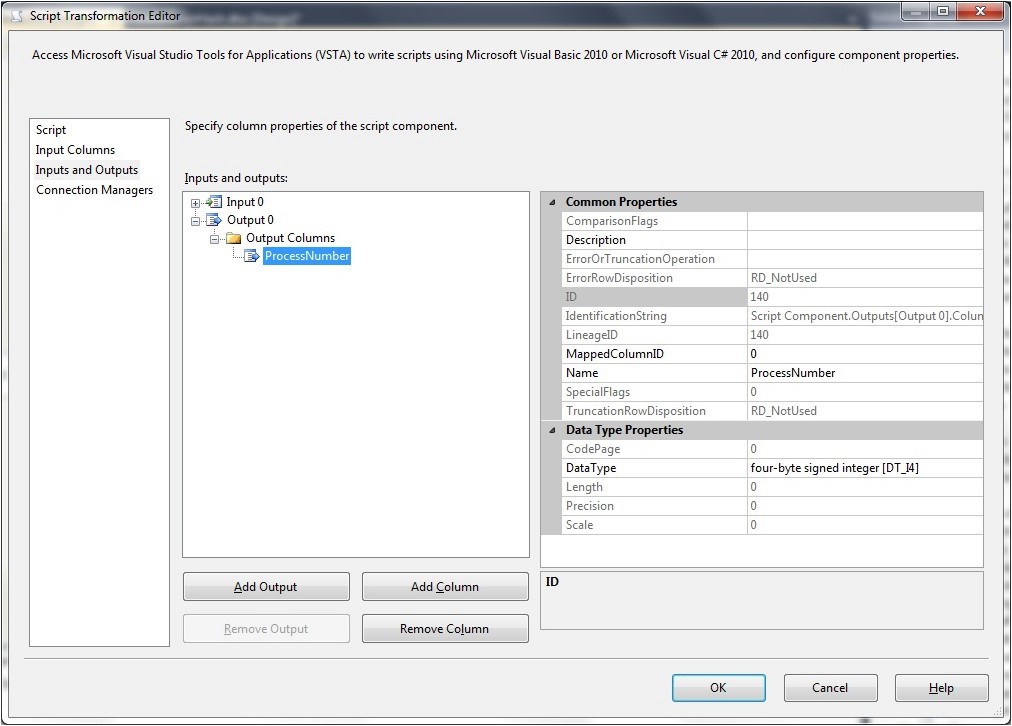
3 - Select Inputs and Outputs in the left pane, and add an output column (expand Output 0 select Output Columns and click the Add Columns button). Name the Output column ProcessNumber. It should preferably be of DataType 4-byte signed or unsigned integer. The dialog box will look like this.
4 - Select Script in the left pane. Set the script language to Microsoft Visual Basic 2010 and click Edit Script. Start by adding the following two directives to the Imports region of the script file:
Imports System.Security.Cryptography Imports System.Text
5 - Replace the method Input0_ProcessInputRow with the following code:
Public Overrides Sub Input0_ProcessInputRow(ByVal Row As Input0Buffer) Row.ProcessNumber = GetHashValue(Row.Marque & Row.Make) Mod 2 End Sub
6 - Add the following function in the ScriptMain class:
Private Function GetHashValue(ByVal SourceData As String) As Object Dim dataToHash As [Byte]() = New UnicodeEncoding().GetBytes(SourceData) Dim SHA As datatype = New SHA256Managed Dim hashedData As [Byte]() = SHA.ComputeHash(dataToHash) RNGCryptoServiceProvider. Create().GetBytes(dataToHash) Dim hashedDataInt As Int64 = BitConverter.ToInt64(hashedData, 0) Return Abs(hashedDataInt) End Function
7. Close the SSIS Script window and click OK. You can now continue with the previous example at step 5 and create a parallel destination.
This example attempts to answer the question, “How do I derive a process thread column from a flat file to enable multiple data destinations?” The answer is fairly straightforward and consists of using a Script task to generate the hash and corresponding ProcessNumber field. To avoid reiterating everything that was described in the previous example, I have merely explained the differences, and used previous the example as a basis for extension.
There are a few things to note about the script code. First, the procedure Input0_ProcessInputRow will fire for every row that this SSIS package processes. So what you are doing is to add a new column to the row, and then add the process number to this. Note that you have to create the new output column before you can create the script (at least if you want to avoid annoying alerts and errors). Second the GetHashValue function takes the concatenated input columns, and creates an SHA hash, which it then converts (well, the first Byte, anyway) to an integer. This integer is then used to derive the process number using the MOD function (not unlike the T-SQL % function used in the first example above).
Hints, Tips and Traps
- The hash value does not need to be based on all the fields in the source table, as it is not necessary to ensure uniqueness given that we are not using this hash for comparison purposes, but merely for an approximate balance in the data batch definition. So use any combination of fields that you feel gives an equitable distribution.
- If you have an integer field in the source data, and do not need to generate a hash to deduce a flow ID, then you can simply use the following single line of code to define the process flow number: Row.ProcessNumber = (CType(Row.ID % 2, Int32) + 1;
This article is taken from the book "SQL Server 2012 Data Integration Recipes", available on Amazon.