

Background information
This articles focus on a situation when a client wanted to collect customer information. Somebody come up with a brilliant idea of not bothering to modify the database structure, but just adding the fields that they needed to collect customer information. The idea behind this is once a customer's details are collected it will be loaded to another database for reporting. Initial hype surrounding the idea was hitting even the director's board. This is not the type of model that we should use for what the company wanted, but the CTO convinced me that he will take full responsibility for any outcome.
I have then ruled out myself from thproject. But, as the time goes by they start having a lot of issues even before going to production. I was then called into come up with some suggestions. The project has gone so far that it is impossible to revert back, so we had to continue forward with this design.
Main issues encountered
The main issue was scalability. As the table size grew, querying the table became unbearable. Though the initial idea of capturing customer information without modifying the database structure worked well, but getting a customer record became a painful task.
Suggested implementation
1. Redesign
My outright suggestion for this particular problem was to redesign the database and move it to a proper entity based schema. The suggestion was right in the long run, but as I have mentioned previously, the project had gone so far it was very difficult to revert back. So, I had to come up with a solution where it is possible to go live with the already developed solution and stil improve performance.
2. Partition to improve performance
As we all know the partitioning of database tables is used to improve the performance of large database tables. In a name value pair situation we have got a database with only one table, so it is a straight forward choice. The management of partitioned tables and indexes are very simple in SQL Server 2005 as opposed to SQL Server 2000.
The assumption here was that there is a defined access pattern for this particular issue, and that the data is accessed mostly using CustomerId . This is the logical grouping of data as described previously. Therefore, it makes sense to keep the same CustomerId in the same partitioned table. If the data access pattern changes then you need to look into what is the best way of partitioning your table.
If your data has logical groupings - and you often work with only a few of these defined subsets at a time then define your ranges so the queries are isolated to work with only the appropriate data (i.e. partition). Obviously, you need to define the partition column, which you may not have in case of EAV design.
The assumption that we need to keep the same customer records in one partition is the determining factor in deciding what partition column to use. Due to this a new column is added that can be purely used for partitioning the table.
When implementing partitioning, it is worth looking at filegoups as well. For the best filegoup configurations please refer to various articles on that topic. For the purpose of this article I have created 5 filegoups: one for primary data to support the system and user objects and the other to spread the partitioned tables. You can look into the script attached with this article and see how you can implement partitioning with filegroups. This is only for demonstration purpose to show how the partitioned table will be spread across different file groups that can be either on the same spindle or could be separated at later stages when you database grows.
After running the script you can see now where the data is stored. See now where the data for customerId is gone.

From this table you can see all the rows were inserted into partition number 4. All customers with customerId of 3 went to partition number 4. This has been done though the mod function (%) as shown on insertnamevaluepair stored procedure that is attached with the script. The partitionId is generated from @customerId%4 + 1.
There are also some considerations that you need to look into when creating indexes. For this article I just want to mention few. If you are creating an index on partition column then the index is aligned with the table. If the index uses the same partitioning scheme as the table and is in the same filegroup then index must be alighed to the table. I am not going to go into detail of how designing the indexes in this article. There are numerious references that can be used as a basis.
Most of the logic of creating partitioned tables can be used when implementing the same solution in SQL server 2000. The main difference is that you need to create the tables yourself and use a union all to join all the tables. Note - you need to enforce any referential integrity on individual tables as opposed to implementing it in SQL Server 2005.
3. Relational-name value pair
This section introduces an entity based concept, which entails adding additional lookup tables. This will not only result in less storage space but also will help in implementing solutions to improve performance such as partitioning. One lookup table is used to store pair names and the other is used for partitioning. You probably do not need to add a lookup table if you wish as you can use other methods to force your partition. As can you see, I am trying to add relational flavour to name value pair modelling. As there is not name in the industry for this type of modelling I tend to call it relational-name value pair.
Depending on your application try to ensure that your EAV rows have as many additional lookup keys as possible. This will help you in filtering your data based on the lookup keys.
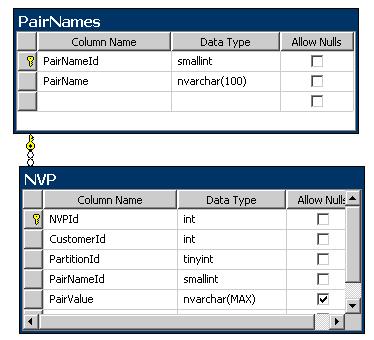
As you can see from the ERD diagram above I have added customerId column to the above table to keep related values together. For instance if you are storing customer information, you want to identify a customer with the values associated with it such as first name, last name, date of birth, address and etc.
I have also added another column (partitionId) that can be used in partitioning the NVP table.
4. Use of Triggers
If you are either reporting on the data captured or want to move your data to a schema based entity, the best thing to do is to create a trigger on name value pair table that populates another table. This table either can be designed as a partitioned table or a single table. In the scenario that I have outlined, an hourly data load will be performed in the table that is populated by trigger. From my experience, it has worked very well as the data reporting and transforming into a schema based entities will not interfere with the data capture process. This has solved the issue of getting meaningful customer information without putting a lot of load on the Name value pair table that is used to capture customer information.
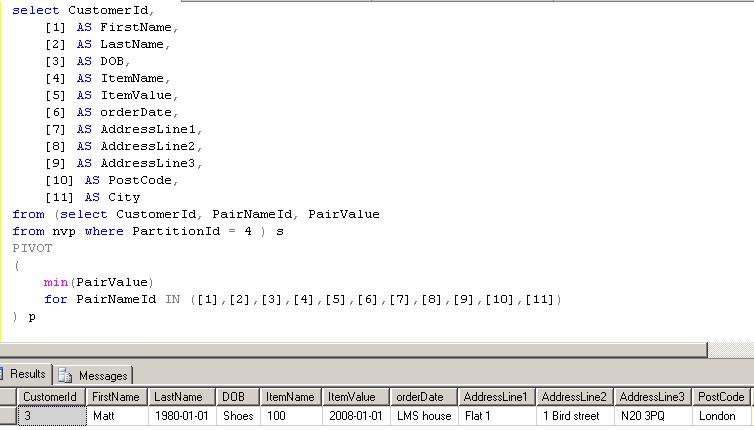
Obviously, you need to do some work on designing an ETL that will transform data. During transformation process you can use the pivot function in SQL server 2005. See listing below of how you would be able to transform a name value pair to load into entity based solution.
5. Business logic
In this scenario I have suggested two possible solutions.
Database is meant to store and retrieve information and to some extent used as business logic but in this design the logic should be transferred to business tier leaving the database to capture information. New business logic need to be written to get customer information in a name value pair format and transform in the business logic so that the results are displayed in a tabular format. Imagine trying to get even one customer information in one row from the database. This has fixed the issues of transforming the data in the database and improved the performance massively.
The other suggestion was to use a Pivot operator to transform the data into a tabular format from within SQL Server. Use this option if you weren't able to win the previous suggested option.
The PIVOT operator is useful in many situations but I am not sure if this is the best place to use. But the option to use it is there. Much of the functionality provided by the PIVOT operator requires you to hard code pairvalueId. (see listing SQL statement below and the result). Pivot is a very useful operator when used for aggregation. But in this situation we only use it to transpose the data which is in a name value format to a tabular format and used a max or min operator of the pairvalue field. The drawback here is we are not actually aggregating any data.
Conclusion
The suggested improvements bought the company some time to re-design a database from ground up.
Database design needs a bit of research and planning. Some of the ideas surrounding database design are great but if you take beyond you might end up with a database that is unusable. In some cases for instance to store configuration settings (setting tables nvp), capturing data of unknown attributes the balance definitely shifts in favour of using it. In terms of storing data of knowing attributes the balance shifts towards using a properly normalised database