

Introduction
The following review covers a function that is the bane of any DBA's life,
that being database synchronization. This particular tool covers all
database DDL, there is another product for data synchronisation that will be
covered in a future review.
Environment
My PC - (where the SW is running) is a P4 1.2,
256Mb RAM, Windows 2000 Pro
The test database I used in all cases has the
following properties: 631 tables (131 triggers and associated audit tables), 152
views, 680 stored procedures, 656 indexes, 23 functions.
The servers used are HP E800 NetServer, 1Gb RAM,
2xRAID-1 15K drives, Dual PIII 800Mhz running Windows 2003 Enterprise Server Ed.
The instance is SQL Server 2k EE SP3a.
Installation
There is nothing technical in the installation, follow the prompts, pick a
folder and that is it. De-installation was error free and complete.
Using AdeptSQL Diff
Test 1 - Compare Databases
Total time: 15 sec average
The product is very quick indeed and first time around I left my desk for
lunch as I do with other products currently on the market. The initial
screens are simple enough, asking you for two connection strings or if its the
same instance, then check a option and select the other database (no double
entering, its simple but this sort of thinking flows through the entire
application - a nice change!). The user is presented with the
following screen after the compare:
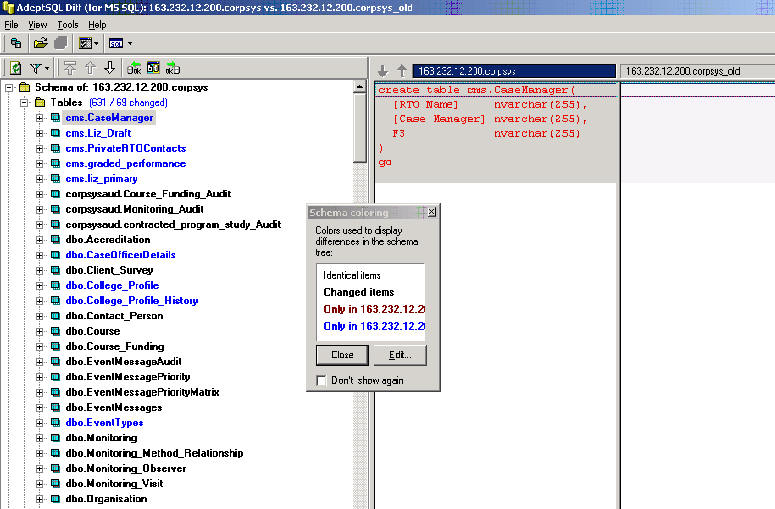
The overall interface takes a while to get used to and I tend to forget the
colour coding, but this is expected with any new software. All items shown
are hooked to pop-ups reminding you of the primary and secondary servers and
what you are actually comparing. I had no issues with the comparison, no
errors or warning or missing objects.
The main screen summarises from the primary server point of view (you
cant switch this around), this is little matter and presents a clean, susinct
view of the database. We are shown a summary of the comparison:
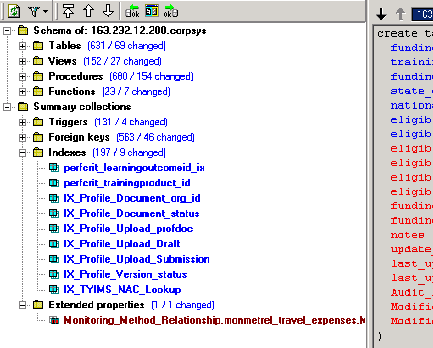
The blue colouring indicates the object is on the primary, but not the
secondary server. The red coloured text (see extended properties) is the
reverse of this. Click the filter button and hide identical objects to
make life easier, especially in my case. Note that the indexes list doesnt
show indexes partaking in constraints, namely primary key indexes. To get this,
drill through at the table level. Double click to refresh the right hand
panel showing the differences, again all colour coded; the information is
presented instantly to the user.
There are a range of editor, compare and schema
options providing a good selection of control over the product and its scripting
options. Some of the nicer options include:
a) eliminate redundant indexes
b) choice of including fill factors,
filegroups, extended properties
c) retrieve all objects (any owner) or we
can filter on specific owners
d) insert statements - can control how
statements are batched, and if column list is always specified
e) turn on/off quoted identifiers, ansi-nulls
f) switch between MS Visual Studio or
Borland Delphi key mappings (nice!)
on changing any of these options the compare
results are quickly refreshed for immediate review.
Test 2 - Sync and Scripting Databases
Scripting is very simple and again lightning fast. In your left panel,
select any part of the tree shown (drill down as required) and push the left or
right buttons with green arrows (left button - script changes to be made on the
primary server and visa versa for the right button). The generation
of my entire secondary server sync script was under 2 seconds, very impressive.
The generated script is shown it a custom different sql script window,
that allows the user to step through, begin/end transactions, skip current
selected statements, bulk comment out code, breakpoints (very handy) etc.
This is somewhat different to other products that generate a complete package of
code with the transactions all built in. As you would think, the script is
full editable:
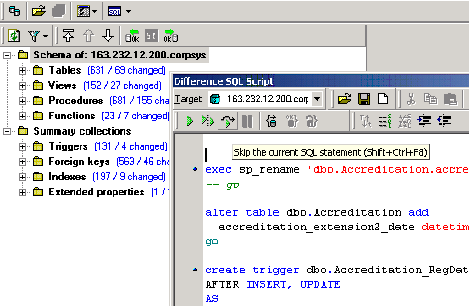
Be very careful in this window, it is easy to make mistakes and with no
explict transactions. I was feeling game so I ran the script presented to
sync my secondary database. Unfortunately, I had errors, the first being
an attempt at dropping a primary key but this was not possible due to other
foreign key references. The script stops, and points you at the statement
that caused the error, I skipped over the error, carried on then hit others
related to this:
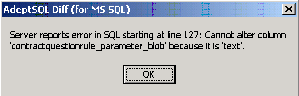
alter
table
dbo.contract_question_rule
alter
column
contractquestionrule_parameter_blob text
go
the error being of course:
I get a little nervous now as I am not sure that skipping statements is
resulting in more issues later on, or simplying skipping items that I actually
want synchronised. I was also presented with errors related to inserts
over identity columns. Overall, I wasnt too impressed with the results of
the script run and skipping around issues left me with a bad taste of "where is
my backup" to get back to square one..
Test 3 - Sync Specific Object Types
A full sync didn't really work for me, so I opted for individual object
types, namely tables then views etc. My first attempt was all tables, the
script generated very quickly, but on running the script I got foreign key
errors related to a table that is actually created later on in the script.
Again, this is not ideal and made life much harder.
Technical Support
Support is via email or via their website feedback form.
Conclusions
Due to its speed, I had early hopes for this product. I have used a
variety of other comparison tools on the market and none compare to AdeptSQL's
raw performance. What let this particular product down though was in the
running of synchronisation scripts. The DBA is after a single script that
takes into consideration foreign keys, object dependencies etc, that can be run
as a single unit of work and be done with it. From my tests to date, the
product had some issues in this area that made synchronisation a painful
experience. That said, the product has huge potential and would definitely
keep an eye on its progress in future versions.
Ratings
| Ease of Use | 4 | A very easy to use product that is simple, quick and accurate on the comparisons. |
| Feature Set | 4 | A good set of options that make sense, simple to understand the see the impact of. |
| Lack of Bugs | 1 | Too many issues with the final scripts, so much so I couldn't use the product to perform a synchronisation. |
| Value | 2 | Unfortunately due to the issues I was presented with in the large scale sync, the value wasnt really there for me. For $240US at the time of this review and v1.09, I would wait a couple more releases and try again. |
| Technical Support | N/A | Did not review |
| Documentation | 2 | A little sparse and not overall comprehensive. Even so, the product is simple enough for the user to cover out all options in under 1hr. |
| Performance | 5 | Super fast comparisons and scripting; the fastest I have seen in relation to similar market products. |
| Installation | 5 | Very simple, quick and error free. It misses an automatic update option over the internet which seems to be a standard facility these days for software. |
| Learning Curve | 4 | No issues here and marries up with documentation. The screens are straight forward and easy to use without loosing too much functionality. |
| Overall | 2 | This product has a lot of potential, it is quick, easy to use and has all the right features. What lets it down? in my opinion the sync scripts need a lot more work as this review has shown. This is critical in very large schemas where syncing needs to be as quick and painless as possible (data issues aside of course). |
Production Information
You can download a 30 day trial of AdeptSQL Diff and Workshop from their
website: http://www.adeptsql.com/. For a change there is no signing up, no logins or emails sent, its simple,
private and well worth a look.
Addendum
From SSC Owners: We usually send the review to the vendor to see
if there are any glaring errors before we publish. In this case we forwarded to
the author, Alex Reatov, and got back some great comments. With his permission,
we are including some of those comments here. Please also note that Alex
indicated that there would a point release of the product around November 10th
that includes both fixes and new features.
In the list of features:
"(a) eliminate redundant indexes"
It would be better to skip this one: nobody (including myself) would tell you
exactly how this feature works and if it really does anything useful. You won't
see it in the new version, and it will take some very thorough thinking before
the feature would reappear in one of the future versions.
"(d) insert statements - can control how statements are batched, and if column
list is always specified"
That was a bug rather than a feature: a leftover from a different product,
AdeptSQL Workshop, which could really produce the INSERTs.
The version being reviewed, Diff 1.09, didn't work with table data, so the
INSERTs option page was completely useless.
In the new 1.50 Beta this option page is being revived, as now it can really be
linked to the SQL generation code of the new DataDiff module.
3) Instant side-by-side comparison of SQL definitions is, I believe, one of the
strong points of AdeptSQL Diff, especially when you need to see differences in
lengthy stored procedures, triggers or views. It _is_ briefly mentioned in the
review, but unfortunately none of the screenshots clearly show this side-by-side
view.
4) Drag-and-drop SQL generation doesn't add much to the functionality, but it is
neat, convenient and, AFAIK, unique among the competing tools.
You can drag-n-drop any selected items from the schema tree to the built-in SQL
editor or to any external editor supporting OLE drag-n-drop (e.g. MS Query
Analyzer). The operation can produce one of 6 different scripts
(CREATE/DROP/ALTER, in either left-to-right or right-to-left direction),
depending on various Ctrl-Alt-Shift combinations.
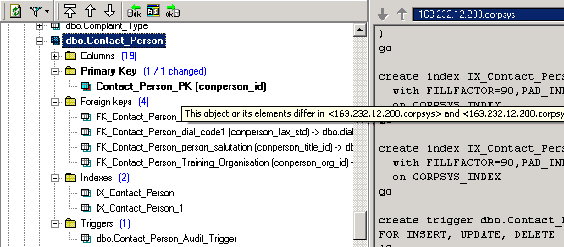
5) Drilling down to constraints:
"Note that the indexes list doesnt show indexes partaking in constraints, namely
primary key indexes. To get this, drill through at the table level."
About this, I just want to ask a question. You can see that certain schema
elements, specifically indexes, triggers and xprops, are shown twice in the
tree: under the table (or other object) where they belong and again under the
"Summary collections" node. It is really easy to do the same thing with table
constraints. Do you think I should do this?
6) The Code Viewer and errors in scripts.
I have to agree with Chris that code generation is the weakest part in the
current version. The program is more suitable for tracking down individual
schema changes than for automatic generation of a complete synchro script. I
tried to compensate for this by providing more powerful editing capabilities and
step-by-step execution commands.
"Be very careful in this window, it is easy to make mistakes and with no explict
transactions."
Well, the scripting window does support transactions (see the toolbar buttons
there). When you start a transaction, the editor also remembers the current
execution point and if you rollback, the execution point also rolls back to its
original location (so you can fix up the script and retry).
In v1.50, there is already an option to put an explicit transaction around any
generated script.
